
如果你想抓取數據,又懶得寫代碼了,可以試試 web scraper 抓取數據。 相關文章: "最簡單的數據抓取教程,人人都用得上" "web scraper 進階教程,人人都用得上" 如果你在使用 web scraper 抓取數據,很有可能碰到如下問題中的一個或者多個,而這些問題可能直接將你計劃打亂 ...
如果你想抓取數據,又懶得寫代碼了,可以試試 web scraper 抓取數據。
相關文章:
最簡單的數據抓取教程,人人都用得上
web scraper 進階教程,人人都用得上
如果你在使用 web scraper 抓取數據,很有可能碰到如下問題中的一個或者多個,而這些問題可能直接將你計劃打亂,甚至讓你放棄 web scraper 。
下麵列出幾種你可能會碰到的問題,並說明解決方案。
1、有時候我們想選擇某個鏈接,但是滑鼠點擊就出觸發頁面跳轉,如何處理?
在我們選擇頁面元素的時候,勾選 “Enable key”,然後滑鼠滑到要選擇的元素上,按下 S 鍵。
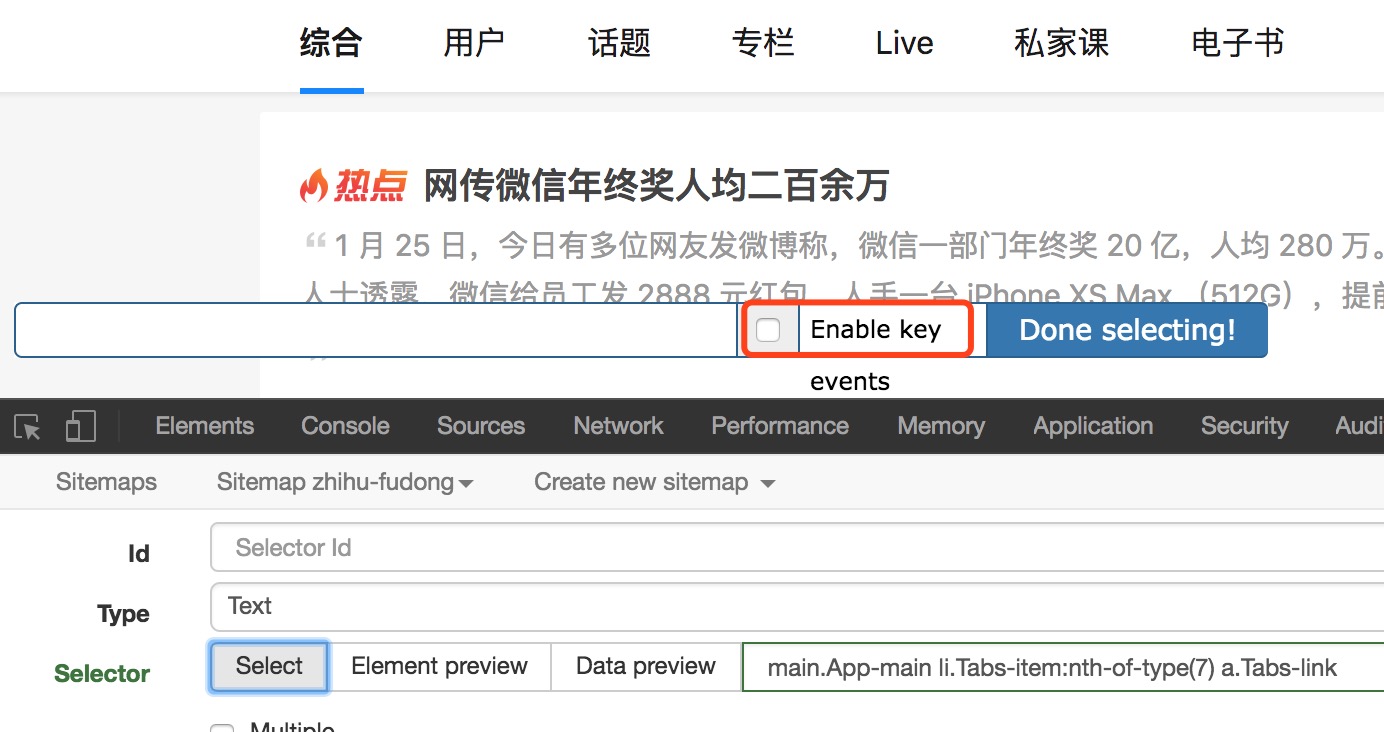
另外,勾選“Enable key” 後會出現三個字母,分別是 S、P、C,按 S 就是選擇當前元素,按 P 就是選擇當前元素的父元素,按 C 就是選擇當前元素的子元素,當前元素指的是滑鼠所在的元素。
2、分頁數據或者滾動載入的數據,不能完全抓取,例如知乎和 twitter 等?
出現這種問題大部分是因為網路問題,數據還沒來得及載入,web scraper 就開始解析數據,但是因為沒有及時載入,導致 web scrpaer 誤認為已經抓取完畢。
所以適當的調大 delay 的大小,延長等待時間,讓數據有足夠的時間載入。預設的 delay 是 2000,也就是 2 秒,可以根據網速調整。
但是,當數據量比較大的時候,出現數據抓取不完全的情況也是常有的。因為只要有一次翻頁或者一次下拉載入沒有在 delay 的時間內載入完成,那麼抓取就結束了。
3、抓取的數據順序和網頁上的順序不一致?
web scraper 預設就是無序的,可以安裝 CouchDB 來保證數據的有序性。
或者採用其他變通的方式,我們最後會將數據導出到 CSV 格式,CSV 用 Excel 打開之後,可以按照某一列來排序,例如我們抓取微博數據的時候將發佈時間抓取下來,然後再 Excel 中按照發佈時間排序,或者知乎上的數據按照點贊數排序。
4、有些頁面元素通過 web scraper 提供的 selector 選擇器沒辦法選中?
造成這種情況的原因可能是因為網站頁面本身不符合網頁佈局規範,或者你想要的數據是動態的,例如滑鼠滑過才會顯示的元素等,遇到這些情況就要藉助其他方法了。
其實通過滑鼠操作選擇元素,最後就是為了找到元素對應的 xpath。xpath 對應到網頁上來解釋,就是定位某元素的路徑,通過元素的種類、唯一標識、樣式名稱,配合上下級關係來找到某個元素或某一類元素。
如果你沒有遇到這個問題,那就沒有必要瞭解 xpath,等到遇到了問題再動手去學一下就可以。
這裡只是說了幾個使用 web scraper 的過程中常見的問題,如果你還遇到了其他的問題,可以在文章下麵留言。
原文地址:web scraper 抓取網頁數據的幾個常見問題
還可以加我個人微信號 fengdezitai001,添加請說明來意以便備註。


