
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》 (本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除) 10) --MySQL為什麼有時會選錯索引? MySQL中的一張表上可以支持多個索引的,但是,往往你寫SQL語句的時候不會去主動指定使用哪個索引。也就是說,使用哪個索引是由MySQL來 ...
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》
(本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除)
10) --MySQL為什麼有時會選錯索引?
MySQL中的一張表上可以支持多個索引的,但是,往往你寫SQL語句的時候不會去主動指定使用哪個索引。也就是說,使用哪個索引是由MySQL來確定的。而MySQL有時會選擇不恰當的索引,我們舉一個例子來說明這種情況。
CREATE TABLE `t` ( `id` int(11) NOT NULL, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `a` (`a`), KEY `b` (`b`) ) ENGINE=InnoDB;
然後向表中插入10萬行記錄,取值按整數遞增,即(1,1,1),(2,2,2),(3,3,3)直到(100000,100000,100000)。我們來分析一條SQL語句:
mysql> select * from t where a between 10000 and 20000;
這條語句很簡單,想必你也想到了這條語句會使用索引a,事實上也確實使用了索引a。不過別急,這個例子沒有這麼簡單,我們繼續來看:

其中 call idata()是執行mysql的存儲過程,用來插入數據。需要註意的是,這裡Session B就不會再使用索引a了。為了對比結果,可以使用force index(a)來讓優化器強制使用索引a,下麵三條語句就是實驗過程:
set long_query_time=0; select * from t where a between 10000 and 20000; /*Q1*/ select * from t force index(a) where a between 10000 and 20000;/*Q2*/
- 首先把慢查詢日誌的閾值設為0,表示這個線程接下來的語句都會進入慢查詢日誌中。
- Q1是session B原來的查詢;
- Q2是seesion B 強制使用索引a的查詢。
對比結果如下:
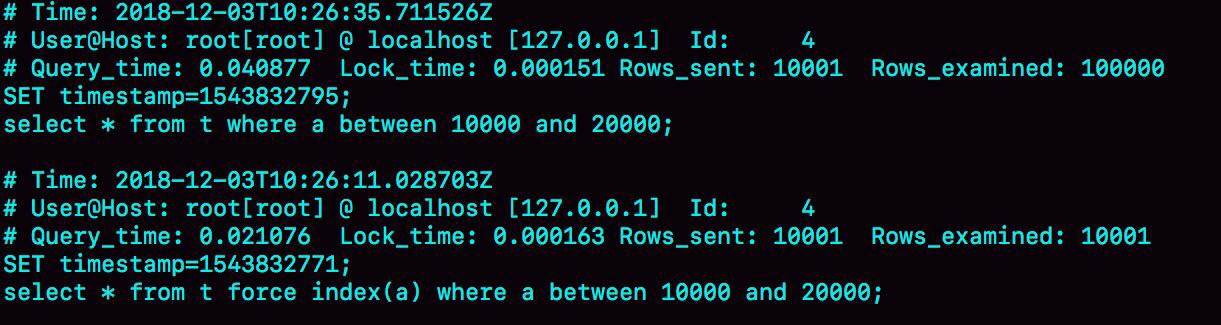
很容易看出第一行查詢了10w行,並沒有利用到索引a。為什麼會這樣的,我們從優化器的邏輯談起
優化器的邏輯:
優化器選擇索引的目的,是找到一個最優的執行方案,並用最小的代價去執行語句。在資料庫中,掃描行數是影響執行代價的因素之一。我們的優化器就是在判斷掃描行數的時候出了問題。那麼問題就是,掃描行數是怎麼判斷的呢?而在真正的執行語句之前,並不能精確地知道滿足這個條件的記錄有多少條。而只能根據統計信息來進行估算。這個統計信息就是索引的“區分度”。顯然,一個索引上不同的值越多,這個索引的區分度就越好,而一個索引上不同值的個數,我們也稱之為“基數”(cardinlity)。MySQL是通過採樣統計的方式來獲得區分度的,統計時時會選擇N個數據頁來統計。因此這個值是不精確的,當數據表持續變化時,當變更的數據行數超過1/M的時候,會自動觸發重新做一次統計。在MySQL中有兩種存儲索引統計的方式,可以通過參數innodb_stats_persistent的值來進行選擇 。
- 設置為on的時候,表示統計信息會持久化存儲,預設的M是10,N是20
- 設置為off的時候,表示統計信息值存儲在記憶體中,此時,預設的M是16,N是8.
MySQL選擇錯誤的索引就是因為這個統計信息不准造成的。你可以通過analyze table t命令來進行修正 。
索引的選擇異常和處理:
其實大多數時候MySQL的優化器都會選擇到正確的索引,但一旦真的發生這種情況,你可以有別的方式來修正。一是剛纔提到的,使用force index強行選擇一個索引。一旦使用了force index命令,優化器就不會再去評估其他的索引了。但這個方式一來代碼不夠優雅,二來一旦有索引的改動還需再額外修改代碼。第二種方式呢,可以考慮修改語句,引導MySQL使用我們期望的索引。例如在order by相關的語句中,適當調整order by後面跟的條件,可以引導優化器找到正確的索引。三是,在某些場景下,我們可以新建一個更合適的索引。
上期問題:
change buffer一開始是寫記憶體的,那麼如果這個時候及其掉電重啟,會不會導致change buffer丟失呢?change buffer丟失可不是小事,因為丟失以後就無法再進行merge了,等於是數據丟失了,會不會出現這種情況呢?
答案是不會丟失,雖然只是更新記憶體,但在事務提交的時候,我們把change buffer的操作也記錄到redo log裡面去了,所以崩潰的時候change buffer也能找回來。
問題:
本篇前面的例子中,如果沒有session A的配合,只是單獨執行 delete from t; call idata(); explain這三條語句,會看到explain結果中rows欄位其實還是再10000左右,即使用了索引,這是為什麼呢?

