
Group By Group By 誰不會啊?這不是最簡單的嗎?越是簡單的東西,我們越會忽略掉他,因為我們不願意再去深入瞭解它。 "1 小時 SQL 極速入門(一)" "1 小時 SQL 極速入門(二)" "1 小時 SQL 極速入門(三)——Oracle 分析函數" "SQL 高級查詢——(層次化 ...
Group By
Group By 誰不會啊?這不是最簡單的嗎?越是簡單的東西,我們越會忽略掉他,因為我們不願意再去深入瞭解它。
1 小時 SQL 極速入門(一)
1 小時 SQL 極速入門(二)
1 小時 SQL 極速入門(三)——Oracle 分析函數
SQL 高級查詢——(層次化查詢,遞歸)
今天就帶大家瞭解一下Group By 的新用法吧。
ROLL UP
ROLL UP 搭配 GROUP BY 使用,可以為每一個分組返回一個小計行,為所有分組返回一個總計行。
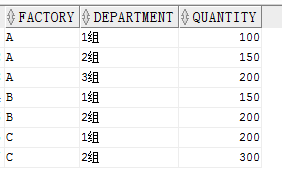
直接看例子,我們有以下數據表,包含工廠列,班組列,數量列三列。
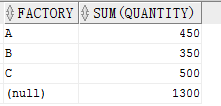
當向 ROLLUP 傳入一列時,會得到一個總計行。
SELECT factory,
SUM(quantity)
FROM production
GROUP BY ROLLUP(factory)
ORDER BY factory
結果:
當向 ROLLUP 傳遞兩列時,將會按照這兩列進行分組,同時按照第一列的分組結果返回小計行。我們同時傳入工廠和部門看一下。
SELECT factory,department,
SUM(quantity)
FROM production
GROUP BY ROLLUP(factory, department)
ORDER BY factory
結果:
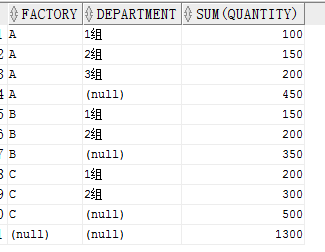
可以看到對每一個工廠都有一個小計行,最後對所有的有一個總計行。也可以這樣理解
如果 ROLLUP(A,B)則先對 A,B進行 GROUP BY,之後對 A 進行 GROUP BY,最後對全表 GROUP BY。
如果 ROLLUP(A,B,C)則先對 A,B,C進行 GROUP BY ,然後對 A,B進行GROUP BY,再對 A 進行GROUP BY,最後對全表進行 GROUP BY.
CUBE
CUBE 和 ROLLUP 對參數的處理是不同的,我們可以這樣理解。
如果 CUBE(A,B)則先對 A,B 進行 GROUP BY,之後對 A 進行 GROUP BY,然後對 B 進行 GROUP BY,最後對全表進行 GROUP BY.
如果 CUBE(A,B,C)則先對 A,B,C 進行 GROUP BY,之後對 A,B ,之後對A,C ,之後對 B,C 之後對 A,之後對 B,之後對 C,最後對全表GROUP BY
看一個簡單的例子:
SELECT factory,department,
SUM(quantity)
FROM production
GROUP BY CUBE(factory, department)
ORDER BY factory,department;
結果:
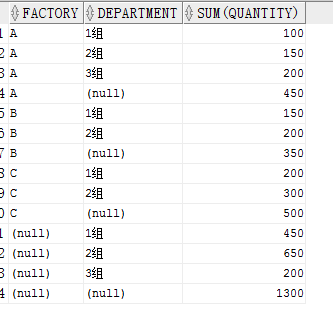
可以看出來首先對 FACTORY,DEPARTMENT進行分組彙總,然後對FACTORY 分組彙總,之後對 DEPARTMENT 分組彙總,最後有一行全表彙總。
GROUPING
GROUPING()函數只能配合 ROLLUP 和 CUBE 使用,GROUPING()接收一列,如果此列不為空則返回0,如果為空則返回1.
我們用第一個ROLLUP例子舉例
SELECT GROUPING(factory),
factory,
department,
SUM(quantity)
FROM production
GROUP BY ROLLUP(factory, department)
ORDER BY factory,
department;
結果:
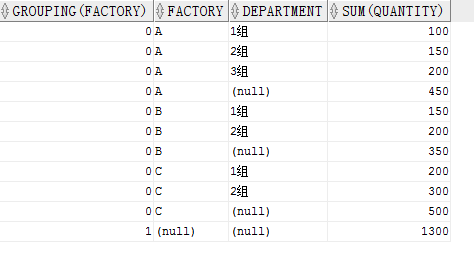
看到,最後一行的 FACTORY 為空,所以 GROUPING()返回 1.也可以與CUBE結合使用,方法是一樣的。
GROUPING SETS
GROUPING SETS 與 CUBE 有點類似,CUBE是對參數進行自由組合進行分組。GROUPING SETS則對每個參數分別進行分組,GROUPING SETS(A,B)就代表先按照 A 分組,再按照 B分組。
SELECT factory,
department,
SUM(quantity)
FROM production
GROUP BY GROUPING SETS(factory, department)
ORDER BY factory,
department
結果:
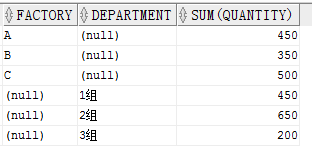
可以看出來結果是按照工廠和部門分別分組彙總的。
GROUPING_ID()
GROUPING_ID()配合GROUPING()函數使用,GROUPING_ID(A,B)的值由GROUPING(A)與GROUPING(B)的值決定,如果GROUPING(A)為1,GROUPING(B)為0,則GROUPING_ID(A,B)的值為 10,十進位的 3.
SELECT factory,
department,
GROUPING(factory),
GROUPING(department),
GROUPING_ID(factory,department),
SUM(quantity)
FROM production
GROUP BY CUBE(factory, department)
ORDER BY factory,
department;
結果:

有了GROUPING_ID列,我們就可以使用 HAVING 字句來對查詢結果進行過濾。選擇GROUPING_ID=0的就表示 FACTORY,DEPARTMENT兩列都不為空。

