
在寫高併發交易代碼時要謹慎使用strncpy和sprintf 原因及建議實踐 ...
分享一下最近做程式優化的一點小心得:在寫高併發交易代碼時要謹慎使用strncpy和sprintf。
下麵詳細介紹一下這樣說的原因及建議實踐:
1 慎用strncpy因為它的副作用極大
我們平時使用strncpy防止字元串拷貝時溢出,常常這樣寫
char buf[1024] = {0}; char str[16] = "hello"; strncpy(buf, sizefo(buf), str);
這樣寫當然沒問題,但有些人不知道的是:strncpy一行代碼執行時是往buf寫了sizeof(buf) = 1024個位元組,而不是直觀以為的strlen(str) + 1 = 6個字元。
也就是說我們為了複製6個字元卻寫了1024個位元組,多了不少額外消耗。如果這個函數被頻繁調用,會導致系統性能出現不少損失。
因為調用strncpy(dest, n, str)時,函數首先將字元從源緩衝區str逐個複製到目標緩衝區dest,直到拷貝了n碰上\0。
緊接著,strncpy函數會往buf填充\0字元直到寫滿n個字元。
所以我才會說上面的代碼strncpy才會寫了1024個位元組。
可以做一個小實驗:
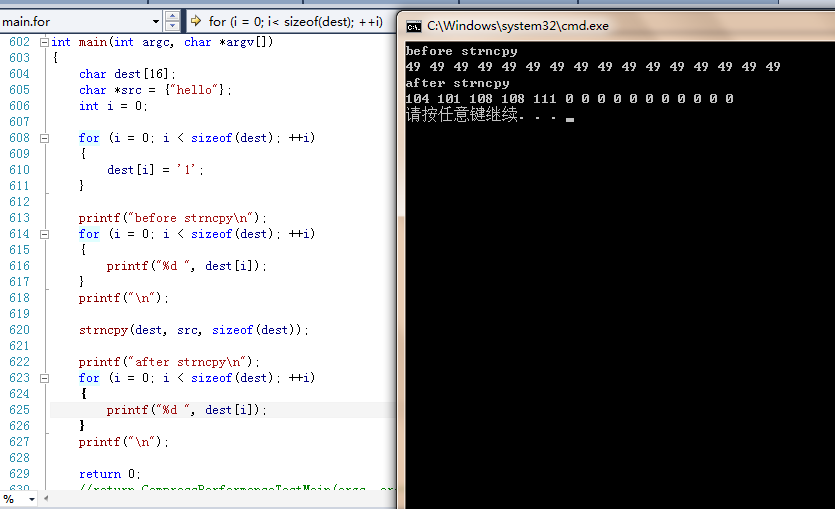
看上面代碼及輸出結果,我們可以知道在執行strncpy之前dest是用'1'填充的,但在執行strncpy後,前面幾個字元變成hello,後面的字元全變成\0;
我個人的解決方法是寫一個巨集專用於往字元數組拷貝的,與大家分享一下,拋磚引玉。
// 靜態斷言 從vc拷貝過來(_STATIC_ASSERT) 稍微修改了一下 // 原來是typedef char __static_assert_t[ (expr) ] // 現在是typedef char __static_assert_t[ (expr) - 1 ] // 原因是gcc支持0字元數組 //TODO: 這裡在win上編譯有警告 有待優化 另外在linux巨集好像不起作用 原因待查。暫時只有在win編譯代碼可以用 #ifndef _STATIC_ASSERT_RCC # ifdef __GNUC__ # define _STATIC_ASSERT_RCC(expr) typedef char __static_assert_t[ (expr) - 1 ] # else # define _STATIC_ASSERT_RCC(expr) do { typedef char __static_assert_t[ (expr) ]; } while (0) # endif #endif //將src複製到字元數組arr 保證不會越界並且末尾肯定會加\0 //_STATIC_ASSERT_RCC這裡作用是防止有人傳字元串指針進來 #define strncpy2arr(arr, src) do { \ char *dest_ = arr; \ size_t n = strnlen(src, sizeof(arr) - 1); \ _STATIC_ASSERT_RCC(sizeof(arr) != sizeof(char *)); \ memcpy(dest_, src, n); \ dest_[n] = '\0'; \ } while (0) #ifdef WIN32 int main(int argc, char *argv[]) { char dest[16]; char *src = "hello 222"; int i = 0; for (i = 0; i < sizeof(dest); ++i) { dest[i] = '1'; } printf("before strncpy\n"); for (i = 0; i < sizeof(dest); ++i) { printf("%d ", dest[i]); } printf("\n"); strncpy2arr(dest, src); printf("after strncpy\n"); for (i = 0; i < sizeof(dest); ++i) { printf("%d ", dest[i]); } printf("\n"); strncpy(dest, src, sizeof(dest)); printf("after strncpy\n"); for (i = 0; i < sizeof(dest); ++i) { printf("%d ", dest[i]); } printf("\n"); return 0; //return CompressPerformanceTestMain(argc, argv); } #endif
2 慎用sprintf,因為它的效率比你想象的低
之前我一直沒註意到sprintf效率低的問題,直到有一次使用callgrind對程式進行性能分析時,發現有相當大的資源消耗在sprintf上面,我才有所警覺。
為此,我寫了一點測試代碼,對常用的函數做了一下基準測試,結果如下:
|
測試內容 |
耗時(us) |
|
for迴圈賦值40億次 |
13023889 |
|
調用簡單函數40億次 |
16967986 |
|
調用memset函數4億次 (256個位元組) |
6932237 |
|
調用strcpy函數4億次 (12個位元組) |
3239218 |
|
調用memcpy函數4億次 (12個位元組) |
3239201 |
|
調用strcmp函數4億次 (12個位元組) |
2500568 |
|
調用memcmp函數4億次 (12個位元組) |
2668378 |
|
調用strcpy函數4億次 (74個位元組) |
4951085 |
|
調用memcpy函數4億次 (74個位元組) |
4950890 |
|
調用strcmp函數4億次 (74個位元組) |
5551391 |
|
調用memcmp函數4億次 (74個位元組) |
3840448 |
|
調用sprintf函數8千萬次 (約27個位元組) |
21398106 |
|
調用scanf函數8千萬次 (約27個位元組) |
36158749 |
|
調用fwrite函數8千萬次 |
5913579 |
|
調用fprintf函數8千萬次 |
24806837 |
|
調用fread函數8千萬次 |
3182704 |
|
調用fscanf函數8千萬次 |
18739442 |
|
調用WriteLog函數20萬次 (15個位元組) |
4873746 |
|
調用WriteLog函數20萬次 (47個位元組) |
4846449 |
|
調用WriteLog函數20萬次 (94個位元組) |
4950448 |
|
|
|
1us = 1000ms
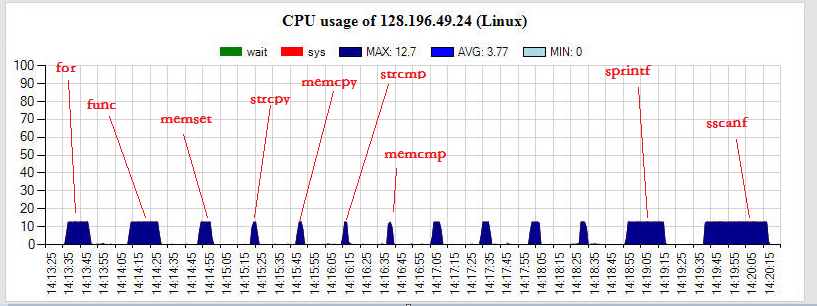
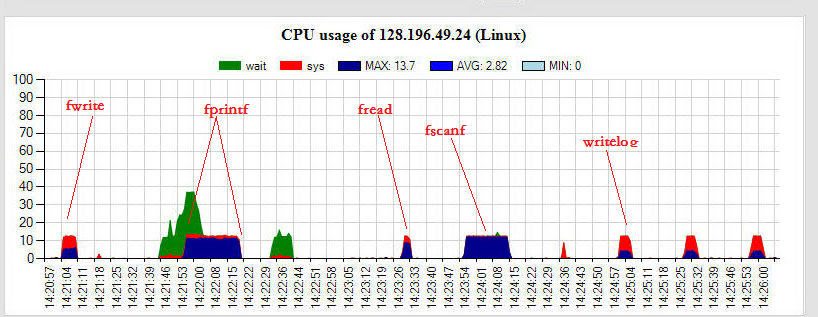
圖示:scanf/printf系列函數耗時是其它常見字元串操作函數的10倍以上,甚至比io操作還耗時
測試代碼見這裡:
#define TEST_LOG_INF NULL, __FILE__, __LINE__ #ifdef WIN32 #define WriteLog lazy_log_output #define LOG_ERROR NULL, __FILE__, __LINE__ #define LOG_KEY NULL, __FILE__, __LINE__ #define sleep(n) Sleep(100 * n) int gettimeofday(struct timeval *tv, struct timezone *tz) { SYSTEMTIME wtm; GetLocalTime(&wtm); tv->tv_sec = (long)(wtm.wDayOfWeek * 24 * 3600 + wtm.wHour * 3600 + wtm.wMinute * 60 + wtm.wSecond); tv->tv_usec = wtm.wMilliseconds * 1000; return 0; } void InitLog(const char *logname) { } #endif struct timeval begTimes = {0}, endTims = {0}; void beginTimer() { gettimeofday(&begTimes, NULL); } int g_nSleepSec = 10; void stopTimer(char *userdata, const char *file, int fileno, int nSleepFlag) { size_t totalTranTimes; gettimeofday(&endTims, NULL); totalTranTimes = (size_t)(endTims.tv_sec - begTimes.tv_sec) * 1000000 + (endTims.tv_usec - begTimes.tv_usec); #ifdef WIN32 WriteLog(userdata, file, fileno, "== == end == == == totalTranTimes %lu us", (unsigned long) totalTranTimes); #else WriteLog(2, file, fileno, "== == end == == == totalTranTimes %lu us", (unsigned long) totalTranTimes); #endif if (nSleepFlag) { WriteLog(LOG_ERROR, "sleep"); sleep(g_nSleepSec); } else { beginTimer(); } } void PerformanceTestLog(char *userdata, const char *file, int fileno, const char *log) { stopTimer(userdata, file, fileno, 1); #ifdef WIN32 WriteLog(userdata, file, fileno, "== == beg == == == %s", log); #else WriteLog(2, file, fileno, "== == beg == == == %s", log); #endif beginTimer(); } int func(int argc, char *argv[], char *tmp) { tmp[argc] = '1'; return 0; } //基準測試 int BaseTest(unsigned long nTimes) { unsigned long i = 0; char tmp[256], t1[64], t2[64], t3[64]; int nTmp; const char *strWriten; nTimes *= 100000; //40億 WriteLog(LOG_KEY, "BaseTest %lu", nTimes); beginTimer(); PerformanceTestLog(TEST_LOG_INF, "test for"); for (i = 0; i < nTimes; ++i) { i = i; } PerformanceTestLog(TEST_LOG_INF, "test call func"); for (i = 0; i < nTimes; ++i) { func(1, NULL, tmp); } stopTimer(TEST_LOG_INF, 0); nTimes /= 10; //4億 WriteLog(LOG_KEY, "BaseTest %lu", nTimes); PerformanceTestLog(TEST_LOG_INF, "test memset"); for (i = 0; i < nTimes; ++i) { memset(tmp, 0, sizeof(tmp)); } PerformanceTestLog(TEST_LOG_INF, "test strcpy"); for (i = 0; i < nTimes; ++i) { strcpy(tmp, "test strcpy"); } PerformanceTestLog(TEST_LOG_INF, "test memcpy"); for (i = 0; i < nTimes; ++i) { memcpy(tmp, "test strcpy", sizeof("test strcpy")); } PerformanceTestLog(TEST_LOG_INF, "test strcmp"); for (i = 0; i < nTimes; ++i) { if (0 == strcmp(tmp, "test strcpy")) { i = i; } } PerformanceTestLog(TEST_LOG_INF, "test memcmp"); for (i = 0; i < nTimes; ++i) { if (0 == memcmp(tmp, "test strcpy", sizeof("test strcpy"))) { i = i; } } PerformanceTestLog(TEST_LOG_INF, "test strcpy1"); for (i = 0; i < nTimes; ++i) { strcpy(tmp, "test strcpy test strcpy test strcpy test strcpy test strcpytest strcpy"); } PerformanceTestLog(TEST_LOG_INF, "test memcpy1"); for (i = 0; i < nTimes; ++i) { memcpy(tmp, "test strcpy test strcpy test strcpy test strcpy test strcpytest strcpy", sizeof("test strcpy test strcpy test strcpy test strcpy test strcpytest strcpy")); } PerformanceTestLog(TEST_LOG_INF, "test strcmp1"); for (i = 0; i < nTimes; ++i) { if (0 == strcmp(tmp, "test strcpy test strcpy test strcpy test strcpy test strcpytest strcpy")) { i = i; } } PerformanceTestLog(TEST_LOG_INF, "test memcmp1"); for (i = 0; i < nTimes; ++i) { if (0 == memcmp(tmp, "test strcpy test strcpy test strcpy test strcpy test strcpytest strcpy", sizeof("test strcpy test strcpy test strcpy test strcpy test strcpytest strcpy"))) { i = i; } } stopTimer(TEST_LOG_INF, 0); nTimes /= 5; //8千萬 WriteLog(LOG_KEY, "BaseTest %lu", nTimes); PerformanceTestLog(TEST_LOG_INF, "test sprintf"); for (i = 0; i < nTimes; ++i) { sprintf(tmp, "thiis %s testing %d", "sprintf", i); } PerformanceTestLog(TEST_LOG_INF, "test sscanf"); for (i = 0; i < nTimes; ++i) { sscanf(tmp, "%s %s %s %d", t1, t2, t3, &nTmp); } { FILE *fp; int nStr; PerformanceTestLog(TEST_LOG_INF, "fopen"); fp = fopen("performancetest.txt", "w"); strWriten = "this is testing write\n"; nStr = strlen(strWriten); PerformanceTestLog(TEST_LOG_INF, "test write file"); for (i = 0; i < nTimes; ++i) { fwrite(strWriten, 1, nStr, fp); } PerformanceTestLog(TEST_LOG_INF, "fflush"); fflush(fp); PerformanceTestLog(TEST_LOG_INF, "test fprintf file"); for (i = 0; i < nTimes; ++i) { //太過簡單的fprintf好像會被自動優化成fwrite,即使沒開優化選項 //例如 fprintf(fp, "%s", "strWriten"); fprintf(fp, "%s %d\n", "strWriten", i); } PerformanceTestLog(TEST_LOG_INF, "fclose"); fclose(fp); } { FILE *fp; int nStr; PerformanceTestLog(TEST_LOG_INF, "fopen 1"); fp = fopen("performancetest.txt", "r"); nStr = strlen(strWriten); PerformanceTestLog(TEST_LOG_INF, "test read file"); for (i = 0; i < nTimes; ++i) { fread(tmp, 1, nStr, fp); tmp[nStr] = '\0'; } PerformanceTestLog(TEST_LOG_INF, "test fscanf file"); tmp[0] = t1[0] = '\0'; for (i = 0; i < nTimes; ++i) { fscanf(fp, "%s %s", tmp, t1); } PerformanceTestLog(TEST_LOG_INF, "fclose"); fclose(fp); } fclose(fopen("performancetest.txt", "w")); nTimes /= 400; //20萬 WriteLog(LOG_KEY, "BaseTest %lu", nTimes); PerformanceTestLog(TEST_LOG_INF, "WriteLog 1"); for (i = 0; i < nTimes; ++i) { WriteLog(LOG_ERROR, "this is loging"); } PerformanceTestLog(TEST_LOG_INF, "WriteLog 2"); for (i = 0; i < nTimes; ++i) { WriteLog(LOG_ERROR, "this is loging this is loging this is loging"); } PerformanceTestLog(TEST_LOG_INF, "WriteLog 3"); for (i = 0; i < nTimes; ++i) { WriteLog(LOG_ERROR, "this is loging this is loging this is loging this is loging this is loging this is loging"); } stopTimer(TEST_LOG_INF, 0); return 0; }
從基準測試結果可以知道,sprintf系列函數效率是比較低的,是我們常見的字元串操作函數的1/10以下。
我個人的解決方案是sprintf該用還是用,但有些情況不是特別必要用的情況,用自己寫一些小函數代替。例如下麵這個巨集是用來代替sprintf(buf, "%02d", i)的
//sprintf比較慢 這裡需要寫一些簡單的字元串組裝函數 //這個是代替%02d的(但不會添加\0結尾)顧名思義,傳入的值需要保證0 <= vallue < 100 //再次提醒註意,這裡為了方便調用,不會添加\0! 不會添加\0! 不會添加\0! #define itoaLt100Ge0(value, buff_output) do \ {\ int value_ = (int)(value);\ char *buff_output_ = (buff_output);\ if ((value_) >= 10) { int nDigit_ = value_ / 10; buff_output_[0] = '0' + nDigit_; buff_output_[1] = '0' + (value_ - nDigit_ * 10); }\ else { buff_output_[0] = '0'; buff_output_[1] = '0' + (value_); } \ } while (0)
總結一下就是:高併發交易需要慎用strncpy和sprintf,因為不恰當使用它們可能會成為程式性能瓶頸。
如果大家有啥想法,歡迎分享,我是黃詞輝,一個程式員 ^_^

