1、前言 最近項目中用到一個環形緩衝區(ring buffer),代碼是由linux內核的kfifo改過來的。緩衝區在文件系統中經常用到,通過緩衝區緩解cpu讀寫記憶體和讀寫磁碟的速度。例如一個進程A產生數據發給另外一個進程B,進程B需要對進程A傳的數據進行處理並寫入文件,如果B沒有處理完,則A要延遲 ...
1、前言
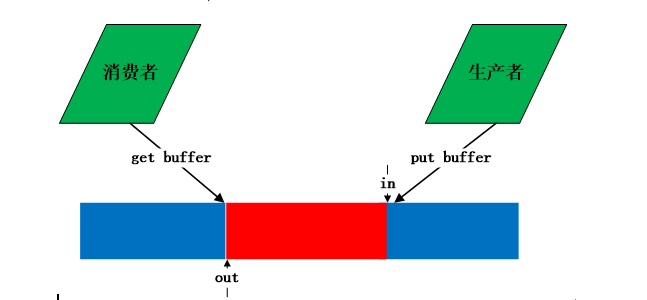
最近項目中用到一個環形緩衝區(ring buffer),代碼是由linux內核的kfifo改過來的。緩衝區在文件系統中經常用到,通過緩衝區緩解cpu讀寫記憶體和讀寫磁碟的速度。例如一個進程A產生數據發給另外一個進程B,進程B需要對進程A傳的數據進行處理並寫入文件,如果B沒有處理完,則A要延遲發送。為了保證進程A減少等待時間,可以在A和B之間採用一個緩衝區,A每次將數據存放在緩衝區中,B每次沖緩衝區中取。這是典型的生產者和消費者模型,緩衝區中數據滿足FIFO特性,因此可以採用隊列進行實現。Linux內核的kfifo正好是一個環形隊列,可以用來當作環形緩衝區。生產者與消費者使用緩衝區如下圖所示:
環形緩衝區的詳細介紹及實現方法可以參考http://en.wikipedia.org/wiki/Circular_buffer,介紹的非常詳細,列舉了實現環形隊列的幾種方法。環形隊列的不便之處在於如何判斷隊列是空還是滿。維基百科上給三種實現方法。
2、linux 內核kfifo
kfifo設計的非常巧妙,代碼很精簡,對於入隊和出對處理的出人意料。首先看一下kfifo的數據結構:
struct kfifo {
unsigned char *buffer; /* the buffer holding the data */
unsigned int size; /* the size of the allocated buffer */
unsigned int in; /* data is added at offset (in % size) */
unsigned int out; /* data is extracted from off. (out % size) */
spinlock_t *lock; /* protects concurrent modifications */
};kfifo提供的方法有:
//根據給定buffer創建一個kfifo
struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size,
gfp_t gfp_mask, spinlock_t *lock);
//給定size分配buffer和kfifo
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask,
spinlock_t *lock);
//釋放kfifo空間
void kfifo_free(struct kfifo *fifo)
//向kfifo中添加數據
unsigned int kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
//從kfifo中取數據
unsigned int kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
//獲取kfifo中有數據的buffer大小
unsigned int kfifo_len(struct kfifo *fifo)定義自旋鎖的目的為了防止多進程/線程併發使用kfifo。因為in和out在每次get和out時,發生改變。初始化和創建kfifo的源代碼如下:
struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size,
gfp_t gfp_mask, spinlock_t *lock)
{
struct kfifo *fifo;
/* size must be a power of 2 */
BUG_ON(!is_power_of_2(size));
fifo = kmalloc(sizeof(struct kfifo), gfp_mask);
if (!fifo)
return ERR_PTR(-ENOMEM);
fifo->buffer = buffer;
fifo->size = size;
fifo->in = fifo->out = 0;
fifo->lock = lock;
return fifo;
}
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
{
unsigned char *buffer;
struct kfifo *ret;
if (!is_power_of_2(size)) {
BUG_ON(size > 0x80000000);
size = roundup_pow_of_two(size);
}
buffer = kmalloc(size, gfp_mask);
if (!buffer)
return ERR_PTR(-ENOMEM);
ret = kfifo_init(buffer, size, gfp_mask, lock);
if (IS_ERR(ret))
kfree(buffer);
return ret;
}在kfifo_init和kfifo_calloc中,kfifo->size的值總是在調用者傳進來的size參數的基礎上向2的冪擴展,這是內核一貫的做法。這樣的好處不言而喻--對kfifo->size取模運算可以轉化為與運算,如:kfifo->in % kfifo->size 可以轉化為 kfifo->in & (kfifo->size – 1)
kfifo的巧妙之處在於in和out定義為無符號類型,在put和get時,in和out都是增加,當達到最大值時,產生溢出,使得從0開始,進行迴圈使用。put和get代碼如下所示:
static inline unsigned int kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
{
unsigned long flags;
unsigned int ret;
spin_lock_irqsave(fifo->lock, flags);
ret = __kfifo_put(fifo, buffer, len);
spin_unlock_irqrestore(fifo->lock, flags);
return ret;
}
static inline unsigned int kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned long flags;
unsigned int ret;
spin_lock_irqsave(fifo->lock, flags);
ret = __kfifo_get(fifo, buffer, len);
//當fifo->in == fifo->out時,buufer為空
if (fifo->in == fifo->out)
fifo->in = fifo->out = 0;
spin_unlock_irqrestore(fifo->lock, flags);
return ret;
}
unsigned int __kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
{
unsigned int l;
//buffer中空的長度
len = min(len, fifo->size - fifo->in + fifo->out);
/*
* Ensure that we sample the fifo->out index -before- we
* start putting bytes into the kfifo.
*/
smp_mb();
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
/*
* Ensure that we add the bytes to the kfifo -before-
* we update the fifo->in index.
*/
smp_wmb();
fifo->in += len; //每次累加,到達最大值後溢出,自動轉為0
return len;
}
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
//有數據的緩衝區的長度
len = min(len, fifo->in - fifo->out);
/*
* Ensure that we sample the fifo->in index -before- we
* start removing bytes from the kfifo.
*/
smp_rmb();
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
/*
* Ensure that we remove the bytes from the kfifo -before-
* we update the fifo->out index.
*/
smp_mb();
fifo->out += len; //每次累加,到達最大值後溢出,自動轉為0
return len;
}put和get在調用__put和__get過程都進行加鎖,防止併發。從代碼中可以看出put和get都調用兩次memcpy,這針對的是邊界條件。例如下圖:藍色表示空閑,紅色表示占用。
(1)空的kfifo,
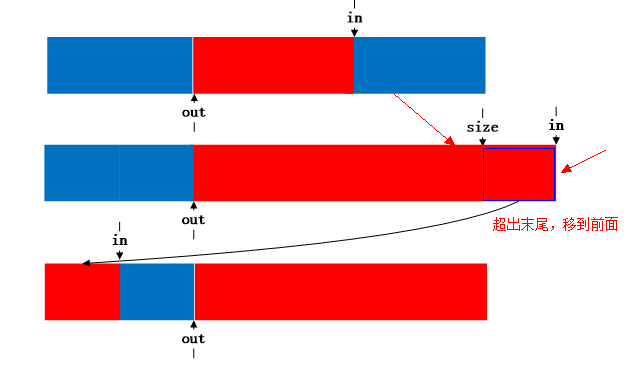
(2)put一個buffer後

(3)get一個buffer後

(4)當此時put的buffer長度超出in到末尾長度時,則將剩下的移到頭部去
3、測試程式
仿照kfifo編寫一個ring_buffer,現有線程互斥量進行併發控制。設計的ring_buffer如下所示:
/**@brief 仿照linux kfifo寫的ring buffer
*@atuher Anker date:2013-12-18
* ring_buffer.h
* */
#ifndef KFIFO_HEADER_H
#define KFIFO_HEADER_H
#include <inttypes.h>
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <assert.h>
//判斷x是否是2的次方
#define is_power_of_2(x) ((x) != 0 && (((x) & ((x) - 1)) == 0))
//取a和b中最小值
#define min(a, b) (((a) < (b)) ? (a) : (b))
struct ring_buffer
{
void *buffer; //緩衝區
uint32_t size; //大小
uint32_t in; //入口位置
uint32_t out; //出口位置
pthread_mutex_t *f_lock; //互斥鎖
};
//初始化緩衝區
struct ring_buffer* ring_buffer_init(void *buffer, uint32_t size, pthread_mutex_t *f_lock)
{
assert(buffer);
struct ring_buffer *ring_buf = NULL;
if (!is_power_of_2(size))
{
fprintf(stderr,"size must be power of 2.\n");
return ring_buf;
}
ring_buf = (struct ring_buffer *)malloc(sizeof(struct ring_buffer));
if (!ring_buf)
{
fprintf(stderr,"Failed to malloc memory,errno:%u,reason:%s",
errno, strerror(errno));
return ring_buf;
}
memset(ring_buf, 0, sizeof(struct ring_buffer));
ring_buf->buffer = buffer;
ring_buf->size = size;
ring_buf->in = 0;
ring_buf->out = 0;
ring_buf->f_lock = f_lock;
return ring_buf;
}
//釋放緩衝區
void ring_buffer_free(struct ring_buffer *ring_buf)
{
if (ring_buf)
{
if (ring_buf->buffer)
{
free(ring_buf->buffer);
ring_buf->buffer = NULL;
}
free(ring_buf);
ring_buf = NULL;
}
}
//緩衝區的長度
uint32_t __ring_buffer_len(const struct ring_buffer *ring_buf)
{
return (ring_buf->in - ring_buf->out);
}
//從緩衝區中取數據
uint32_t __ring_buffer_get(struct ring_buffer *ring_buf, void * buffer, uint32_t size)
{
assert(ring_buf || buffer);
uint32_t len = 0;
size = min(size, ring_buf->in - ring_buf->out);
/* first get the data from fifo->out until the end of the buffer */
len = min(size, ring_buf->size - (ring_buf->out & (ring_buf->size - 1)));
memcpy(buffer, ring_buf->buffer + (ring_buf->out & (ring_buf->size - 1)), len);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + len, ring_buf->buffer, size - len);
ring_buf->out += size;
return size;
}
//向緩衝區中存放數據
uint32_t __ring_buffer_put(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
{
assert(ring_buf || buffer);
uint32_t len = 0;
size = min(size, ring_buf->size - ring_buf->in + ring_buf->out);
/* first put the data starting from fifo->in to buffer end */
len = min(size, ring_buf->size - (ring_buf->in & (ring_buf->size - 1)));
memcpy(ring_buf->buffer + (ring_buf->in & (ring_buf->size - 1)), buffer, len);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(ring_buf->buffer, buffer + len, size - len);
ring_buf->in += size;
return size;
}
uint32_t ring_buffer_len(const struct ring_buffer *ring_buf)
{
uint32_t len = 0;
pthread_mutex_lock(ring_buf->f_lock);
len = __ring_buffer_len(ring_buf);
pthread_mutex_unlock(ring_buf->f_lock);
return len;
}
uint32_t ring_buffer_get(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
{
uint32_t ret;
pthread_mutex_lock(ring_buf->f_lock);
ret = __ring_buffer_get(ring_buf, buffer, size);
//buffer中沒有數據
if (ring_buf->in == ring_buf->out)
ring_buf->in = ring_buf->out = 0;
pthread_mutex_unlock(ring_buf->f_lock);
return ret;
}
uint32_t ring_buffer_put(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
{
uint32_t ret;
pthread_mutex_lock(ring_buf->f_lock);
ret = __ring_buffer_put(ring_buf, buffer, size);
pthread_mutex_unlock(ring_buf->f_lock);
return ret;
}
#endif採用多線程模擬生產者和消費者編寫測試程式,如下所示:
/**@brief ring buffer測試程式,創建兩個線程,一個生產者,一個消費者。
* 生產者每隔1秒向buffer中投入數據,消費者每隔2秒去取數據。
*@atuher Anker date:2013-12-18
* */
#include "ring_buffer.h"
#include <pthread.h>
#include <time.h>
#define BUFFER_SIZE 1024 * 1024
typedef struct student_info
{
uint64_t stu_id;
uint32_t age;
uint32_t score;
}student_info;
void print_student_info(const student_info *stu_info)
{
assert(stu_info);
printf("id:%lu\t",stu_info->stu_id);
printf("age:%u\t",stu_info->age);
printf("score:%u\n",stu_info->score);
}
student_info * get_student_info(time_t timer)
{
student_info *stu_info = (student_info *)malloc(sizeof(student_info));
if (!stu_info)
{
fprintf(stderr, "Failed to malloc memory.\n");
return NULL;
}
srand(timer);
stu_info->stu_id = 10000 + rand() % 9999;
stu_info->age = rand() % 30;
stu_info->score = rand() % 101;
print_student_info(stu_info);
return stu_info;
}
void * consumer_proc(void *arg)
{
struct ring_buffer *ring_buf = (struct ring_buffer *)arg;
student_info stu_info;
while(1)
{
sleep(2);
printf("------------------------------------------\n");
printf("get a student info from ring buffer.\n");
ring_buffer_get(ring_buf, (void *)&stu_info, sizeof(student_info));
printf("ring buffer length: %u\n", ring_buffer_len(ring_buf));
print_student_info(&stu_info);
printf("------------------------------------------\n");
}
return (void *)ring_buf;
}
void * producer_proc(void *arg)
{
time_t cur_time;
struct ring_buffer *ring_buf = (struct ring_buffer *)arg;
while(1)
{
time(&cur_time);
srand(cur_time);
int seed = rand() % 11111;
printf("******************************************\n");
student_info *stu_info = get_student_info(cur_time + seed);
printf("put a student info to ring buffer.\n");
ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
printf("ring buffer length: %u\n", ring_buffer_len(ring_buf));
printf("******************************************\n");
sleep(1);
}
return (void *)ring_buf;
}
int consumer_thread(void *arg)
{
int err;
pthread_t tid;
err = pthread_create(&tid, NULL, consumer_proc, arg);
if (err != 0)
{
fprintf(stderr, "Failed to create consumer thread.errno:%u, reason:%s\n",
errno, strerror(errno));
return -1;
}
return tid;
}
int producer_thread(void *arg)
{
int err;
pthread_t tid;
err = pthread_create(&tid, NULL, producer_proc, arg);
if (err != 0)
{
fprintf(stderr, "Failed to create consumer thread.errno:%u, reason:%s\n",
errno, strerror(errno));
return -1;
}
return tid;
}
int main()
{
void * buffer = NULL;
uint32_t size = 0;
struct ring_buffer *ring_buf = NULL;
pthread_t consume_pid, produce_pid;
pthread_mutex_t *f_lock = (pthread_mutex_t *)malloc(sizeof(pthread_mutex_t));
if (pthread_mutex_init(f_lock, NULL) != 0)
{
fprintf(stderr, "Failed init mutex,errno:%u,reason:%s\n",
errno, strerror(errno));
return -1;
}
buffer = (void *)malloc(BUFFER_SIZE);
if (!buffer)
{
fprintf(stderr, "Failed to malloc memory.\n");
return -1;
}
size = BUFFER_SIZE;
ring_buf = ring_buffer_init(buffer, size, f_lock);
if (!ring_buf)
{
fprintf(stderr, "Failed to init ring buffer.\n");
return -1;
}
#if 0
student_info *stu_info = get_student_info(638946124);
ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
stu_info = get_student_info(976686464);
ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
ring_buffer_get(ring_buf, (void *)stu_info, sizeof(student_info));
print_student_info(stu_info);
#endif
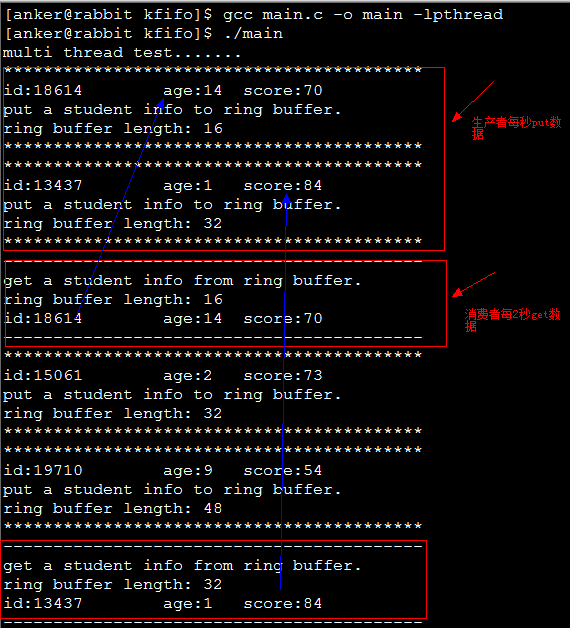
printf("multi thread test.......\n");
produce_pid = producer_thread((void*)ring_buf);
consume_pid = consumer_thread((void*)ring_buf);
pthread_join(produce_pid, NULL);
pthread_join(consume_pid, NULL);
ring_buffer_free(ring_buf);
free(f_lock);
return 0;
}測試結果如下所示: