
本節為JVM垃圾收集的基礎理論,一個GC過程在邏輯上需要經過兩個步驟,即先判斷哪些對象是存活的、哪些對象是死亡的,然後對死亡的對象進行回收。 一、關於回收目標 在前面我們已經瞭解到,JVM的記憶體模型劃分為多個區域,由於不同區域的實現機制以及功能不同,那麼各自的回收目標也不同。一般來說,記憶體回收主要涉 ...
本節為JVM垃圾收集的基礎理論,一個GC過程在邏輯上需要經過兩個步驟,即先判斷哪些對象是存活的、哪些對象是死亡的,然後對死亡的對象進行回收。
一、關於回收目標
在前面我們已經瞭解到,JVM的記憶體模型劃分為多個區域,由於不同區域的實現機制以及功能不同,那麼各自的回收目標也不同。一般來說,記憶體回收主要涉及以下三個區域:- 虛擬機棧/本地方法棧:顧名思義,該部分記憶體以棧的形式作為實現,那麼在進棧、出棧的時候記憶體會自動釋放,類似於C的“自動變數區域記憶體”;
- 堆:記憶體回收主要目標,可以認為類似於C中的“動態記憶體分配區域”,只不過C通過malloc與free函數手動進行管理,而java通過GC進行自動管理;
- 方法區:該區域回收效果很弱,虛擬機規範強制要求在這裡進行回收。回收目標是常量池的回收和對類型的卸載;
二、方法區回收
方法區的回收目標是回收常量池中的廢棄常量與類卸載。2.1.常量回收
若常量池中的某常量沒有任何地方引用或者使用,包括該常量不以字面量的形式被使用或引用,則可以被回收。2.2.類卸載
滿足以下條件的類可以被卸載:- 該類所有實例已被回收;
- 該類的ClassLoader已被回收;
- 該類的類型信息,即java.lang.Class沒有任何地方引用(一般為反射使用);
三、堆回收
3.1.對象存活判定
關於堆中的對象存活判定,以標記為基礎,並配合其他步驟完成。3.1.1.標記演算法
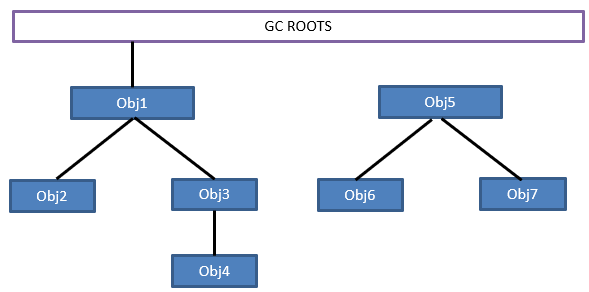
(1)引用計數法 即給對象添加一個引用計數器,每有一個地方進行引用,則計數器加1。當計數器為0的時候,表示該對象可回收。 引用計數法未被JVM採用,原因是其無法解決對象間迴圈引用的問題,如下圖所示,當堆內的兩個對象迴圈引用,就算他們已經沒用了,也無法進行回收:
- 棧上引用:虛擬機棧的棧幀中本地變數表內引用的對象;
- 棧上引用:本地方法棧中JNI引用的對象;
- 方法區:類靜態屬性引用的對象;
- 方法區:類常量引用的對象;
3.1.2.死亡判定
對象在經過標記之後,並不會馬上被回收,還要經過以下一系列階段才最終確定需要被回收: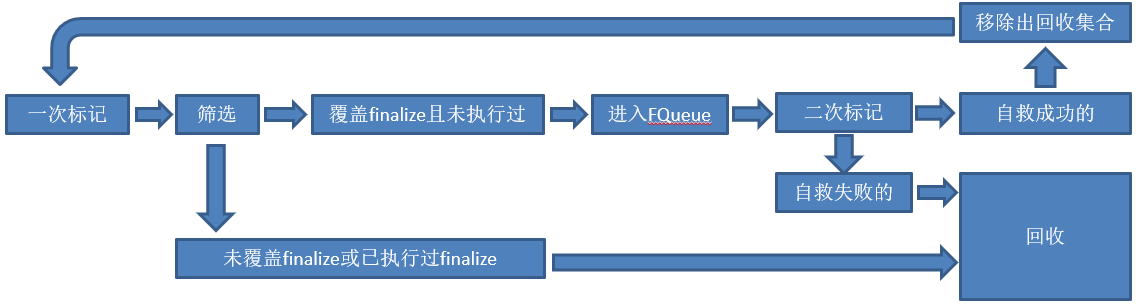
- 一次標記:即通過標記演算法將對象標記為待回收狀態,併進入一個待回收對象集合;
- 篩選:對一次標記之後的待回收對象進行過濾,如果該對象覆蓋了finalize方法,並且該方法未執行過,則將該對象放入F-QUEUE;反之,對象沒有覆蓋finalize方法或者finalize方法已經被執行過了,該對象不會進行任何處理;
- F-QUEUE:一個隊列,JVM會通過一個Finalizer線程去執行這個隊列中對象的finalize方法,並且只保證該方法的執行,不保證該方法成功執行完成。因為若finalize方法有死迴圈,會造成FQUEUE後續未被執行對象的持續等待,導致整個記憶體回收系統崩潰。根據這個特點,對象可以在執行finalize方法時進行“自救”,所謂的自救,就是將對象重新與GC ROOTS相關聯;
- 二次標記:GC會對FQUEUE中的對象進行額外的一次標記,若對象“自救”成功,則會從待回收對象集合中移除;若對象“自救”失敗,它仍然會處於待回收對象集合中,等待真正被回收;
- 回收:對象通過垃圾收集進行回收,釋放記憶體空間;
3.2.垃圾收集演算法
在上一小節我們講了對象標記相關的演算法,本小節來瞭解一下垃圾收集演算法。3.2.1.標記-清除演算法
標記-清除(mark-sweep)演算法,是最基礎的垃圾收集演算法,它的思想比較簡單,就是在“對象存活判定”標記出需要回收的對象後,統一回收(清除)這些對象的記憶體。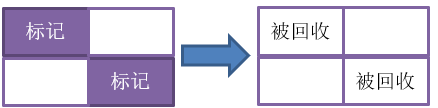
3.2.2.複製演算法
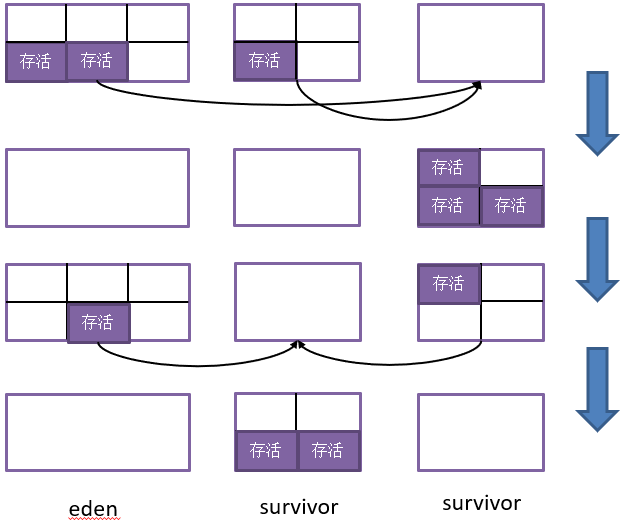
複製演算法(copying)是對標記-清除演算法的改進,其主要思想是將記憶體劃分為不同的區域,包括“記憶體使用區”和“結果緩衝區”。每次只使用一部分記憶體,在該部分記憶體滿了之後,將仍然存活的對象複製到另外一塊區域上面,然後將之前使用過的記憶體區域全部清理掉,現代商業虛擬機都採用其回收新生代。 該演算法大大提高了回收效率,也可以避免記憶體碎片。然而帶來了新的問題:由於需要開闢一塊記憶體空間作為每次回收結果的緩衝,因此可用記憶體無法達到100%,“結果緩衝區”的大小決定了記憶體有效的比率。 如何設置結果緩衝區的記憶體大小(比例)?將其設置為50%最能確保每次回收都有足夠大小的緩衝區域存放回收結果,畢竟最差的情況就是所有對象都存活,然而記憶體浪費也太高了。根據IBM的研究,一般情況下,新生代中的對象98%都是“朝生夕死”的,也就是說,每次存活對象的比例並不會太高,我們只需要設置一小塊記憶體作為“回收結果緩衝”即可,他們提出的解決模型如下,將記憶體劃分為eden與2塊suvivor:
- eden:主存儲區,新對象的創建都在這塊區域;
- survivor:分為兩塊,一塊作為上次回收結果的“緩存”,一塊作為下一次回收的“緩存”區域;
3.2.3.標記-整理演算法
在上一小節我們知道複製演算法主要適合於新生代的回收,對於老年代這種對象存活率高的區域,因為每次都會複製大量對象,成本收益比較低,使用複製演算法明顯不合適;相反,標記-清除演算法更適合老年代的特征,為瞭解決標記-清除演算法的記憶體碎片問題,在此基礎上,優化為標記-整理演算法(mark-compact)。 標記-整理演算法主要思想是在標記對象後,將存活對象向記憶體的一端移動,然後清理掉端邊界以外的記憶體,所謂的整理也可以理解為壓縮。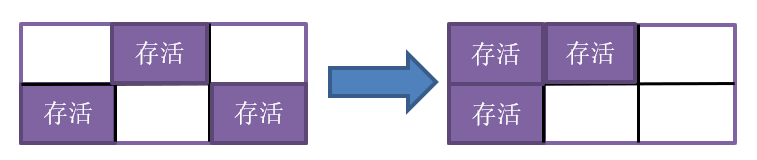
3.2.4.總結
沒有哪一種垃圾收集演算法能夠適用於所有情況,對於不同的堆記憶體區域(新生代、老年代),需要根據實際的對象特征,選擇合適的演算法。| 演算法 | 優點 | 缺點 | 適用區域 |
| 複製 | 效率較高,無記憶體碎片問題 | 1.記憶體利用率達不到100%;2.需要分配擔保機制確保對象存活率較高時的記憶體分配; | 新生代(對象存活率低,複製成本低) |
| 標記-清除 | 簡單有效 | 1.效率不高;2.有記憶體碎片問題; | 老年代(對象存活率高,無額外空間進行分配擔保) |
| 標記-整理 | 標記-清除的改良,解決了記憶體碎片問題 | 1.同樣存在效率問題;2.整理過程需要額外的時間開銷; |

