
今天在寫一個StringIO.write(int)示例時思維那麼一發散就拐到了字元集的問題上,順手搜索一發,除了極少數以外,絕大多數中文博客都解釋的慘不忍睹,再鑒於被此問題在oracle的字元集體系中蹂躪過,因此在過往筆記的基礎上增刪了幾個示例貼出來。 Python2: 首先清楚兩個Python 2 ...
今天在寫一個StringIO.write(int)示例時思維那麼一發散就拐到了字元集的問題上,順手搜索一發,除了極少數以外,絕大多數中文博客都解釋的慘不忍睹,再鑒於被此問題在oracle的字元集體系中蹂躪過,因此在過往筆記的基礎上增刪了幾個示例貼出來。
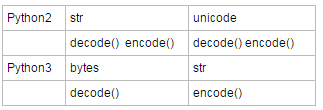
Python2:
首先清楚兩個Python 2中的概念:str和unicode 這是python2中的兩種用於表示文本的類型,一般來說你直接打出的字元都屬於前者,加了u首碼的字元則屬於後者。
str is text representation in bytes, unicode is text representation in characters.
此觀點來自stackoverflow,是得票最多的一個回答,也是我認為最好的一個,但是從我個人的角度來看這個表述依然不足,最適合的表述應當是:
str is text representation in bytes, unicode is text representation in unicode characters(or unicode bytes).
貌似沒多大區別......可能會被人打,但我的意思是python2里的unicode是字元和編碼綁定的,只要是unicode類型那麼他的編碼和字元都已經固定了,但是str類型卻只有編碼,只有最初打出它的人才知道他的字元是什麼(或者說才能通過適當的字元集解碼為人眼可懂的字元)。
Python2里的str是十六進位表示的二進位編碼,unicode是一個字元:
通俗點來說就是Python2里的str類型是一堆二進位編碼,如果不知道是什麼字元集那麼你除了一堆十六進位
數什麼都看不出來(當然平時你使用的工具都是能看到的,因為工具已經做了轉碼),通過decode可以將其按固定的字元集解碼,生成unicode字元。
例如下例(python2環境下的windows cmd視窗):
>>> a='你好'
>>> a.decode('utf-8')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Python27\lib\encodings\utf_8.py", line 16, in decode
return codecs.utf_8_decode(input, errors, True)
UnicodeDecodeError: 'utf8' codec can't decode byte 0xc4 in position 0: invalid continuation byte
錯誤的原因是這裡的“你好”字元是cp936編碼(相當於gbk),utf-8屬於非ANSI體系的編碼,“你好”的gbk二進位碼不符合unicode體系的編碼規則因此報錯。
>>> print a.decode('gbk'),type(a.decode('gbk'))
你好 <type 'unicode'>
這樣就可以啦,既然a是gbk編碼的str那麼按gbk進行decode解碼,自然能得到unicode的你好字元。
decode: str to unicode,decode的輸入必須是str類型,輸出一定是unicode類型 str.decode(encoding='UTF-8',errors='strict') encode: unicode to str,encode的輸入必須是unicode類型,輸出一定是str類型 unicode_char.encode(encoding='gbk',errors='strict')
Python3:
在Python3中str調用decode()方法會遇到: AttributeError: 'str' object has no attribute 'decode' .
why?
這是因為python3中表示文本的只有一種類型了,那就是str,你以為這是python2里的那個str嗎?No! 這個str是python2中的unicode類型......
那麼原來的str哪裡去了?被命名為bytes類型了,decode方法也隨之給了bytes類型,encode給了str類型。
這樣做的好處是:
在Python2中str和unicode都有decode,encode兩種方法,但是字元集參數不設置正確的話,函數經常報錯,文本能否正確流通取決於大家是否清楚輸入編碼的字元集,這對於全球化的網站來說是個巨坑,而在Python3中無論你輸入什麼字元,統一都是str類型的(也就是python2里的unicode類型),通過bytes和str類型的分離將decode,encode這兩種方法分離,encode函數不會出錯,因為編碼與字元集是綁定的,你可以隨意將unicode字元轉化為任意ANSI體系字元集的bytes類型,此時在已知ANSI字元集的情況下,你對bytes類型的decode轉碼一定不會出錯。通過這種方式就避免了python2中輸入str類型帶來的編碼混亂問題。
[root@python ~]# python3
Python 3.6.5 (default, Apr 9 2018, 17:15:34)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-4)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> a='你好'
>>> type(a)
<class 'str'>
>>> a.encode('gbk')
b'\xc4\xe3\xba\xc3'
>>> type(a.encode('gbk'))
<class 'bytes'>
通過encode方式我們可以把unicode字元轉為任意字元集的bytes類型,這種bytes類型可以通過decode()來重新轉為unicode。
使用相似的觀點來表述Python3中的bytes和str的區別就是:
bytes is text representation in bytes only if you know the charset, str is text representation in unicode characters(or unicode bytes).


