
抓取智聯招聘和百度搜索的數據併進行分析,使用visual studio編寫代碼mongodb和SQLServer存儲數據。使用scrapy框架結合 selenium爬取百度搜索數據,併進行簡要的數據的分析!! 爬取前的頁面分析: 打開百度搜索頁面,並查看網頁源代碼,問題便出現,無法查看到頁面源代碼, ...
抓取智聯招聘和百度搜索的數據併進行分析,使用visual studio編寫代碼mongodb和SQLServer存儲數據。使用scrapy框架結合 selenium爬取百度搜索數據,併進行簡要的數據的分析!!
爬取前的頁面分析:
打開百度搜索頁面,並查看網頁源代碼,問題便出現,無法查看到頁面源代碼,如下,只是返回一個狀態說明,這時可以確定頁面數據是動態生成,常規的爬取行不通。

在瀏覽器中進行調試分析,可以發現需要定位使用的html元素,通過這一步至少可以將以下兩個元素的XPATH或CSS Selector的表達式求解出來。
制定爬取方案
既然搜索頁面的內容是動態生成,常規的http請求後無法獲取數據,針對這種問題的解決方法:
l 通過抓包工具,進行對http請求進行分析,找到實際數據請求的js代碼後進行模擬請求獲取數據,這種方法耗時耗力,且是無法適應頁面更改的情況。
l 通過瀏覽器框架請求,並編寫程式和瀏覽器通信獲取數據分析,對於這種方法的選擇有很多,如在windows上可以使用IE Browser控制項,其他的可以使用其他內核的瀏覽器,這種方法的缺點是速度較慢。
l 這裡選取的方法是使用 Selenium + Phantomjs的方法,這個結合scrapy也算是較為經典的一種方法。並且 Selenium + Phantomjs 也是作為Web應用程式進行自動化測試的一套方案。
l Selenium : Selenium 是一個用於Web應用程式測試的工具,可以搭配主流瀏覽器進行使用,如 IE ,Chrome ,Firefox等
l Phantomjs: 一個基於webkit內核的無頭瀏覽器,即沒有UI界面,即它就是一個瀏覽器,只是其內的點擊、翻頁等人為相關操作需要程式設計實現。
編寫爬蟲代碼
開始實際編寫代碼前,對爬取步驟的梳理。
自動填寫搜索關鍵字 – 自動觸發搜索功能 – 抓取頁面搜索數據(不包含廣告推廣項) – 分頁跳轉 …..

輸入關鍵字併進行查找,對關鍵字“IT教育”進行搜索
對第一頁右邊欄的“相關機構”(如下圖)進行抓取(首先需要觸發“展開”事件)

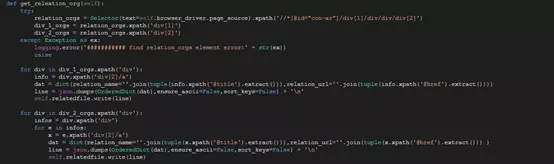
在開啟爬蟲,進行爬取數據的,爬取結果如下:
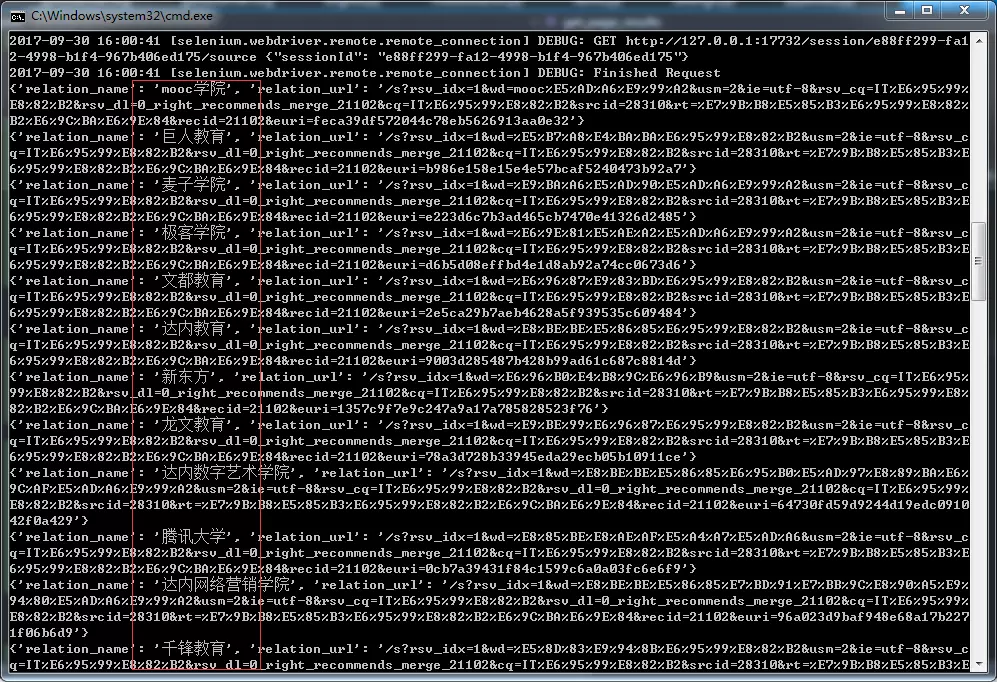
分析數據 經過抓取,共抓取了76頁,抓取的數據如下: Json文件 [[圖片上傳中 在SQLServer資料庫中。
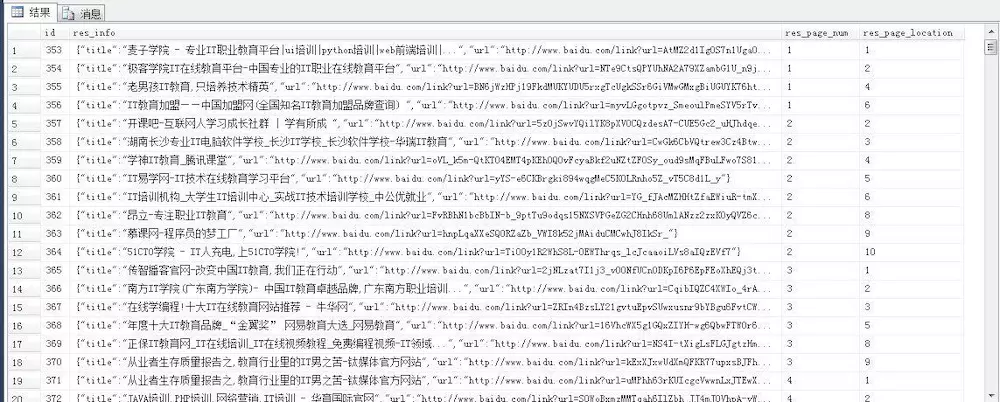
對抓取數據進行關鍵字提取,並製作對應的標簽雲,得到的標簽雲圖為.分析工具為python,通過jieba分詞和pycloundtag兩個模塊進行,得到的分析結果如下:

分析搜索“IT教育”得到結果得出的初步結論,出現次數較多:
n 城市: 北京 深圳 杭州 武漢 長沙 等
n 機構: 北大青鳥 達內 傳智播客 等
n 語言: java php html5 等
github: https://github.com/Shadow-Hunter-X/Crawl-Recruit-Data

