
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》 3) --事務隔離,為什麼你改了我還看不見? 簡單來說,事務就是要保證一組數據操作,要麼全部成功,要麼全部失敗。在MySQL中,事務支持是在引擎層實現的。但並不是所有的引擎都支持事務,這也是MyISAM被InnoDB取代的重要原因之一。 本篇內 ...
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》
3) --事務隔離,為什麼你改了我還看不見?
簡單來說,事務就是要保證一組數據操作,要麼全部成功,要麼全部失敗。在MySQL中,事務支持是在引擎層實現的。但並不是所有的引擎都支持事務,這也是MyISAM被InnoDB取代的重要原因之一。
本篇內容均是在InnoDB下討論。
提到事務,總免不了ACID(Atomicity,Consistency,Isolation,Durability),(原子性,一致性,隔離性,持久性),本篇主要討論的是隔離性。
隔離性在MySQL中是分為不同的隔離級別的。包括 讀未提交(read uncommitted),讀提交(read commited),可重覆讀(repeatable read)(MySQL預設隔離級別),串列化(serializable)。隔離性依次增強。
- 讀未提交: 一個事務還沒提交時,它所做的變更就能被別的事務看到。
- 讀提交: 一個事務提交之後,它所做的變更才能被別的事務看到。
- 可重覆讀:一個事務的執行過程當中所能看到的數據,總是和這個事務啟動時能看到的數據保持一致。當然在可重覆讀時,這個事務自身所做的變更對其他事務來說也是不可見的。
- 串列化: 寫會加“寫鎖”,讀會加“讀鎖”,出現讀寫衝突時,後訪問的事務必須等前一個事務執行完成,才能繼續執行。

(圖片來源於 極客時間 林曉斌 《MySQL 實戰45講》,如有版權問題請聯繫我刪除)
以上圖為例,在四種隔離級別下對應的情況分別為:
- 讀未提交:事務A啟動時查詢結果為1, V1時值為2(讀到了事務B未提交的數據),V2時值為2,V3時值為2
- 讀提交:事務A啟動時查詢結果為1, V1時值為1(讀不到事務B未提交的數據),V2時值為2(事務B已經提交,可以被事務A讀到),V3時值為2
- 可重覆讀:事務A啟動時查詢結果為1, V1時值為1(讀不到事務B未提交的數據),V2時值為1(事務A未提交,在事務A過程內保持與事務A啟動時讀到的數據一致),V3時值為2(事務A已經提交)
- 串列化:事務B在執行將1改成2時會被鎖住,直到事務A提交後,事務B才可以繼續執行。因此 V1,V2的值是1,V3的值是2.
在實現上,資料庫里會創建一個視圖,訪問的時候以視圖的邏輯結果為準。 在“可重覆讀”下,這個視圖是在事務啟動時建立的。在“讀提交”下,這個視圖是在每個SQL語句開始執行的時候創建的。另:“讀未提交”下,不創建視圖,直接返回記錄上的最新值。在“串列化”下使用加鎖的方式來避免進行並行訪問。
事務隔離級別的實現:
以可重覆讀為例,假設將一個值從1案順序改成2,3,4.在回滾日誌里會有如下的記錄。
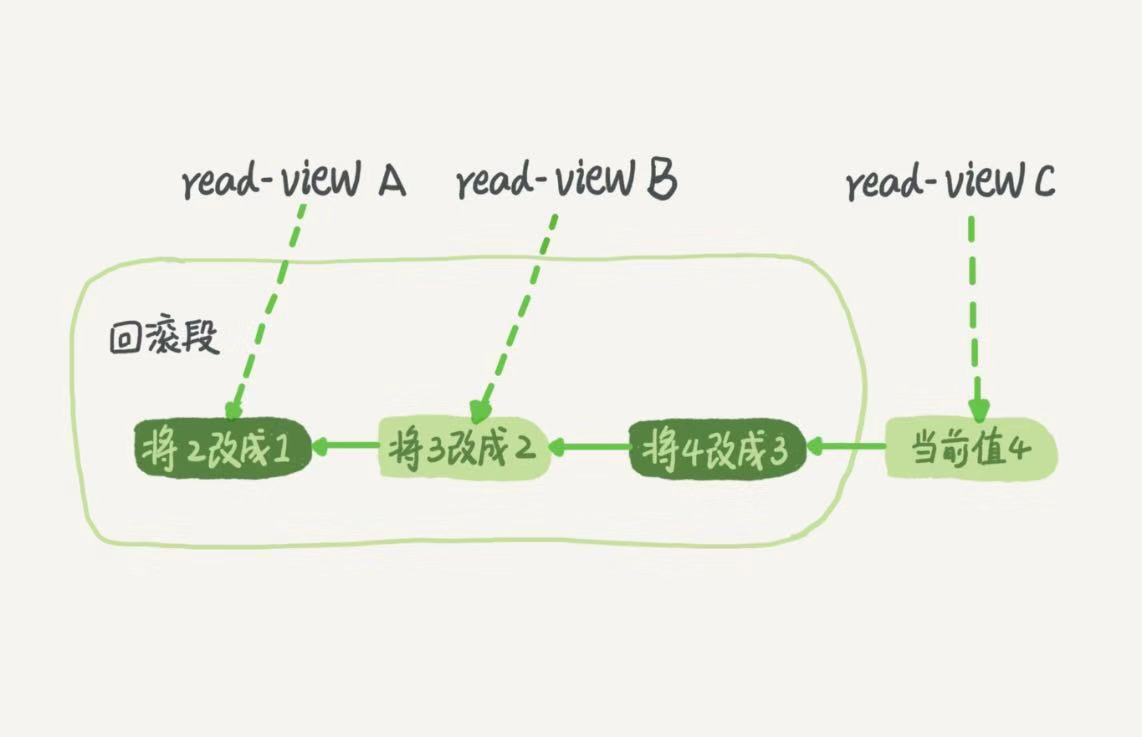
(圖片來源於 極客時間 林曉斌 《MySQL 實戰45講》,如有版權問題請聯繫我刪除)
在MySQL中,實際上每條記錄在更新的時候都會同時記錄一條回滾操作,通過這個回滾操作可以獲得更新前的記錄。當前值是4,但是在查詢這條記錄時,不同時刻啟動的事務會有不同的read-view. 同一條記錄在系統中存在多個版本,這就是資料庫的多版本併發控制(MVCC),對於A來說,要想得到1,就必須將當前所有操作依次回滾。即使這個時候有一個新的事務將4改成其他值,這個新的事務也和之前是事務沒有衝突。每個事務被隔離開來了。
當然,回滾操作的日誌不會一直保留,直到系統中沒有比這個回滾操作更早的read-view時就會刪除回滾操作日誌。因此當你使用長事務時,系統中可能會存在很古老的read-view視圖,當然對應的回滾操作也不會刪除,回滾日誌就會變得很大。
上篇問題答案:
請問在什麼場景下,一天一次備份會比一周一次備份更有優勢?或者說,它影響了這個數據系統的哪些指標?
在一天一備份的情況下,最壞情況需要應用一天的binlog,一周一備份則會需要使用一周的binlog了。系統的對應指標就是 RTO(恢複目標時間)。當然也不是說一天一備份就完全優於一周一備份,因為頻繁的全量備份需要消耗更多存儲空間,需要根據具體業務來評估。
問題:
如果你是資料庫負責人,你有什麼方案來避免長事務呢?


