
Redis給人的印象是簡單、很快,但是不代表它不需要關註它的性能指標,此文簡單地介紹了一部分Redis性能指標.翻譯過程中加入了自己延伸的一些疑問信息,仍然還有一些東西沒有完全弄明白。原文中Metric to watch *** 和 Metric to alert on ***這裡翻譯為需要觀察的指 ...
Redis給人的印象是簡單、很快,但是不代表它不需要關註它的性能指標,此文簡單地介紹了一部分Redis性能指標.
翻譯過程中加入了自己延伸的一些疑問信息,仍然還有一些東西沒有完全弄明白。
原文中Metric to watch *** 和 Metric to alert on ***這裡翻譯為需要觀察的指標和需要告警的指標,不知道合不合適。
原文出處:https://www.datadoghq.com/blog/how-to-monitor-redis-performance-metrics/
以下為部分譯文:
監控Redis可以幫助解決兩個方面的問題:Redis本身的資源問題,以及基礎架構中其他方面出現的問題。 在本文中,我們將介紹以下每個類別中最重要的Redis指標:
性能指標: Performance metrics
記憶體指標: Memory metrics
基本活動指標: Basic activity metrics
持久性指標: Persistence metrics
錯誤指標: Error metrics
1.性能指標:Performance metrics
除錯誤率低外,良好的性能是系統健康狀況的最佳頂級指標之一。性能不佳通常是由記憶體問題引起的,如記憶體部分所述。
| Name | Description | Type |
| latency | Redis響應一個請求的時間 Average time for the Redis server to respond to a request |
Performance |
| instantaneous_ops_per_sec | 平均每秒處理請求總數 Total number of commands processed per second |
Throughput |
| hit rate (calculated) | 緩存命中率(計算出來的) keyspace_hits / (keyspace_hits + keyspace_misses) |
Success |
1.1需要告警的指標: latency(延遲)
延遲是客戶端請求與實際伺服器響應之間的時間的度量。跟蹤延遲是檢測Redis性能變化的最直接方法。
由於Redis的單線程特性,異常情況下的延遲可能會導致嚴重的瓶頸。一個請求的長響應時間會增加所有後續請求的延遲。
一旦確定延遲是一個問題,您可以採取一些措施來診斷和解決性能問題。請參閱白皮書“瞭解前5個Redis性能指標”中的第14頁的“使用延遲命令提高性能”一節。

譯者註:哪些因素會引起延遲?
1,slowlog 慢查詢引起的延遲
slowlog-log-slower-than: 慢查詢時間閾值,超過這個閾值的查詢將會被記錄,預設值10000,但是微妙,也即10毫秒。 slowlog-max-len:慢查詢日誌最大條數,預設值128,先進先出的隊列的形式記錄在記憶體中。 slowlog-get n:獲取前n條慢查詢日誌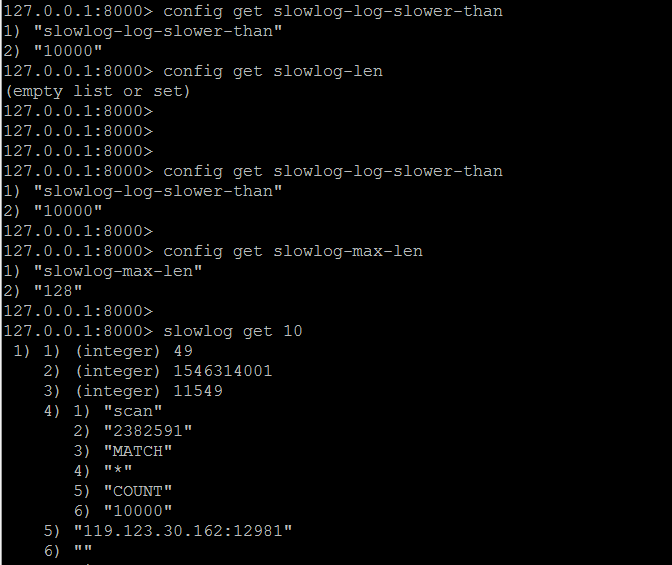
2,網路延遲
redis-cli --latency 命令用來檢測網路延遲,輸出的時間單位為毫秒,它通過Redis PING命令測量Redis伺服器響應的時間(以毫秒為單位)來實現這一點。
redis-cli --latency -h 127.0.0.1 -p
![]()
對於以上返回信息的含義,參考:https://stackoverflow.com/questions/27735411/understanding-latency-using-redis-cli
在此上下文中,延遲是客戶機發出命令到客戶機接收到對命令的響應之間的最大延遲。通常Redis處理時間非常低,在亞微秒範圍內,但是有一些條件會導致更高的延遲數字。
What's (1815samples)? 這是redis-cli記錄發出PING命令並接收響應的次數。換句話說,這是採樣數據。在當前示例中,記錄了1815個請求和響應。
What's min: 0? 最小值表示CLI發出PING的時間到收到回覆的時間之間的最小延遲。換句話說,這是來自採樣數據的最佳響應時間。
What's max: 15? 最大值表示CLI發出PING信號到收到命令的響應之間的最大延遲。這是來自採樣數據的最長響應時間。在我們1815個示例中,最長的事務花費了1ms。
What's avg: 0.12? avg值是所有採樣數據的平均響應時間(以毫秒為單位)。平均而言,個個樣本的響應時間是0.12毫秒。
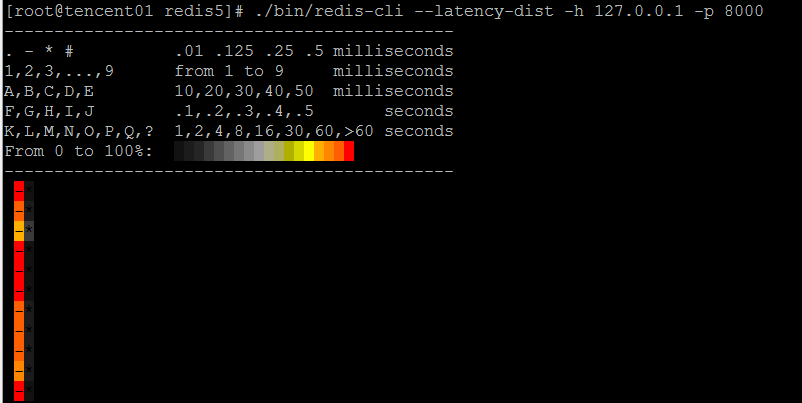
redis-cli --latency-history,以分段的形式展現Redis延遲

redis-cli --latency-dist,以圖表的形式展現Redis延遲,這個圖表的結果看不怎麼懂
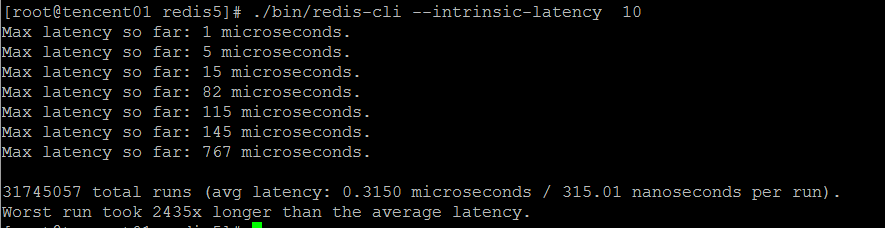
3,Intrinsic latency 固有延遲
顧名思義,任何請求響應都要經過代碼的處理,必然有延遲,Intrinsic latency是Redis自身處理指令需要消耗的時間,這部分時間耗費無法避免。
當然Intrinsic latency的延遲非常低,在微妙級別
如何檢測延遲?
參考:https://blog.csdn.net/dc_726/article/details/47699739,http://www.redis.cn/topics/latency-monitor.html
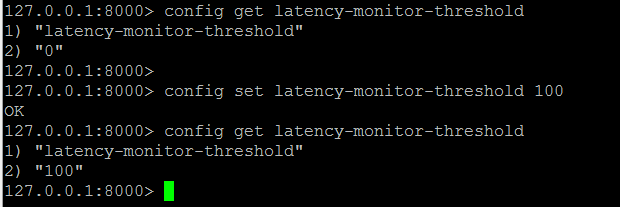
CONFIG SET latency-monitor-threshold 100
延遲檢測模式是關閉的,可以通過配置打開延遲監控
打開延遲監控後,人為製造一個產生高延遲的save操作指令,通過latency latest觀測延遲信息
latency latest:四列分別表示事件名、最近延遲的Unix時間戳、最近的延遲(毫秒)、最大延遲(毫秒)。
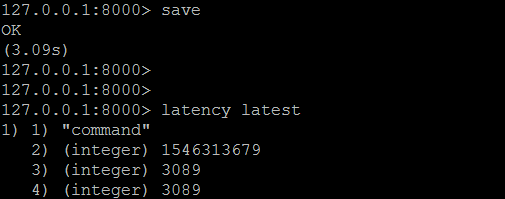
latency 可以通過以下參數檢測延遲信息
LATEST:四列分別表示事件名、最近延遲的Unix時間戳、最近的延遲、最大延遲。
HISTORY:延遲的時間序列。可用來產生圖形化顯示或報表。
GRAPH:以圖形化的方式顯示。最下麵以豎行顯示的是指延遲在多久以前發生。
RESET:清除延遲記錄。
1.2需要觀察的指標:instantaneous_ops_per_sec
跟蹤處理的命令吞吐量對於診斷Redis實例中的高延遲原因至關重要。
高延遲可能是由許多問題引起的,從積壓命令隊列到慢速命令,再到網路過度使用。
可以通過測量每秒處理的命令數來進行診斷 - 如果它相對比較平穩,則原因不是計算密集型命令(Redis本身引起的)。
如果一個或多個慢速命令導致延遲問題,您將看到每秒的命令數量完全下降或停止。
與歷史基線相比,每秒處理的命令數量的下降可能是低命令量或阻塞系統的慢命令的標誌。
1.OPS較低可能是正常的,或者它可能表示上游存在問題(譯者註:表示Redis本身被負載量較低)。
2.有關慢速命令的詳細信息,請參閱第2部分,瞭解有關收集Redis指標的信息。

譯者註:如何獲取Redis的OPS
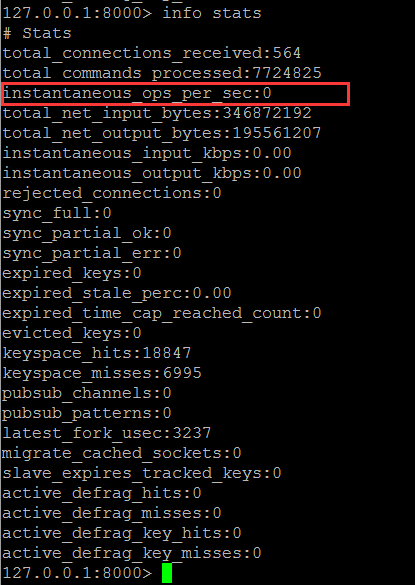
1.3Metric to watch: hit rate
使用Redis作為緩存時,監視緩存命中率可以告訴您緩存是否被有效使用。命中率低意味著客戶端正在尋找不再存在(Redis記憶體中)的Key值。
Redis不直接提供命中率指標。我們仍然可以像這樣計算:
HitRate=keyspace_hits/(keyspace_hits+keyspace_misses)
低緩存命中率可能由許多因素引起,包括數據到期和分配給Redis的記憶體不足(這可能導致key值被清除)。
低命中率可能會導致應用程式延遲增加,因為它們必須從較慢的備用資源中獲取數據。
譯者註:如何獲取Redis的keyspace_hits+keyspace_misses,同樣是info stats
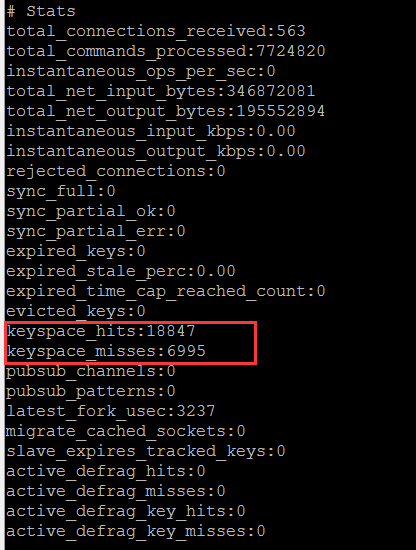
2.Memory metrics
| Name | Description | Type |
| used_memory | 已使用記憶體 Amount of memory (in bytes) used by Redis |
Utilization |
| mem_fragmentation_ratio | 記憶體碎片率 Ratio of memory allocated by the operating system to memory requested by Redis |
Saturation |
| evicted_keys | 由於最大記憶體限制被移除的key的數量 Number of keys removed due to reaching the maxmemory limit |
Saturation |
| blocked_clients | 由於BLPOP, BRPOP, or BRPOPLPUSH而備阻塞的客戶端 Number of keys removed due to reaching the maxmemory limit |
Other |
2.1需要註意的指標: used_memory
記憶體使用是Redis性能的關鍵組成部分。
如果實例超過可用記憶體(used_memory > total available memory),操作系統將開始交換老的/未使用的部分記憶體(pages),將該部分pages寫入磁碟,為較新/活動頁騰出記憶體空間。
每個交換的部分都寫入磁碟,嚴重影響性能。從磁碟寫入或讀取速度比寫入或從存儲器讀取速度慢5個數量級(100,000)(記憶體為0.1μs,磁碟為10 ms)。
可以將Redis配置為僅限於指定的記憶體量。在redis.conf文件中設置maxmemory指令可以直接控制Redis的記憶體使用情況。
啟用maxmemory需要您為Redis配置驅逐(過期)策略以確定它應如何釋放記憶體。
當Redis用作緩存時,這種“扁平線”模式很常見;消耗掉所有可用記憶體,並以與插入新數據相同的速率清理舊數據。
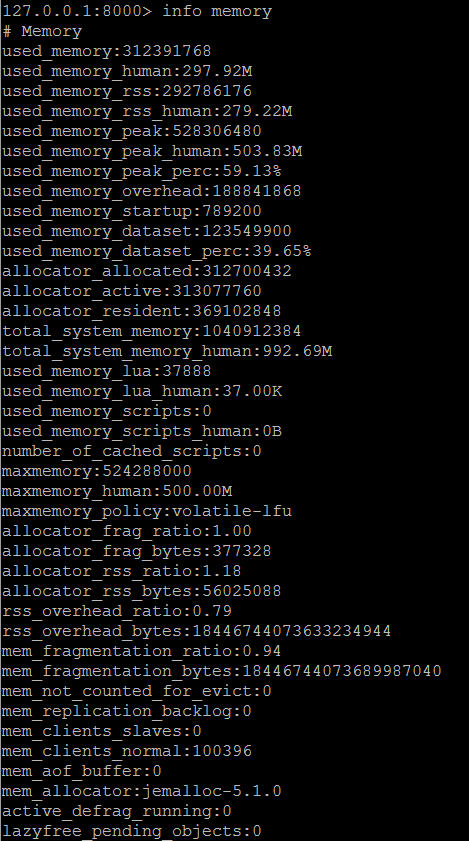
譯者註:關於Redis的記憶體參數 info memory
used_memory和used_memory_human都是Redis使用到的記憶體,used_memory_human是一更加可讀性的方式展示Redis的記憶體使用
used_memory_rss和used_memory_rss_human 表示操作系統為Redis進程分配的記憶體總量,兩者的含義類似如上。
為什麼會出現Redis使用的記憶體大於操作系統給Redis分配的記憶體,參考https://stackoverflow.com/questions/44385820/redis-used-memory-is-largger-than-used-memory-rss
used_memory being < used_memory_rss意味著記憶體碎片的存在。
used_memory > used_memory_rss 意味著物理記憶體不足,發生了記憶體swap。
2.2 需要告警的指標: mem_fragmentation_ratio
mem_fragmentation_ratio度量標準給出了操作系統看到的記憶體與Redis分配的記憶體的比率。
MemoryFragmentationRatio =Used_Memory_RSS(Used_Memory)
操作系統負責為每個進程分配物理記憶體。操作系統的虛擬記憶體管理器處理由記憶體分配器調解的實際映射。
如果Redis實例的記憶體占用為1GB,記憶體分配器將首先嘗試找到一個連續記憶體段來存儲數據。如果沒有找到連續的段,分配器必須將進程的數據劃分為多個段,從而導致記憶體開銷的增加。
跟蹤碎片比率對於瞭解Redis實例的性能非常重要。
碎裂率大於1表示發生碎片。比率超過1.5表示碎片過多,Redis實例占用了所請求的物理記憶體的150%。
碎片率低於1會告訴您Redis需要的記憶體比系統上可用的記憶體多,這會導致交換。交換到磁碟將導致延遲顯著增加(請參閱已用記憶體)。
理想情況下,操作系統會在物理記憶體中分配一個連續的段,碎片比率等於1或稍大一些。
1,如果您的伺服器的碎片率高於1.5,則重新啟動Redis實例將允許操作系統恢復以前因碎片而無法使用的記憶體。在這種情況下,作為通知的警報可能就足夠了。
2,如果Redis伺服器的碎片比率低於1,則可能需要以發出告警,以便快速增加可用記憶體或減少記憶體使用量。
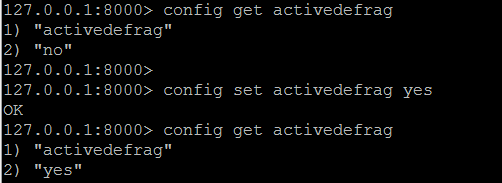
從Redis 4開始,當Redis配置為使用包含的jemalloc副本時,可以使用新的活動碎片整理功能。
可以將此工具配置為在碎片達到特定級別時啟動,並開始將值複製到連續的記憶體區域並釋放舊副本,從而減少伺服器運行時的碎片。
譯者註,info memory可以查看記憶體碎片信息

配置文件中增加activedefrag yes選項,不用重啟的方式自動重整記憶體碎片。
2.3需要告警的指標:evicted_keys(僅限緩存)
如果您使用Redis作為緩存,可能將其配置為在達到maxmemory限制時(按照某種方式)自動清除key值。
如果您使用Redis作為資料庫或隊列,可能需要交換而不是清除key值,在這種情況下,因此可以跳過此指標。
跟蹤key值清理指標非常重要,因為Redis按順序處理每個操作,這意味著驅逐大量key可以降低命中率,從而增加延遲時間。
如果您使用TTL,您可能不會期望清理key值。在這種情況下,如果此指標始終高於零,您可能會看到實例中的延遲增加。
大多數不使用TTL的其他配置最終會耗盡記憶體並開始清理key值。只要您的響應時間可以接受,就可以接受穩定的清除率。
您可以使用以下命令配置key值過期策略:
config set maxmemory-policy = ***
其中policy是以下之一:
noeviction-----------------------當達到記憶體限制並且用戶嘗試添加其他鍵時,將返回錯誤(也就是說達到記憶體限制之後不允許寫入)
volatile-lru-----------------------在已過期的key值中,刪除最近最少使用的key值
volatile-ttl------------------------在已過期的key值中,刪除最短過期時間的key值
volatile-random-----------------在已過期的key值中,隨機刪除key值
allkeys-lru-----------------------從所有key值中刪除最近最少使用的key
allkeys-random-----------------從所有key值中隨機刪除
volatile-lfu-----------------------在Redis 4中新增選項,在已過期的key值中,“最近最不常用”的key值
allkeys-lfu-----------------------在Redis 4中新增選項,從所有key值中,刪除“最近最不常用”的key值
註意:出於性能原因,當使用LRU,TTL或Redis 4的LFU策略時,Redis實際上不會從整個key值集進行採樣。
Redis首先對key值集的隨機子集進行採樣,然後對樣本應用清理策略。
通常,Redis的較新(> = 3)版本採用LRU採樣策略,該策略更接近真實LRU。
例如,可以通過設置必須經過多少時間而無需訪問項目在排名中向下移動來調整LFU策略。有關更多詳細信息,請參閱Redis的文檔。
譯者註:
關於LRU和LFU,分別是最近最少使用和最近最不頻繁使用,LFU理論上是比LRU更加合理的演算法,清理key的時候,LFU認為“最近最不頻繁”使用要比“最近最少”使用更加合理。
LRU和LFU的區別:
LRU是最近最少使用頁面置換演算法(Least Recently Used),也就是首先淘汰最長時間未被使用的頁面!
LFU是最近最不常用頁面置換演算法(Least Frequently Used),也就是淘汰一定時期內被訪問次數最少的頁!
2.4 需要註意的指標: blocked_clients
Redis提供了許多在List上運行的阻塞命令。
BLPOP,BRPOP和BRPOPLPUSH分別是命令LPOP,RPOP和RPOPLPUSH的阻塞變體。
當List非空時,命令按預期執行。但是,當List為空時,阻塞命令將一直等到源被填充或達到超時。
等待數據的被阻止客戶端數量的增加可能是一個麻煩的跡象。
延遲或其他問題可能會阻止源列表被填充。雖然被阻止的客戶端本身不會引起警報,但如果您看到此指標的值始終為非零值,則應該引起註意。
3. 基本活動指標
| Name | Description | Type |
| connected_clients | 客戶端連接數 Number of clients connected to Redis |
Utilization |
| connected_slaves | Slave數量 Number of slaves connected to current master instance |
Other |
| master_last_io_seconds_ago | 最近一次主從交互之後的秒數 Number of slaves connected to current master instance |
Other |
| keyspace | 資料庫中的key值總數 Total number of keys in your database |
Utilization |
3.1 需要告警的指標: connected_clients
由於對Redis的訪問通常由應用程式發起(用戶通常不直接訪問資料庫),因此對於大多數場景,連接客戶端的數量將有合理的上限和下限。
如果數字偏離正常範圍,這表示可能存在問題。
如果它太低,表示客戶端連接可能已經丟失,如果它太高,大量的併發客戶端連接可能會打垮伺服器處理請求的能力。
無論如何,客戶端連接始終是有限的資源 - 無論是通過操作系統,Redis的配置還是網路限制。
監視客戶端連接可幫助您確保有足夠的可用資源用於新客戶端或管理會話。
譯者註:查看Redis的最大連接數,這個配置相當於MySQL的變數(show variables ***),是一個不隨Redis服務負載改變的值,因此不在info中查看。
![]()
3.2需要告警的指標: connected_slaves
如果您的資料庫是大量讀取的,那麼您可能正在使用Redis中提供的主從資料庫複製功能。
在這種情況下,監控連接的從站數量是關鍵。如果連接的從站數量意外更改,則可能表示主機已關閉或從站實例出現問題。

註意:在上圖中,Redis Master將顯示它有兩個連接的slave,並且每個slave都有兩個slave。
由於slave的slave不直接連接到Redis Master,因此它們不包含在Redis Master的connected_slaves中。
3.3需要告警的指標: master_last_io_seconds_ago
使用Redis的複製功能時,slave會定期檢查其主伺服器。主從長時間沒有通信的可能表示主從Redis實例之間存在問題。並且冒著slave中數據在master中已經發生了變化危險。
由於Redis執行同步的方式,最大限度地減少主從通信的中斷至關重要。當從設備在中斷後重新連接到master時,它會發送PSYNC命令以嘗試僅同步中斷期間丟失的命令。
如果無法做到這一點,則從站將請求完整的SYNC,這會迫使master立即開始執行background save命令,同時新增加的命令會被緩衝起來。
當background save命令執行完成時,數據與緩衝的命令一起發送到客戶端。每次從機執行SYNC時,都會導致主實例上的延遲顯著增加。
3.4需要註意的指標: keyspace
跟蹤資料庫中的鍵數通常是個好主意。作為記憶體數據存儲,key值集合空間越大,為了確保性能,Redis需要的物理記憶體越多。
Redis將繼續添加key值,直到它達到maxmemory limit,然後它開始以相同的速率清理key值。這會產生一個“扁平線”圖,如上圖所示。
如果您使用Redis作為緩存並查看key值空間飽和度 - 如上圖所示 - 加上命中率較低,您可能會讓客戶端請求舊的或已逐出的數據。隨著時間的推移跟蹤keyspace_misses數量將幫助您查明原因。
或者,如果使用Redis作為資料庫或隊列,則可能不選擇volatile策略。
隨著key值空間的增長,如果可能的話,您可能需要考慮在添加物理記憶體或在主機之間拆分數據集。
添加更多記憶體是一種簡單有效的解決方案。如果單機資源有限,則對數據進行分區或分片可以合併許多電腦的資源。
有了分區計劃,Redis可以存儲更多key值集合而無需清理或swap。但是,分片比增加記憶體要困難得多。
值得慶幸的是,Redis文檔中有一個關於使用Redis實例實現分區方案的重要部分,請在此處閱讀更多內容。
譯者註:Redis的keyspace信息

4.持久化指標
Redis需要啟用持久性配置,尤其是在使用Redis的複製功能時。
如果您使用Redis作為緩存,或者在數據丟失無關緊要的用例中,則可能不需要持久性。
| Name | description | Type |
| rdb_last_save_time | 最後一次持久化保存到磁碟的Unix時間戳 Unix timestamp of last save to disk |
other |
| rdb_changes_since_last_save | 自最後一次持久化以來資料庫的更改數 | other |
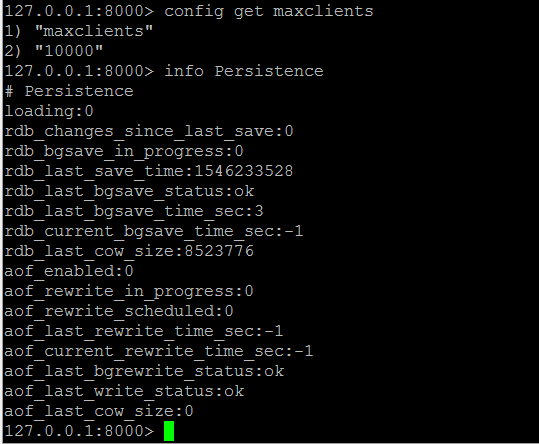
4.1 需要註意的指標: rdb_last_save_time and rdb_changes_since_last_save
通常,關註數據集的波動性是個好主意。寫入磁碟之間的時間間隔過長可能會在伺服器發生故障時導致數據丟失。
在上次保存時間和故障時間之間對數據集所做的任何更改都將丟失。
監控rdb_changes_since_last_save可讓您更深入地瞭解數據的波動性。如果您的數據集在該間隔內沒有太大變化,則寫入之間的長時間間隔不是問題。
跟蹤這兩個指標可以讓您清楚地瞭解在給定時間點發生故障時您將丟失多少數據。
譯者註:如何查看Redis的rdb_last_save_time and rdb_changes_since_last_save
info Persistence
5.Error metrics
Redis錯誤指標可以提醒您註意異常情況。以下指標可跟蹤常見錯誤:
| Name | Description | Type |
| rejected_connections | 由於達到maxclient限制而被拒絕的連接數 number of connections rejected due to hitting maxclient limit |
Saturation |
| keyspace_misses | Key值查找失敗(沒有命中)次數 number of failed lookups of keys |
Errors / Other |
| master_link_down_since_seconds | 主從斷開的持續時間(以秒為單位) time in seconds of the link between master and slave being down |
Errors |
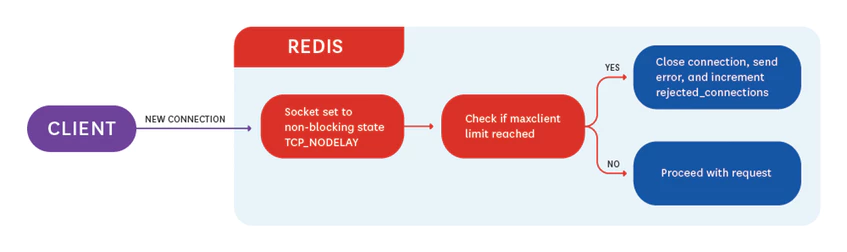
5.1需要告警的指標: rejected_connections
Redis能夠處理許多活動連接,預設情況下可以使用10,000個客戶端連接。
可以通過更改redis.conf中的maxclient指令將最大連接數設置為不同的值。
如果您的Redis實例當前處於其最大連接數,則將斷開任何新的連接嘗試。
請註意,Redis可能不支持使用maxclient指令請求的連接數。
Redis檢查內核以確定可用文件描述符的數量。如果可用文件描述符的數量小於maxclient + 32(Redis為其自己使用保留32個文件描述符),則忽略maxclient指令並使用可用文件描述符的數量。
有關Redis如何處理客戶端連接的更多信息,請參閱有關redis.io的文檔。
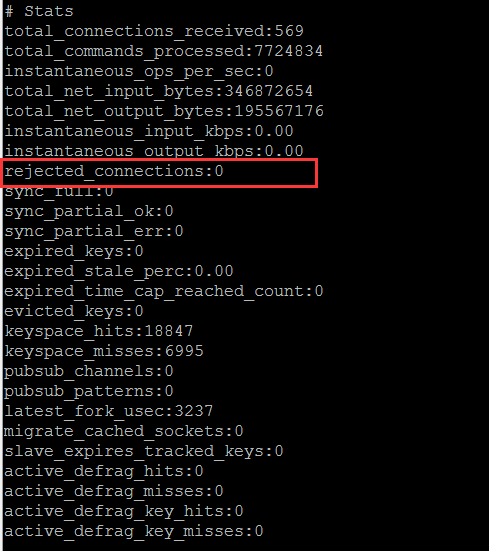
譯者註:rejected_connections可以通過查看Info stat
5.2需要告警的指標: keyspace_misses
每次Redis查找key時,只有兩種可能的結果:key存在,或key不存在。
查找不存在的鍵會導致keyspace_misses計數器遞增,因此keyspace_misses意味著客戶端嘗試在資料庫中查找不存在的密key。
如果您不使用Redis作為緩存,則keyspace_misses應該為零或接近零。請註意,調用阻塞的任何阻塞操作(BLPOP,BRPOP和BRPOPLPUSH)都將導致keyspace_misses遞增。
譯者註:keyspace_misses可以通過查看Info stat
5.3需要告警的指標: master_link_down_since_seconds
該指標僅在主從之間的連接丟失時可用。
理想情況下,此值不應超過零-主從之間保持持續通信,以確保slave不提供過時數據。
應該解決連接之間的大的時間間隔。請記住,重新連接後,您的主Redis實例將需要投入資源來更新從站上的數據,這可能會導致延遲增加。
總結
在這篇文章中,我們提到了一些最有用的指標,您可以監控這些指標以密切關註您的Redis伺服器。
如果您剛剛開始使用Redis,那麼監控下麵列表中的指標將提供對資料庫基礎結構的運行狀況和性能的良好可見性:
Number of commands processed per second
Latency
Memory fragmentation ratio
Evictions
Rejected clients
最終,您將認識到與您自己的設備和用例特其他指標。當然,您監控的內容取決於您擁有的工具和可用的指標。有關收集Redis指標的分步說明,請參閱隨附文章。

