
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》 8.a) --事務到底是隔離還是不隔離的? 這部分內容不太容易理解,筆者也是進行了多次閱讀。因此引用原文: 之前有提到過,如果是在可重覆讀隔離級別,事務T啟動的時候會創建一個視圖read-view,之後事務T執行期間,即使有其他事務修改了數據, ...
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》
8.a) --事務到底是隔離還是不隔離的?
這部分內容不太容易理解,筆者也是進行了多次閱讀。因此引用原文:
之前有提到過,如果是在可重覆讀隔離級別,事務T啟動的時候會創建一個視圖read-view,之後事務T執行期間,即使有其他事務修改了數據,事務T看到的仍然跟在啟動時看到的一樣,也就是說,一個在可重覆讀隔離級別下執行的事務,好像與世無爭,不受外界影響。
但是,在之前也行鎖相關內容時又提到,一個事務要更新一行,如果剛好有另外一個事務擁有這一行的行鎖,它又不能這麼超然了,會被鎖住,進入等待狀態。問題是,既然進入了等待狀態,那麼等到事務自己獲取到行鎖要更新數據的時候,它讀到的值又是什麼呢?
舉一個例子,下麵是一個只有兩行的表的初始化語句。
mysql> CREATE TABLE `t` ( `id` int(11) NOT NULL, `k` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; insert into t(id, k) values(1,1),(2,2);

圖一, 事務A, B, C的執行流程
這裡我們需要註意的是事務的啟動時機。
begin/start transaction命令並不是一個事務的起點,在執行到它們之後的第一個操作InnoDB表的語句,事務才真正啟動。如果你想要馬上啟動一個事務,可以使用start transaction with consistent snapshot命令。
- 第一種啟動方式,一致性視圖是在執行第一個快照讀語句時創建的。
- 第二種啟動方式,一致性視圖是在執行start transaction with consistent snapshot時創建的。
還需要註意,沒有特殊說明的情況下,我們預設autocommit=1.
在上面這個例子中,事務C沒有顯示的使用begin/commit,表示這個update語句本身就是一個事務,語句完成時會自動提交。事務B在更新了行之後查詢;事務A在一個只讀事務中查詢,並且時間順序上是在事務B的查詢之後。這時候,如果告訴你事務B查詢到的K值是3,而事務A查到的k的值是1,你是不是感覺有點暈呢?
所以今天這篇文章就是想和你說明這個問題。在MySQL里有兩個視圖概念:
- 一個是view,它是一個用查詢語句定義的虛擬表,在調用的時候執行查詢語句並生成結果。創建視圖的語法是create view...,而它的查詢方法與表一樣。
- 另一個是InnoDB在實現MVCC時用到的一致性視圖,即consistent read view,用於支持RC(Read Commited 讀提交)和RR(Repeatable Read,可重覆讀)隔離級別的實現。
它沒有物理結構,作用是事務執行期間用來定義“我能看到什麼數據”.
“快照”在MVCC里是怎麼工作的?
在可重覆讀的隔離級別下,事務在啟動的時候就“拍了個快照”,註意,這個快照是基於整個資料庫的。這時,你可能覺得這不太現實,畢竟如果一個庫有100G,那麼我啟動一個事務,MySQL就要拷貝100G的數據,這個過程得多慢啊。可是平常執行事務卻很快。實際上,並不需要拷貝這100G的數據。我們先來看看這個快照是怎麼實現的。
InnoDB裡面每個事務有一個唯一的事務ID,叫做transaction id。它是在事務開始的時候向InnoDB的事務系統申請的,是按申請順序嚴格遞增的。
而且,每行數據也是有多個版本的,每次事務更新的時候,都會生成一個新的數據版本,並且把transaction id 賦值給這個數據版本的事務ID,記為row trx_id。同時,舊的數據版本要保留,並且在新的數據版本中,能夠有信息可以直接拿到它。也就是說,數據表中的每一行記錄,其實可能有多個版本(row),每個版本有自己的row trx_id。
如圖2所示,就是一個記錄被多個事務連續更新後的狀態。
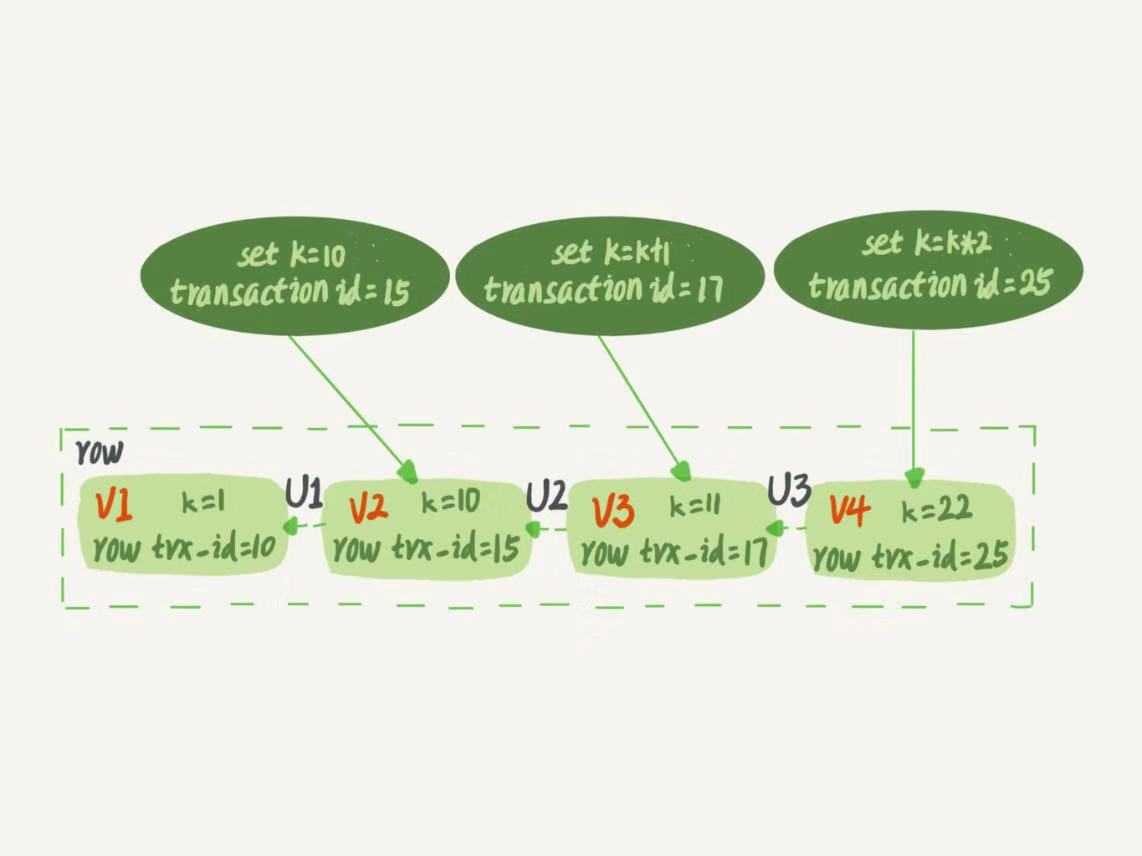
圖2 行狀態變更圖
圖中虛線框里是同一行數據的4個版本,當前最新版本是V4,k的值是22,它是被transaction id為25的事務更新的,因此它的row trx_id也是25.你可能會問,前面的文章不是說,語句更新會生成undo log(回滾日誌)嗎?那麼,undo log在哪兒呢?實際上,圖2中的三個虛線箭頭,就是undo log;而V1,V2,V3並不是物理上真實存在的,而是每次需要的時候根據當前版本和undo log計算出來的。比如,需要V2的時候,就是通過V4依次執行U3,U2算出來。明白了多版本和row trx_id的概念後,我們再來想一下,InnoDB是怎麼定義那個“100G”的快照的。按照可重覆讀的定義,一個事務啟動的時候,能夠看見所有已經提交的事務結果。但是之後,這個事務執行期間,其他事務的更新對它不可見。
因此,一個事務只需要在啟動的時候聲明說,“以我啟動的時刻為準,如果一個數據版本在我啟動之前生成,就認;否則就不認。必須要找到它的上一個版本。當然,如果‘上一個版本’也不可見,那就得繼續往前找”。除此之外,如果這個事務自己更新的數據,它自己還是要認的。在實現上,InnoDB為每個事務構造了一個數組,用來保存這個事務啟動瞬間,當前正在“活躍”的所有事務ID。“活躍”指的就是,啟動了但還沒提交。數組裡面事務ID的最小值記為低水位,當前系統裡面已經創建過的事務ID的最大值加1記為搞水位。這個視圖數組和高水位,就組成了當前事務的一致性視圖(read-view)。而數據版本的可見性規則,就是基於數據的row trx_id和這個一致性視圖的對比結果得到的。這個視圖數組把所有的 row trx_id分成了幾種不同的情況。

圖3, 數據版本可見性規則
這樣,對於當期事務的啟動瞬間來說,一個數據版本的row trx_id,有以下幾種可能:
- 如果落在綠色部分,表示這個版本是已提交的事務或者是當期事務自己生成的,這個數據是可見的。
- 如果落在紅色部分,表示這個版本是由將來啟動的事務生成的,是肯定不可見的。
- 如果落在黃色部分,那就包括兩種情況。a. 若row trx_id 在數組中,表示這個版本是由還沒提交的事務生成的,不可見。b.若 row trx_id不在數組中,表示這個版本是已經提交了的事務生成的,可見。
所以你現在知道了,InnoDB利用了“所有數據都有多個版本”的這個特性,實現了“秒級創建快照”的能力。接下來我們回顧一下圖1中的三個事務,分析事務A的語句返回的結果,為什麼是k=1.
未完待續.....


