
一.hive的事務 (1)什麼是事務 要知道hive的事務,首先要知道什麼是transaction(事務)?事務就是一組單元化操作,這些操作要麼都執行,要麼都不執行,是一個不可分割的工作單位。 事務有四大特性:A、C、I、D (原子性、一致性、隔離性、持久性) Atomicity: 不可再分割的工作 ...
一.hive的事務
(1)什麼是事務
要知道hive的事務,首先要知道什麼是transaction(事務)?事務就是一組單元化操作,這些操作要麼都執行,要麼都不執行,是一個不可分割的工作單位。
事務有四大特性:A、C、I、D (原子性、一致性、隔離性、持久性)
Atomicity: 不可再分割的工作單位,事務中的所有操作要麼都發,要麼都不發。
Consistency: 事務開始之前和事務結束以後,資料庫的完整性約束沒有被破壞。這是說資料庫事務不能破壞關係數據的完整性以及業務邏輯上的 一致性。
Isolation: 多個事務併發訪問,事務之間是隔離的
Durability: 意味著在事務完成以後,該事務鎖對資料庫所作的更改便持久的保存在資料庫之中,並不會被回滾。
(2)hive事務的特點與局限性
從hive的0.14版本開始支持低等級的事務
支持事務的增刪改查,從hive的2.2版本開始,開始支持merge
不支持事務的begin、commit以及rollback(事務的回滾)
不支持使用update更新分桶列和分區列
想使用事務的話,文件格式必須是ORC
表必須是分桶表
需要壓縮工作,需要時間,資源和空間
支持S(共用鎖)和X(排它鎖)
不允許從一個非ACID連接寫入/讀取ACID表
(3)hive的事務開啟
hive的事務開啟有三種方式:a.通過Ambari UI-Hive Config
b.通過hive-xml 的配置文件添加如下內容
<property> <name>hive.support.concurrency</name> <value>true</value> </property> <property> <name>hive.txn.manager</name> <value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value> </property>
c.通過命令行,在beeline這種互動式環境下:
set hive.support.concurrency = true; set hive.enforce.bucketing = true; set hive.exec.dynamic.partition.mode = nonstrict; set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; set hive.compactor.initiator.on = true; set hive.compactor.worker.threads = 1;
(4)hive的merge
merge的語法:
MERGE INTO <target table> AS T USING <source expression/table> AS S ON <boolean expression1>
WHEN MATCHED [AND <boolean expression2>] THEN UPDATE SET <set clause list>
WHEN MATCHED [AND <boolean expression3>] THEN DELETE
WHEN NOT MATCHED [AND <boolean expression4>] THEN INSERT VALUES<value list>
merge的局限性:
最多三條when語句,只支持update/delete/insert。when not matched 必須在when語句的最後面。
如果出現update和delete的時候 ,兩個條件是分開的,而且必須在條件前面加上AND.像 [AND <boolean expression>]
(5)例子
a.創建兩個事務表
CREATE TABLE IF NOT EXISTS employee (
emp_id int,
emp_name string,
dept_name string,
work_loc string )
PARTITIONED BY (start_date string)
CLUSTERED BY (emp_id) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES('transactional'='true');
create table employee_state(
emp_id int,
emp_name string,
dept_name string,
work_loc string,
start_date string,
state string
)
STORED AS ORC;
b.開啟事務(見上面的開啟事務的c,一般有些預設的設置是開的,我這裡就只開了自動分區和分桶)
c.插入數據
INSERT INTO table employee PARTITION (start_date) VALUES (1,'Will','IT','Toronto','20100701'), (2,'Wyne','IT','Toronto','20100701'), (3,'Judy','HR','Beijing','20100701'), (4,'Lili','HR','Beijing','20101201'), (5,'Mike','Sales','Beijing','20101201'), (6,'Bang','Sales','Toronto','20101201'), (7,'Wendy','Finance','Beijing','20101201'); insert into table employee_state values (2,’Wyne’,’IT’,’Beijing’,’20100701’,’update’), (4,’Lili’,’HR’,’Beijing’,’20101201’,’quit’), (8,’James’,’IT’,’Toronto’,’20170101’,’new’)
d.檢驗數據是否被插入
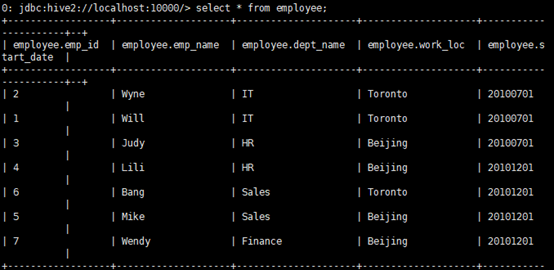

e.這裡通過merge操作,完成更新、刪除、插入操作。
employe欄位解釋:id為2的員工之前的工作地在Toronto,現在在Beijing,state的狀態為update。所以需要更新表employee中員工2的信息
id為4的員工的state狀態為quit,說明目前員工已經離職,所以需要在employee表中刪除關於id為4的員工的信息。
id為8的員工的state狀態為new,說明是新員工,所以需要插入empoyee中。
MERGE INTO employee AS T USING employee_state AS S ON T.emp_id = S.emp_id and T.start_date = S.start_date WHEN MATCHED AND S.state = 'update' THEN UPDATE SET dept_name = S.dept_name,work_loc = S.work_loc WHEN MATCHED AND S.state = 'quit' THEN DELETE WHEN NOT MATCHED THEN INSERT VALUES(S.emp_id,S.emp_name,S.dept_name,S.work_loc,S.start_date);
--這裡目標表為employee,源表為employee_state
--這裡新員工是屬於第三中情況,未在目標表中匹配到,所以直接插入到目標表中。

二.hive的udf
(1)什麼是hive的udf?
User-defined function (UDF): 這提供了一種使用外部函數(在Java中)擴展功能的方法,可以在HQL中進行評估
(2)hive的udf分類
hive的udf一般分為三種:
a.UDF:用戶定義的簡單函數,按行操作併為一行輸出一個結果,例如大多數內置數學和字元串函數
b.UDAF: 用戶定義的聚合函數,按行或按組操作,併為每個組輸出一行或一行,例如MAX和COUNT內置函數。
c.UDTF:用戶定義的表生成函數也按行運行,但結果會生成多行/表,例如EXPLODE函數。 UDTF可以在SELECT之後或在LATERAL VIEW語句之後使用。
(3)hive的udf使用舉例
a.對於hive的udf,這裡我寫了一個把字元串的大寫全部換成小寫和一個判斷字元串是否在一個array數組裡面的函數
--將字元串的所有大寫改成小寫
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public final class StringLower extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
--判斷當前字元串是否在數組裡面
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde.serdeConstants;
import org.apache.hadoop.hive.serde2.objectinspector.ListObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorUtils;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.BooleanWritable;
@Description(name = "Arraycontains",
value="_FUNC_(array, value) - Returns TRUE if the array contains value.",
extended="Example:\n"
+ " > SELECT _FUNC_(array(1, 2, 3), 2) FROM src LIMIT 1;\n"
+ " true")
public class ArrayContains extends GenericUDF {
private static final int ARRAY_IDX = 0;
private static final int VALUE_IDX = 1;
private static final int ARG_COUNT = 2;//這個udf函數需要參數的個數
private static final String FUNC_NAME = "ARRAYCONTAINS";//外部名字
private transient ObjectInspector valueOI;
private transient ListObjectInspector arrayOI;
private transient ObjectInspector arrayElementOI;
private BooleanWritable result;
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
//檢查是否傳入了兩個參數
if (arguments.length != ARG_COUNT) {
throw new UDFArgumentException("the function" + FUNC_NAME + "accepts"
+ ARG_COUNT + "arguments");
}
//檢查參數是否是屬於LIST類型
if (!arguments[ARRAY_IDX].getCategory().equals(ObjectInspector.Category.LIST)) {
throw new UDFArgumentTypeException(ARRAY_IDX, "\"" + serdeConstants.LIST_TYPE_NAME + "\""
+ "expected at function ARRAY_CONTAINS,but"
+ "\"" + arguments[ARRAY_IDX].getTypeName() + "\""
+ "is found");
}
arrayOI = (ListObjectInspector) arguments[ARRAY_IDX];
arrayElementOI = arrayOI.getListElementObjectInspector();
valueOI = arguments[VALUE_IDX];
//檢查list的元素和傳入的值是否屬於同一個類型
if (!ObjectInspectorUtils.compareTypes(arrayElementOI, valueOI)) {
throw new UDFArgumentTypeException(VALUE_IDX, "\"" + arrayElementOI.getTypeName() + "\""
+ "expectd at function ARRAY_CONTAINS,but"
+ "\"" + valueOI.getTypeName() + "\""
+ "is found");
}
//檢查此類型是否支持比較
if (!ObjectInspectorUtils.compareSupported(valueOI)){
throw new UDFArgumentException("this function" + FUNC_NAME
+"does not support comparison for"
+"\"" + valueOI.getTypeName() + "\""
+ "types");
}
result = new BooleanWritable(false);
return PrimitiveObjectInspectorFactory.writableBooleanObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
result.set(false);
Object array = arguments[ARRAY_IDX].get();
Object value = arguments[VALUE_IDX].get();
int arrayLength = arrayOI.getListLength(array);
//檢查數組是否null還是空value是否為null
if (value == null || arrayLength <= 0)//判斷value是否為空,若真則不判斷右邊,不然為假繼續判斷右邊
{
return result;//滿足條件直接返回result初始狀態值
}
//將值與數組的每個元素進行比較,直到找到匹配項
for (int i=0;i<arrayLength;i++){
Object listElement = arrayOI.getListElement(array,i);
if(listElement != null){
if (ObjectInspectorUtils.compare(value,valueOI,listElement,arrayElementOI) == 0){
result.set(true);//找到匹配,直接將result置於真
break;
}
}
}
return result;//返回真值result
}
@Override
public String getDisplayString(String[] childeren) {
assert (childeren.length == ARG_COUNT);
return "array_contains(" + childeren[ARRAY_IDX] + ","
+ childeren[VALUE_IDX] + ")";
}
}
b.然後通過編譯器打包到hdfs文件系統上,通過執行hive命令構造函數
DROP FUNCTION IF EXISTS str_lower; DROP FUNCTION IF EXISTS Array_contains; CREATE FUNCTION str_lower AS 'com.data.hiveudf.udf.StringLower' USING JAR 'hdfs:////apps/hive/functions/df-hiveudf-1.0-SNAPSHOT.jar'; CREATE FUNCTION Array_contains AS 'com.data.hiveudf.gudf.ArrayContains' USING JAR 'hdfs:////apps/hive/functions/df-hiveudf-1.0-SNAPSHOT.jar';
c.使用自定義函數
這裡使用了另一庫里的一張employee表,裡面使用了string類型、array類型...。表描述與內容如下:
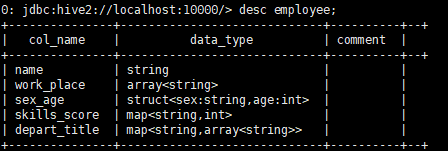
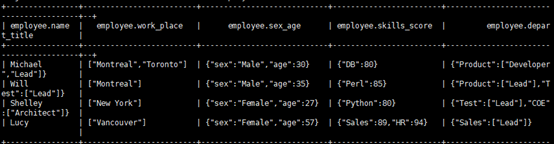
然後使用str_lower的函數:

使用Array_contains函數


