
1. 確認MySQL伺服器是否支持分區表 命令: show plugins; 2. MySQL分區表的特點 在邏輯上為一個表,在物理上存儲在多個文件中 HASH分區(HASH) HASH分區的特點 根據MOD(分區鍵,分區數)的值把數據行存儲到表的不同分區中 數據可以平均的分佈在各個分區中 HASH ...
1. 確認MySQL伺服器是否支持分區表
命令:
show plugins;
2. MySQL分區表的特點
- 在邏輯上為一個表,在物理上存儲在多個文件中
HASH分區(HASH)
HASH分區的特點
- 根據MOD(分區鍵,分區數)的值把數據行存儲到表的不同分區中
- 數據可以平均的分佈在各個分區中
- HASH分區的鍵值必須是一個INT類型的值,或是通過函數可以轉為INT類型
如何建立HASH分區表
以INT類型欄位 customer_id為分區鍵
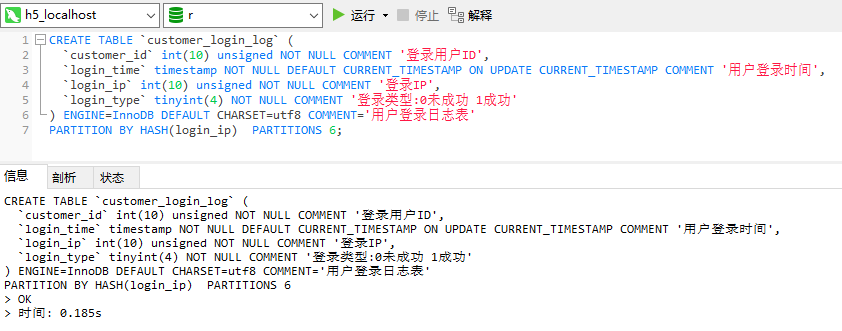
CREATE TABLE `customer_login_log` (
`customer_id` int(10) unsigned NOT NULL COMMENT '登錄用戶ID',
`login_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '用戶登錄時間',
`login_ip` int(10) unsigned NOT NULL COMMENT '登錄IP',
`login_type` tinyint(4) NOT NULL COMMENT '登錄類型:0未成功 1成功'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用戶登錄日誌表'
PARTITION BY HASH(customer_id) PARTITIONS 4;以非INT類型欄位 login_time 為分區鍵(需要先轉換成INT類型)
CREATE TABLE `customer_login_log` (
`customer_id` int(10) unsigned NOT NULL COMMENT '登錄用戶ID',
`login_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '用戶登錄時間',
`login_ip` int(10) unsigned NOT NULL COMMENT '登錄IP',
`login_type` tinyint(4) NOT NULL COMMENT '登錄類型:0未成功 1成功'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用戶登錄日誌表'
PARTITION BY HASH(UNIX_TIMESTAMP(login_time)) PARTITIONS 4;customer_login_log 表如果不分區,在物理磁碟上文件為
customer_login_log.frm # 存儲表原數據信息
customer_login_log.ibd # Innodb數據文件如果按上面的建HASH分區表,則有五個文件
customer_login_log.frm
customer_login_log#P#p0.ibd
customer_login_log#P#p1.ibd
customer_login_log#P#p2.ibd
customer_login_log#P#p3.ibd演示

使用起來和不分區是一樣的,看起來只有一個資料庫,其實有多個分區文件,比如我們要插入一條數據,不需要指定分區,MySQL會自動幫我們處理

查詢

範圍分區(RANGE)
RANGE分區特點
- 根據分區鍵值的範圍把數據行存儲到表的不同分區中
- 多個分區的範圍要連續,但是不能重疊
- 預設情況下使用VALUES LESS THAN屬性,即每個分區不包括指定的那個值
如何建立RANGE分區

如果沒有定義p3分區,當插入的customer_id大於29999時會報錯,定義了則超過的數據都存入p3中
RANGE分區的適用場景
- 分區鍵為日期或是時間類型 (可以使得各個分區表的數據比較均衡,如果按上面的例子中以整型id為分區鍵,假如活躍用戶集中在10000-19999之間,則p1中的數據量就會比其他分區的數據量大很多,這就失去了分區的意義;而且按時間類型分區,如果要按時間順序進行數據的歸檔,則只需要對某一個分區進行歸檔就可以了)
- 所有查詢中都包括分區鍵(避免跨分區查詢)
- 定期按分區範圍清理歷史數據
LIST分區
LIST分區的特點
- 按分區鍵取值的列表進行分區
- 同範圍分區一樣,各分區的列表值不能重覆
- 每一行數據必須能找到對應的分區列表,否則數據插入失敗
如何建立LIST分區

如果插入一條login_type為10的數據行,則會報錯
3. 如何為登錄日誌表(customer_login_log)分區
業務場景
- 用戶每次登錄都會記錄customer_login_log日誌
- 用戶登錄日誌保存一年,1年後可以刪除或者歸檔
登錄日誌表的分區類型及分區鍵
- 使用RANGE分區
- 以login_time為分區鍵
分區後的用戶登錄日誌表
按年份分區存儲,所以用YEAR函數進行了轉化
CREATE TABLE `customer_login_log` (
`customer_id` int(10) unsigned NOT NULL COMMENT '登錄用戶ID',
`login_time` DATETIME NOT NULL COMMENT '用戶登錄時間',
`login_ip` int(10) unsigned NOT NULL COMMENT '登錄IP',
`login_type` tinyint(4) NOT NULL COMMENT '登錄類型:0未成功 1成功'
) ENGINE=InnoDB
PARTITION BY RANGE (YEAR(login_time))(
PARTITION p0 VALUES LESS THAN (2017),
PARTITION p1 VALUES LESS THAN (2018),
PARTITION p2 VALUES LESS THAN (2019)
) 插入並查詢數據

查詢指定表中的分區數據情況
SELECT table_name,partition_name,partition_description,table_rows FROM
information_schema.`PARTITIONS` WHERE table_name = 'customer_login_log';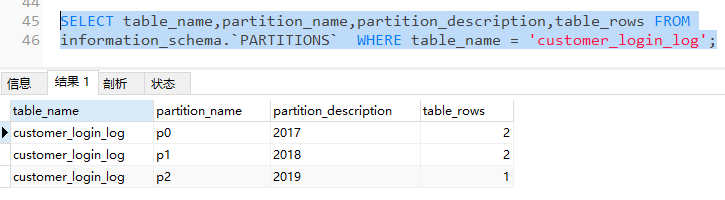
再插入2條18年的日誌,會存入p2表中
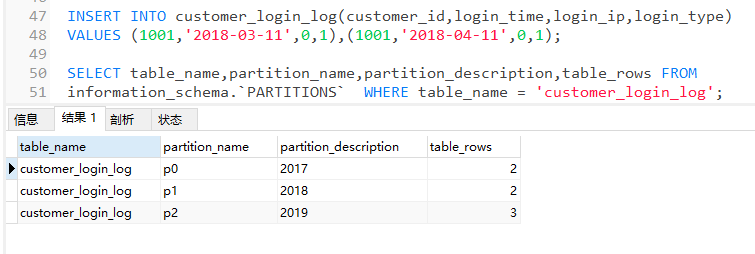
之前說過建立分區表時,最好建立一個MAXVALUE的分區,這裡之所以沒有建立,是為了數據維護的方便,如果我們建立了MAXVALUE分區,很容易忽視一個問題,當我們2019年有的數據插入時,會自動存入那個MAXVALUE分區中,之後在做數據維護時會不方便,所以沒有建立MAXVALUE分區
而是通過計劃任務的方式,在每年年底的時候增加這個分區,比如我們現在在2018年年底,我們需要在日誌表中為2019年建立日誌分區,否則2019年的日誌都會插入失敗

我們可以通過下麵語句
增加分區
ALTER TABLE customer_login_log ADD PARTITION (PARTITION p3 VALUES LESS THAN(2020))增加分區,並插入數據

刪除分區
假如我們現在要刪除2016年到2017年間一年的數據,因為我們已經做了分區,所以只需要通過一條語句,刪除p0分區即可
ALTER TABLE customer_login_log DROP PARTITION p0;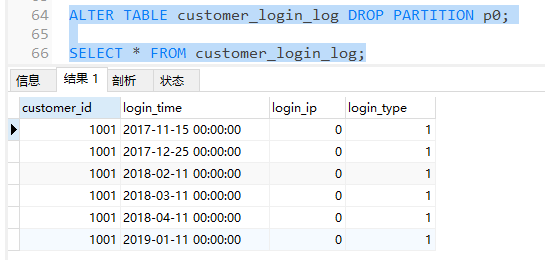
可以發現p0分區已被刪除,且2016年的日誌全部被清除了
歸檔分區歷史數據
我們可能有另一種需求對數據進行歸檔
Mysql版本>=5.7,歸檔分區歷史數據非常方便,提供了一個交換分區的方法
分區數據歸檔遷移條件:
- MySQL>=5.7
- 結構相同
- 歸檔到的數據表一定要是非分區表
- 非臨時表;不能有外鍵約束
- 歸檔引擎要是:archive
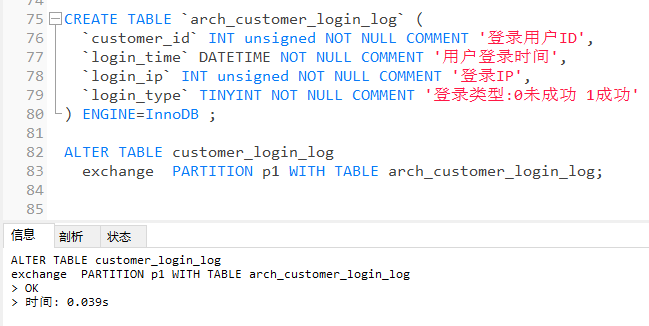
建表並交換分區
CREATE TABLE `arch_customer_login_log` (
`customer_id` INT unsigned NOT NULL COMMENT '登錄用戶ID',
`login_time` DATETIME NOT NULL COMMENT '用戶登錄時間',
`login_ip` INT unsigned NOT NULL COMMENT '登錄IP',
`login_type` TINYINT NOT NULL COMMENT '登錄類型:0未成功 1成功'
) ENGINE=InnoDB ;
ALTER TABLE customer_login_log
exchange PARTITION p1 WITH TABLE arch_customer_login_log;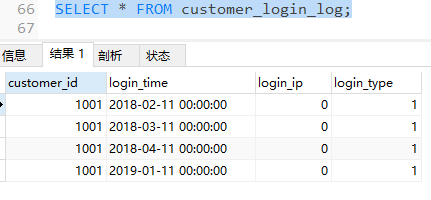
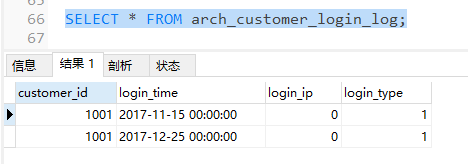
可以發現,原customer_login_log表中的2017年的數據(p1分區中的數據)已轉移到了arch_customer_login_log表中,但是p1分區未刪除,只是數據轉移了,所以我們還需要執行DROP命令刪除分區,以免有數據插入其中
將歸檔數據的存儲引擎改為歸檔引擎
最後我們將歸檔數據的存儲引擎改為歸檔引擎,命令為
ALTER TABLE customer_login_log ENGINE=ARCHIVE;使用歸檔引擎的好處是:它比Innodb所占用的空間更少,但是歸檔引擎只能進行查詢操作,不能進行寫操作
4. 使用分區表的主要事項
- 結合業務場景選擇分區鍵,避免跨分區查詢
- 對分區表進行查詢最好在WHERE從句中包含分區鍵
- 具有主鍵或唯一索引的表,主鍵或唯一索引必須是分區鍵的一部分(這也是為什麼我們上面分區時去掉了主鍵登錄日誌id(login_id)的原因,不然就無法按照上面的按年份進行分區,所以分區表其實更適合在MyISAM引擎中)
關於MyISAM和Innodb的索引區別
1.關於自動增長
myisam引擎的自動增長列必須是索引,如果是組合索引,自動增長可以不是第一列,他可以根據前面幾列進行排序後遞增。
innodb引擎的自動增長咧必須是索引,如果是組合索引也必須是組合索引的第一列。
2.關於主鍵
myisam允許沒有任何索引和主鍵的表存在,
myisam的索引都是保存行的地址。
innodb引擎如果沒有設定主鍵或者非空唯一索引,就會自動生成一個6位元組的主鍵(用戶不可見)
innodb的數據是主索引的一部分,附加索引保存的是主索引的值。
3.關於count()函數
myisam保存有表的總行數,如果select count(*) from table;會直接取出出該值
innodb沒有保存表的總行數,如果使用select count(*) from table;就會遍歷整個表,消耗相當大,但是在加了wehre 條件後,myisam和innodb處理的方式都一樣。
4.全文索引
myisam支持 FULLTEXT類型的全文索引
innodb不支持FULLTEXT類型的全文索引,但是innodb可以使用sphinx插件支持全文索引,並且效果更好。(sphinx 是一個開源軟體,提供多種語言的API介面,可以優化mysql的各種查詢)
5.delete from table
使用這條命令時,innodb不會從新建立表,而是一條一條的刪除數據,在innodb上如果要清空保存有大量數據的表,最 好不要使用這個命令。(推薦使用truncate table,不過需要用戶有drop此表的許可權)
6.索引保存位置
myisam的索引以表名+.MYI文件分別保存。
innodb的索引和數據一起保存在表空間里。


