
我相信對於很多愛好和習慣寫博客的人來說,如果自己的博客有很多人閱讀和評論的話,自己會非常開心,但是你發現自己用心寫的博客卻沒什麼人看,多多少少會覺得有些傷心吧?我們今天就來看一下為什麼你的博客沒人看呢? 一、頁面分析 首先進入博客園首頁,可以看到一頁有20篇博客簡介,然後有200頁,也就是說總共有2 ...
我相信對於很多愛好和習慣寫博客的人來說,如果自己的博客有很多人閱讀和評論的話,自己會非常開心,但是你發現自己用心寫的博客卻沒什麼人看,多多少少會覺得有些傷心吧?我們今天就來看一下為什麼你的博客沒人看呢?
一、頁面分析
首先進入博客園首頁,可以看到一頁有20篇博客簡介,然後有200頁,也就是說總共有20*200=4000篇博客。這時我們點擊下一頁,可以看到網頁上的鏈接變成了https://www.cnblogs.com/#p2,看起來好像很簡單--只需要改變#p後面的數字就好了,真的是這樣嗎?打開開發者工具,刷新頁面,可以找到如下鏈接:
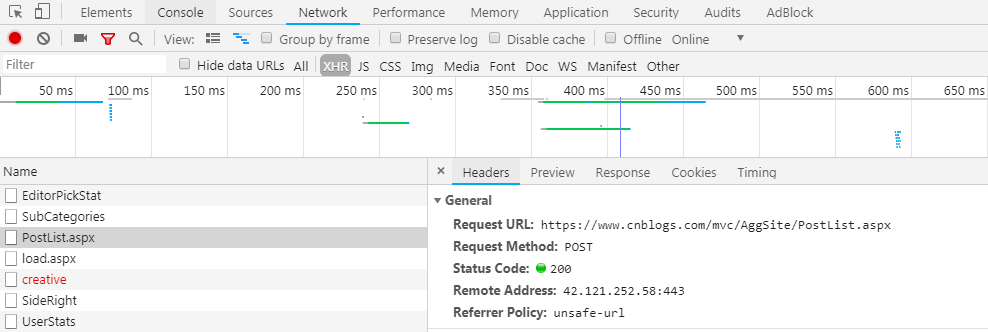
所攜帶的參數是這樣的:
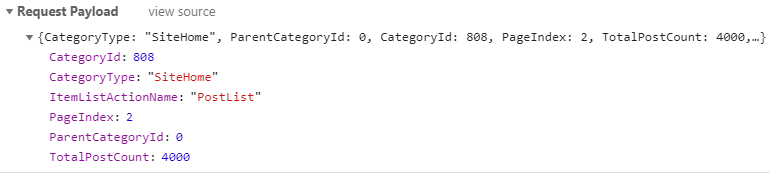
我們很容易就知道只需要改變PageIndex的數值就能實現翻頁了。
二、解析網頁
返回的結果如下圖:

我們可以很方便的使用xpath來解析,相關代碼如下:
1 et = etree.HTML(html) 2 title_list = et.xpath('//*[@class="post_item_body"]/h3/a/text()') # 標題 3 author_list = et.xpath('//*[@class="post_item_foot"]/a/text()') # 作者 4 time_list = et.xpath('//*[@class="post_item_foot"]/text()') # 發佈時間 5 read_list = et.xpath('//*[@class="post_item_foot"]/span[2]/a/text()') # 閱讀數 6 comment_list = et.xpath('//*[@class="post_item_foot"]/span[1]/a/text()') # 評論數
這裡得到的數據都是”發佈於 2019-01-23 14:16“、”評論(0)“、”閱讀(86)“這種,這樣顯然不利於我們對數據進行分析,所以還需要進行一下處理,相關代碼如下:
1 # 處理數據 2 time_list = [i.strip().lstrip('發佈於 ') for i in time_list if i.strip() != ''] 3 comment_list = [int(i.strip().strip('評論(').rstrip(')')) for i in comment_list] 4 read_list = [int(i.strip().strip('閱讀(').rstrip(')')) for i in read_list]
三、存儲數據
這次我使用的資料庫是MySQL資料庫,首先創建一個數據表blogs,SQL代碼如下:
create table if not exists blogs(
title varchar(100) not null,
author varchar(30) not null,
rtime varchar(30) not null,
readnum int(6) not null,
commentnum int(6) not null);
然後就可以把爬取的數據都保存到資料庫里,最後進入資料庫查看一下:
四、數據分析
大家都是幾點寫博客的呢?什麼時候寫的博客會被更多人看到呢?這裡我們可以建一個字典dic1,一個數字代表一個小時,其對應的值就是這個小時里發佈的博客的數量之和,如下:
dic1 = {
0: 0, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6: 0, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0,
13: 0, 14: 0, 15: 0, 16: 0, 17: 0, 18: 0, 19: 0, 20: 0, 21: 0, 22: 0, 23: 0,
}
同理還可以建立一個一樣的字典dic2,但是dic2中每個鍵的值是這個小時里發佈的博客的閱讀量之和。
由於一天的數據量比較小,也不能說明問題,然後通過查看資料庫中的數據,可以知道最近的一篇博客是2019年1月22日寫的,而最早的一篇的博客是2018-11-22日寫的,所以我們可以把2018年12月整個月的數據提取出來進行分析,這樣的話數據量不算少,得到的結果也就更有說服力。相關代碼如下:
1 # 查看2018年12月的數據 2 day_list = ["2018-12-{}".format(str(i).zfill(2)) for i in range(1, 32)] 3 for day in day_list: 4 results = [i for i in all_data if day in i[0]] 5 for result in results: 6 t = int(result[0].split(' ')[1].split(':')[0]) 7 dic1[t] += 1 8 dic2[t] += result[1]
最後根據結果繪製柱狀圖。
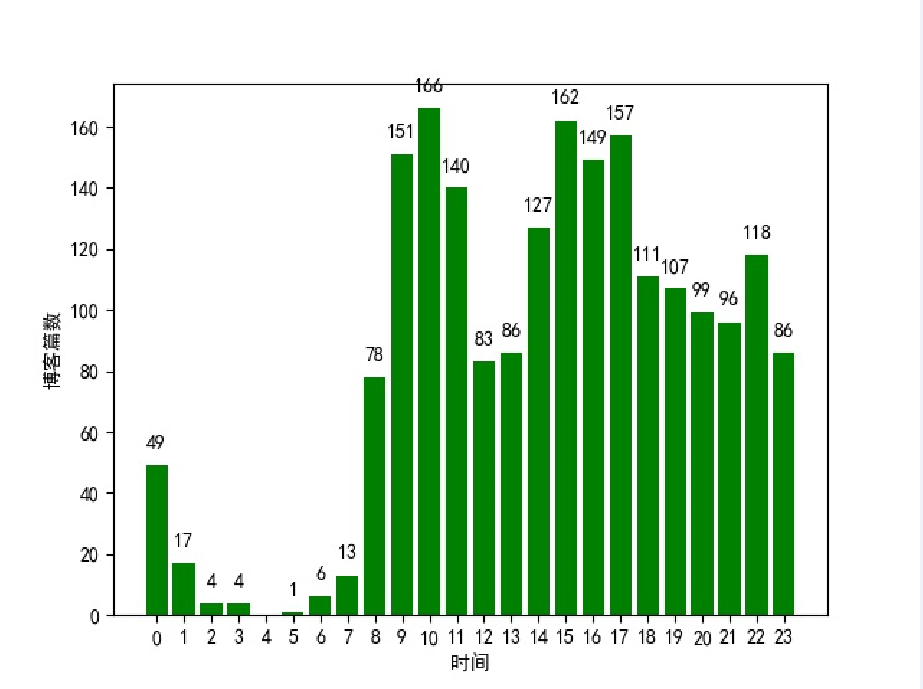
每小時發佈的博客篇數:
每小時發佈的博客閱讀數:
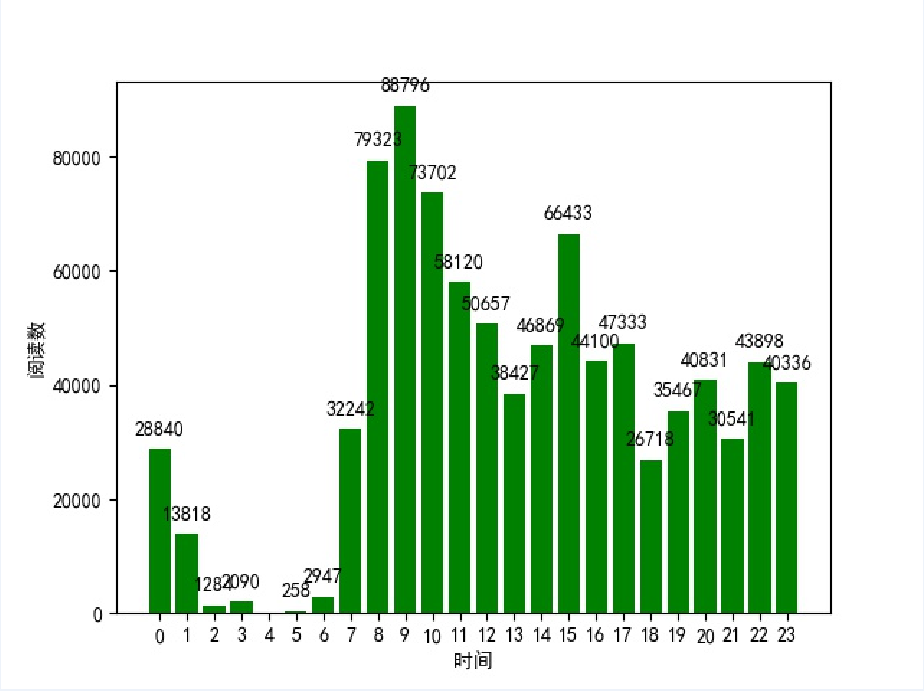
從第一張圖可以看到在早上9點-11點和下午3點-5點是發佈博客的高峰期,在中晚飯時段也有不少人發博客,還有很多人選擇在晚上下班之後寫博客,比較意外的是凌晨三四點的時候也有人寫博客,可以說是很厲害了。根據第二張圖可以知道在早上8點-10點發的博客比較容易得到高閱讀量,下午2點-5點也是比較不錯的寫博客的時間,而凌晨寫博客的話就比較難被大家看到了,畢竟這個時候大多數人還在夢鄉之中。要想你的博客被更多人看到和喜歡,除了選擇一個合適的寫博客的時間,最重要的就是用心寫出一篇好的博客!
完整代碼已上傳到GitHub!


