
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》 (本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除) 8.a) --事務到底是隔離還是不隔離的? 本周工作較忙,加上懶惰,拖更了,抱歉。 接上文,分析下事務A的返回結果,為什麼k=1.這裡我們做如下假設: 這樣,事務A的視圖數組就是[99 ...
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》
(本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除)
8.a) --事務到底是隔離還是不隔離的?
本周工作較忙,加上懶惰,拖更了,抱歉。
接上文,分析下事務A的返回結果,為什麼k=1.這裡我們做如下假設:
- 事務A開始前,系統裡面只有一個活躍事務,其ID是99
- 事務A,B, C的版本號分別是100,101,102,且當前系統裡面只有四個事務。
- 三個事務開始前,(1,1)這一行數據的row trx_id是90
這樣,事務A的視圖數組就是[99,100],事務B的視圖數組是[99,100,101],事務C的視圖數組是[99,100,101,102]。為了簡化分析,先把其他的干擾語句去掉,只畫出事務A查詢邏輯有關的操作。
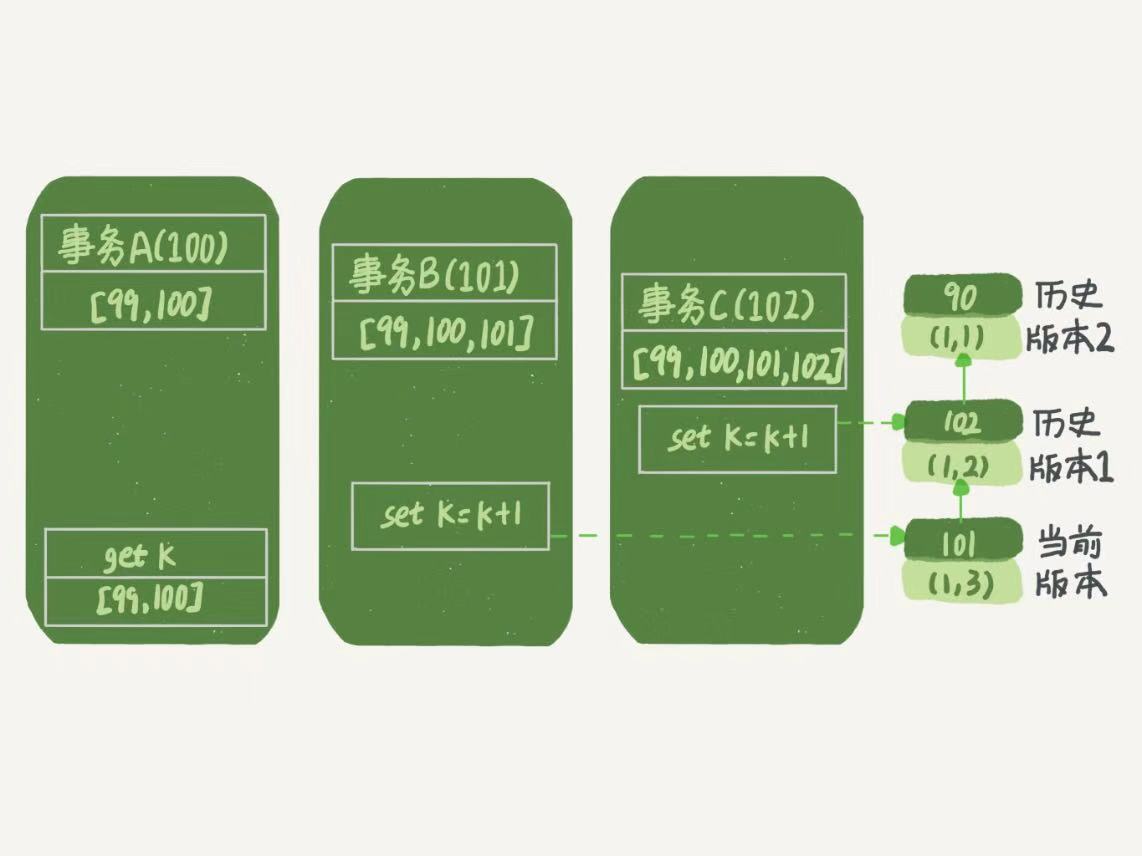
圖4,事務A查詢數據邏輯圖
從圖中可以看到,第一個有效更新的是事務C,把數據從(1,1)更新成了(1,2)。這個時候,這個數據的最新版本的row trx_id是102,而90這個版本已經成為了歷史版本。第二個有效更新的事務是B,把數據從(1,2)改成了(1,3)。這時候,這個數據的最新版本(即row trx_id)是101,而102又成為了歷史版本。你可能已經註意到了,在事務A查詢的時候,其實事務B還沒有提及,但是它生成的(1,3)這個版本的記錄已經成為了當前版本了。但這個版本對事務A必須是不可見的,否則就變成臟讀了。
現在事務A要來讀數據了,它的視圖數組是[99,100].當然,讀數據都是從當前版本讀起的。所以,事務A查詢語句的數據流程是這樣的:
- 找到(1,3)的時候,判斷出row trx_id = 101,比高水位大,在紅色區域,不可見。
- 找到上一個歷史版本,row trx_id = 102,比高水位大,處於紅色區域,不可見。
- 接著查找上一個歷史版本,row trx_id = 90,比低水位小,處於綠色區域,可見。
這樣,雖然期間這一行數據被修改過,事務A不論在什麼時候查詢,看到的這個行數據的結果都是一致的,即一致性讀。以上判斷流程是從代碼邏輯轉譯過來的,如你所見,用於人肉分析很麻煩。另一種較好理解的說法是,對於一個數據版本,一個事務視圖來說,除了自己的更新總是可見外,有三種情況。
- 版本未提交,不可見。
- 版本已提交,但是是在視圖創建後提交的,不可見。
- 版本已提交,且是在視圖創建前提交的,可見。
現在我們再來看一下圖4中的查詢結果,事務A的查詢語句的視圖數組是在事務A啟動的時候生成的,此時:
- (1,3)未提交,不可見。
- (1,2)已提交,但是是在視圖數組創建之後提交的,不可見。
- (1,1)是在視圖創建前提交的,可見。
更新邏輯:
你可能有個疑問,事務B的update語句,如果按照一致性讀,結果不對呀?如圖5所示,事務B的視圖數組是先生成的,之後事務C才提交,不是應該看不見(1,2)嗎,怎麼能算出(1,3)來?
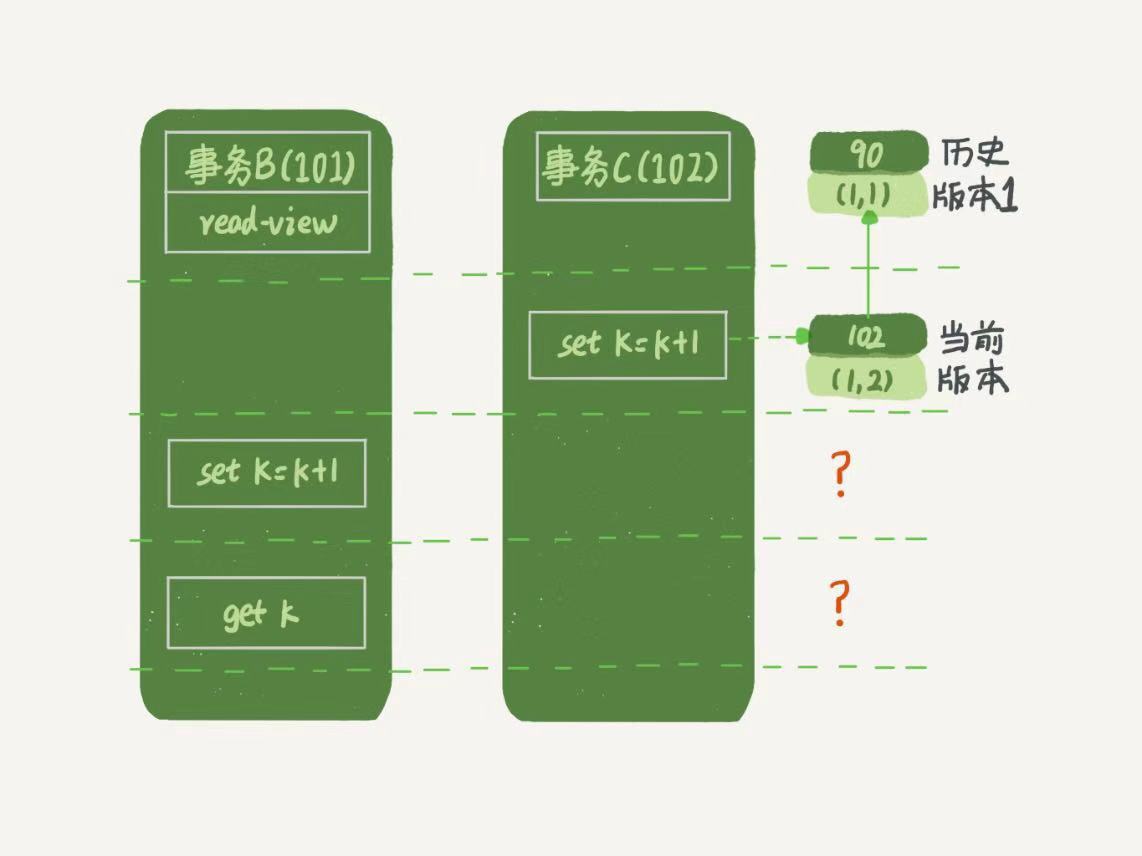
圖5,事務B的更新邏輯
是的,如果事務B在更新操作之前先查詢一下,返回的k的值確實是1.但是,當它要更新數據的時候,就不能再歷史版本上更新了,否則事務C的更新就丟失了。因此,事務B此時的set k=k+1是在(1,2)的基礎上進行的操作。這裡用到了這樣一條規則:更新數據都是先讀後寫,而這個讀,只能讀當前的值,稱為“當前讀”(current read). 因此,在更新的時候,當前讀拿到的數據是(1,2),更新後生成了新版本的數據(1,3),這個心版本的row trx_id是101.所以,在執行事務B查詢語句的時候,一看自己的版本號是101,最新數據的版本號也是101,是自己更新的,可以直接使用,所以查詢得到的k的值是3。這裡我們提到了一個概念,叫作當前讀。其實,除了update語句外,select語句如果加鎖,也是當前讀. 所以,如果把事務A的查詢語句select * from t where id = 1修改一下,加上lock in share model或for update,也都是可以讀到版本號是101的數據,返回k的值是3.下麵中兩個select語句,就是分別加了讀書(s鎖,共用鎖)和寫鎖(x鎖,排它鎖)。
mysql > select k from t where id = 1 lock in share mode; mysql > select k from t where id = 1 for update;
再往前一步,假設事務C不是馬上提交的,而是變成了下麵的事務C,會怎樣呢?

圖6,事務A,B,C'的執行流程。
事務C'不同的是,更新後沒有馬上進行提交,在它提交之前,事務B的更新語句先發起了。前面說過了,雖然事務C'還沒提交,但是(1,2)這個版本也已經生成了,並且是當前的最新版本,那麼事務B的更新語句會如何處理呢?這個時候就用到我們之前提過的“兩階段鎖協議”了。事務C'沒提交,也就是(1,2)這個版本上的寫鎖還沒釋放。而事務B是當前讀,必須要讀最新版本,而且必須加鎖,因此就被鎖住了,必須等到事務C'釋放這個鎖,才能繼續它的當前讀。
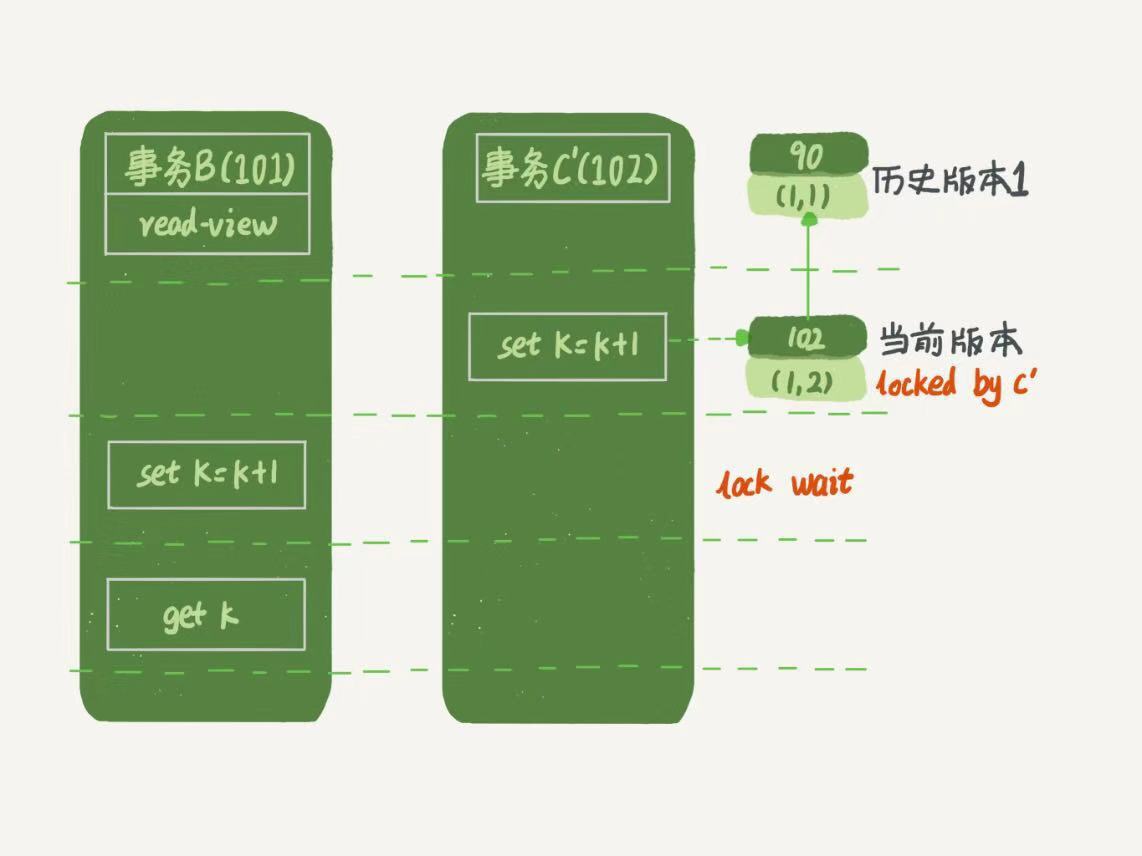
圖7,事務B更新邏輯圖(配合事務C')
至此,我們把一致性讀,當前讀和行鎖就串起來了。現在我們回到開頭的問題,事務的可重覆讀能力是怎麼實現的呢?可重覆讀的核心就是一致性讀(consistent read);而事務更新數據的時候,只能用當前讀。如果當前的記錄的行鎖被其他事務占用的話,就需要進入鎖等待。而讀提交的羅輯和可重覆讀的羅輯類似,它們最主要的區別在於:
- 在可重覆讀隔離級別下,只需要在事務開始的時候創建一致性視圖,之後事務里的其他查詢都公用這個一致性視圖
- 在讀提交隔離級別下,每一個語句執行前都會重新算出一個新的視圖。
小結:
InnoDB的行數據有多個版本,每個數據版本有自己的row trx_id,每個事務或者語句有自己的一致性視圖,普通的查詢語句是一致性讀,一致性讀會根據row trx_id和一致性視圖確定數據版本的可見性。
- 對於可重覆讀,查詢只承認在事務啟動前就已經提交完成的數據。
- 對於讀提交,查詢只承認在語句啟動前就已經提交完成的數據。
而當前讀,總是讀取已經提交完成的最新版本。
上期問題:
如果你要刪除一個表裡面的10000行數據,有以下三種方式:
- 直接執行 delete from T limit 10000;
- 在一個連接中迴圈執行20次delete from T limit 500;
- 在20個連接中同時執行delete from T limilt 500;
你會選擇哪種方式,為什麼呢?
第二種方式相對較好一些。第一種方式裡面,單個語句占用時間長,鎖的時間也長,而且大事務還會導致主從延遲。第三種方式會人為造成鎖衝突。
問題:
我用下麵的表結構和初始化語句作為實驗環境,事務隔離級別是可重覆讀。現在,我要把”所有欄位c和id值相等”的行的c值清0,但是發現了一個“詭異”的,改不掉的情況。請你構造出這種情況,並說明原理。復現出來以後嗎,請你再思考一下,在實際的業務開發中有沒有可能碰到這個情況?你的應用代碼是會不會掉進這個“坑”里,你又是如何解決的呢?
mysql> CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; insert into t(id, c) values(1,1),(2,2),(3,3),(4,4);



