
前言 介紹java的常用集合+各個集合使用用例 歡迎轉載,請註明作者和出處哦☺ 參考: 1,《Java核心編程技術(第二版)》 2, "http://www.cnblogs.com/LittleHann/p/3690187.html" java 集合基本概念 在《Java核心編程技術(第二版 ...
前言
介紹java的常用集合+各個集合使用用例
歡迎轉載,請註明作者和出處哦☺參考:
1,《Java核心編程技術(第二版)》
2, http://www.cnblogs.com/LittleHann/p/3690187.html
java 集合基本概念
在《Java核心編程技術(第二版)》中是這樣介紹java集合的:
java中的集合框架提供了一套設計優良的介面和類,使程式員操作成批的數據或對象元素極為方便。這些介面和類有很多對抽象數據類型操作的API,這是我們常用的且在數據結構中熟知的,例如:Maps,Sets,Lists,Arrays等,並且Java用面向對象的設計對這些數據結構和演算法進行了封裝,這極大地減輕了程式員編程時的負擔。程式員也可以以這個集合框架為基礎,定義更高級別的數據抽象,比如棧,隊列和線程安全的集合等,從而滿足自己的需要。
在日常編程中,經常需要對多個數據進行存儲。從傳統意義上講,數組是一個很好的選擇,但是一個數組經常需要指定好長度,且這個長度是不可變得。這時我們需要一個可以動態增長的“數組”,而java的集合類就是一個很好的設計方案。
java的集合框架可以簡化為如下圖所示(本圖來自於《Java核心編程技術(第二版)》):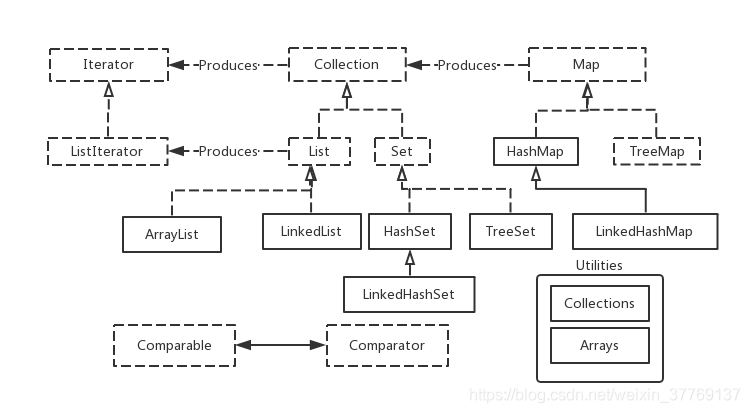
再細化後變為:
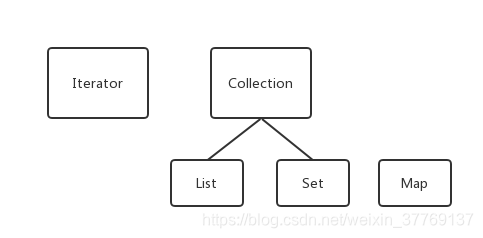
從上圖中,我們可以看出java集合框架主要提供三種類型的集合(Set,List,Map)和一個迭代器。
Set 集合
- Set集合中的對象無排列順序,且沒有重覆的對象。可以把Set集合理解為一個口袋,往裡面丟的對象是無順序的。
- 對Set集合中成員的訪問和操作是通過對集合中對象的引用進行的,所以Set集合不能有重覆對象(包括Set的實現類)。
- Set判斷集合中兩個對象相同不是使用"=="運算符,而是根據equals方法。每次加入一個新對象時,如果這個新對象和當前Set中已有對象進行equals方法比較都返回false時,則允許添加對象,否則不允許。
Set集合的主要實現類:
- HashSet:按照哈希演算法來存儲集合中的對象,速度較快。
- LinkedHashSet:不僅實現了哈希演算法,還實現了鏈表的數據結構,提供了插入和刪除的功能。當遍歷LinkedHashSet集合里的元素時,LinkedHashSet將會按元素的添加順序來訪問集合里的元素。
- TreeSet:實現了SortedSet介面(此介面主要用於排序操作,即實現此介面的子類都屬於排序的子類)。
- EnumSet:專門為枚舉類設計的有序集合類,EnumSet中所有元素都必須是指定枚舉類型的枚舉值,該枚舉類型在創建EnumSet時顯式、或隱式地指定。
Set 集合應用場景
hashSet場景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
HashSet books = new HashSet();
//分別向books集合中添加兩個A對象,兩個B對象,兩個C對象
books.add(new A());
books.add(new A());
books.add(new B());
books.add(new B());
books.add(new C());
books.add(new C());
System.out.println(books);
}
}
//類A的equals方法總是返回true,但沒有重寫其hashCode()方法。不能保證當前對象是HashSet中的唯一對象
class A {
@Override
public boolean equals(Object obj) {
return true;
}
}
//類B的hashCode()方法總是返回1,但沒有重寫其equals()方法。不能保證當前對象是HashSet中的唯一對象
class B {
@Override
public int hashCode() {
return 1;
}
}
//類C的hashCode()方法總是返回2,且有重寫其equals()方法
class C
{
public int hashCode()
{
return 2;
}
public boolean equals(Object obj)
{
return true;
}
}輸出結果:
[B@1, B@1, A@1b28cdfa, C@2, A@65ab7765]可以看到,當兩個對象equals()方法比較返回true時(即兩個對象的equals相同),但hashCode()方法返回不同的hashCode值時,對象可以添加成功(集合中有兩個A對象)。如果兩個對象的hashCode相同,但是它們的equlas返回值不同,HashSet會在這個位置用鏈式結構來保存多個對象(B@1, B@1)。而HashSet訪問集合元素時也是根據元素的HashCode值來快速定位的。
可以看出,HashSet集合通過hashCode()採用hash演算法來決定元素的存儲位置,如上輸出的(B,B)和(A,A),但是這並不符合Set集合沒有重覆的對象的規則,所以如果需要把某個類的對象保存到HashSet集合時,在重寫這個類的equlas()方法和hashCode()方法時,應該儘量保證兩個對象通過equals()方法比較返回true時,它們的hashCode()方法返回值也相等。
LinkedHashSet場景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
HashSet hashSet = new HashSet();
hashSet.add("hello");
hashSet.add("world");
hashSet.add("hashSet");
//輸出:[world, hashSet, hello]
System.out.println(hashSet);
LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add("Hello");
linkedHashSet.add("World");
linkedHashSet.add("linkedHashSet");
//輸出:[Hello, World, linkedHashSet]
System.out.println(linkedHashSet);
//刪除 Hello
linkedHashSet.remove("Hello");
//重新添加 Hello
linkedHashSet.add("Hello");
//輸出:[World, linkedHashSet, Hello]
System.out.println(linkedHashSet);
//再次添加 Hello
linkedHashSet.add("Hello");
//輸出:[World, linkedHashSet, Hello]
System.out.println(linkedHashSet);
}
}可以看出,linkedHashSet最大的特點就是有排序(以元素添加的順序)。同時,linkedHashSet作為HashSet的子類且實現了Set介面,所以不允許集合元素重覆。
TreeSet場景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
TreeSet treeSet = new TreeSet();
//添加四個Integer對象
treeSet.add(9);
treeSet.add(6);
treeSet.add(-4);
treeSet.add(3);
//輸出:[-4, 3, 6, 9](集合元素自動排序)
System.out.println(treeSet);
//輸出:-4
System.out.println(treeSet.first()); //輸出集合里的第一個元素
//輸出:9
System.out.println(treeSet.last()); //輸出集合里的最後一個元素
//輸出:[-4, 3]
System.out.println(treeSet.headSet(6)); //返回小於6的子集,不包含6
//輸出:[3, 6, 9]
System.out.println(treeSet.tailSet(3)); //返回大於3的子集,包含3
//輸出:[-4, 3]
System.out.println(treeSet.subSet(-4 , 6)); //返回大於等於-4,小於6的子集
}
}可以看出TreeSet會自動排序好存入的數據。TreeSet採用紅黑樹的數據結構來存儲集合元素,支持兩種排序方式: 自然排序、定製排序。
- 自然排序:調用集合元素的compareTo(Object obj)方法來比較元素之間的大小關係,然後將集合元素按升序排序。如果試圖把一個對象添加到TreeSet時,則該對象的類必須實現Comparable介面,否則程式會拋出異常。
- 定製排序:TreeSet的自然排序是根據集合元素的大小,TreeSet將它們以升序排序。如果我們需要實現定製排序,則可以通過Comparator介面里的int compare(T o1, T o2)方法,該方法用於比較大小。
如下為定製排序實例:
public class MyCollectionsDemo {
public static void main(String[] args)
{
TreeSet treeSet = new TreeSet(new Comparator()
{
//根據M對象的age屬性來決定大小
public int compare(Object o1, Object o2)
{
M m1 = (M)o1;
M m2 = (M)o2;
return m1.age > m2.age ? -1
: m1.age < m2.age ? 1 : 0;
}
});
treeSet.add(new M(5));
treeSet.add(new M(-3));
treeSet.add(new M(9));
System.out.println(treeSet);
}
}
class M
{
int age;
public M(int age)
{
this.age = age;
}
public String toString()
{
return "M[age:" + age + "]";
}
}TreeSet總結
- 當把一個對象加入TreeSet集合時,TreeSet會調用該對象的compareTo(Object obj)方法與容器中的其他對象比較大小,然後根據紅黑樹結構找到它的存儲位置(如果兩個對象通過compareTo(Object obj)方法比較相等,則添加失敗)。
- 自然排序、定製排序、Comparator決定的是誰大的問題,即按什麼順序(升序、降序)進行排序。
EnumSet場景:
enum SeasonEnum
{
SPRING,SUMMER,FALL,WINTER
}
public class MyCollectionsDemo {
public static void main(String[] args)
{
//allOf:集合中的元素就是SeasonEnum枚舉類的全部枚舉值
EnumSet es1 = EnumSet.allOf(SeasonEnum.class);
//輸出:[SPRING,SUMMER,FALL,WINTER]
System.out.println(es1);
//noneOf:指定SeasonEnum類的枚舉值。
EnumSet es2 = EnumSet.noneOf(SeasonEnum.class);
//輸出:[]
System.out.println(es2);
//手動添加兩個元素
es2.add(SeasonEnum.WINTER);
es2.add(SeasonEnum.SPRING);
//輸出:[SPRING,WINTER](EnumSet會自動排序)
System.out.println(es2);
//of:指定枚舉值
EnumSet es3 = EnumSet.of(SeasonEnum.SUMMER , SeasonEnum.WINTER);
//輸出:[SUMMER,WINTER]
System.out.println(es3);
}
}Set 集合總結
1) HashSet的性能比TreeSet好(包括添加、查詢元素等操作),因為TreeSet需要額外的紅黑樹演算法來維護集合元素的次序。
當需要一個始終保持排序的Set時,才使用TreeSet,否則使用HashSet。
2) 對於LinkedHashSet,普通的插入、刪除操作比HashSet要略慢一點,因為維護鏈表會帶來的一定的開銷。好處是,遍歷比HashSet會更快
3) EnumSet是所有Set實現類中性能最好的。
4) HashSet、TreeSet、EnumSet都是"線程不安全"的,可以通過Collections工具類的synchronizedSortedSet方法來"包裝"該Set集合。
SortedSet s = Collections.synchronizedSortedSet(new TreeSet(...));
List 集合
- 集合中的對象按照索引的順序排序,可以有重覆的對象。List與數組相似。
- List以線型方式存儲,預設按元素的添加順序設置元素的索引。
Set集合的主要實現類:
- ArrayList:可以理解為長度可變的數組。可以對集合中的元素快速隨機訪問,但是做插入或刪除操作時效率較低。
- LinkedList:使用鏈表的數據介面。與ArrayList相反,插入或刪除操作時速度快,但是隨機訪問速度慢。同時實現List介面和Deque介面,能對它進行隊列操作,即可以根據索引來隨機訪問集合中的元素,也能將LinkedList當作雙端隊列使用,自然也可以被當作"棧來使用(可以實現“fifo先進先出,filo後入先出”)
List 集合應用場景
ArrayList場景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
List list = new ArrayList();
//添加三個元素
list.add(new String("list第一個元素"));
list.add(new String("list第二個元素"));
list.add(new String("list第三個元素"));
//輸出:[list第一個元素, list第二個元素, list第三個元素]
System.out.println(list);
//在list第二個位置插入新元素
list.add(1 , new String("在list第二個位置插入的元素"));
for (int i = 0 ; i < list.size() ; i++ )
{
/**
* 輸出:
* list第一個元素
* 在list第二個位置插入的元素
* list第二個元素
* list第三個元素
*/
System.out.println(list.get(i));
}
//刪除第三個元素
list.remove(2);
//輸出:[list第一個元素, 在list第二個位置插入的元素, list第三個元素]
System.out.println(list);
//判斷指定元素在List集合中位置:輸出1,表明位於第二位
System.out.println(list.indexOf(new String("在list第二個位置插入的元素")));
//將第二個元素替換成新的字元串對象
list.set(1, new String("第二個元素替換成新的字元串對象"));
//輸出:[list第一個元素, 第二個元素替換成新的字元串對象, list第三個元素]
System.out.println(list);
//將list集合的第二個元素(包括)~到第三個元素(不包括)截取成子集合
//輸出:[第二個元素替換成新的字元串對象]
System.out.println(list.subList(1 , 2));
}
}
LinkedList場景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
LinkedList linkedList = new LinkedList();
//將字元串元素加入隊列的尾部(雙端隊列)
linkedList.offer("隊列的尾部");
//將一個字元串元素加入棧的頂部(雙端隊列)
linkedList.push("棧的頂部");
//將字元串元素添加到隊列的頭(相當於棧的頂部)
linkedList.offerFirst("隊列的頭");
for (int i = 0; i < linkedList.size() ; i++ )
{
/**
* 輸出:
* 隊列的頭
* 棧的頂部
* 隊列的尾部
*/
System.out.println(linkedList.get(i));
}
//訪問、並不刪除棧頂的元素
//輸出:隊列的頭
System.out.println(linkedList.peekFirst());
//訪問、並不刪除隊列的最後一個元素
//輸出:隊列的尾部
System.out.println(linkedList.peekLast());
System.out.println("end");
//將棧頂的元素彈出"棧"
//輸出:隊列的頭
System.out.println(linkedList.pop());
//下麵輸出將看到隊列中第一個元素被刪除
//輸出:[棧的頂部, 隊列的尾部]
System.out.println(linkedList);
//訪問、並刪除隊列的最後一個元素
//輸出:隊列的尾部
System.out.println(linkedList.pollLast());
//下麵輸出將看到隊列中只剩下中間一個元素:
//輸出:[棧的頂部]
System.out.println(linkedList);
}
}Map 集合
- Map是一種把鍵對象(key)和值對象(value)進行映射的集合(k-v)。k相當於v的索引,v仍然可以是Map類型(k-v)。
- key和value都可以是任何引用類型的數據。
- Map的key不允許重覆,即同一個Map對象的任何兩個key通過equals方法比較結果總是返回false。
- key集的存儲形式和Set集合完全相同(即key不能重覆)
- value集的存儲形式和List非常類似(即value可以重覆、根據索引來查找)
Map集合的主要實現類:
- HashMap:按照哈希演算法來存取key,有很好的存取性能,和HashSet一樣,要求覆蓋equals()方法和hasCode()方法,同時也不能保證集合中每個key-value對的順序。
- LinkedHashMap:使用雙向鏈表來維護key-value對的次序,該鏈表負責維護Map的迭代順序,與key-value對的插入順序一致。
- TreeMap:一個紅黑樹數據結構,每個key-value對即作為紅黑樹的一個節點。實現了SortedMap介面,能對key進行排序。TreeMap可以保證所有的key-value對處於有序狀態。同樣,TreeMap也有兩種排序方式(自然排序、定製排序)
Map 集合應用場景
Hashtable場景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
Hashtable hashtable = new Hashtable();
hashtable.put(new A(10086) , "hashtable10086");
hashtable.put(new A(10010) , "hashtable10010");
hashtable.put(new A(10011) , new B());
//輸出:{A@2766=hashtable10086, A@271b=B@65ab7765, A@271a=hashtable10010}
System.out.println(hashtable);
//只要兩個對象通過equals比較返回true,Hashtable就認為它們是相等的value。
//由於Hashtable中有一個B對象,
//它與任何對象通過equals比較都相等,所以下麵輸出true。
System.out.println(hashtable.containsValue("測試字元串"));
//只要兩個A對象的count相等,它們通過equals比較返回true,且hashCode相等
//Hashtable即認為它們是相同的key,所以下麵輸出true。
System.out.println(hashtable.containsKey(new A(10086)));
//刪除最後一個key-value對
hashtable.remove(new A(10011));
//通過返回Hashtable的所有key組成的Set集合,
//從而遍歷Hashtable每個key-value對
for (Object key : hashtable.keySet())
{
/**
* 輸出:
* A@2766---->hashtable10086
* A@271a---->hashtable10010
*/
System.out.print(key + "---->");
System.out.print(hashtable.get(key) + "\n");
}
}
}
class A
{
int count;
public A(int count)
{
this.count = count;
}
//根據count的值來判斷兩個對象是否相等。
public boolean equals(Object obj)
{
if (obj == this)
return true;
if (obj!=null && obj.getClass()==A.class)
{
A a = (A)obj;
return this.count == a.count;
}
return false;
}
//根據count來計算hashCode值。
public int hashCode()
{
return this.count;
}
}
class B
{
//重寫equals()方法,B對象與任何對象通過equals()方法比較都相等
public boolean equals(Object obj)
{
return true;
}
}當使用自定義類作為HashMap、Hashtable的key時,如果重寫該類的equals(Object obj)和hashCode()方法,則應保證兩個方法的判斷標準一致(當兩個key通過equals()方法比較返回true時,兩個key的hashCode()的返回值也應該相同)
LinkedHashMap場景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
LinkedHashMap scores = new LinkedHashMap();
scores.put("語文" , 80);
scores.put("英文" , 82);
scores.put("數學" , 76);
//遍歷scores里的所有的key-value對
for (Object key : scores.keySet())
{
/**
* 輸出:
* 語文------>80
* 英文------>82
* 數學------>76
*/
System.out.println(key + "------>" + scores.get(key));
}
}
}LinkedHashMap中的集合排序與插入的順序保持一致
TreeMap場景:
class R implements Comparable
{
int count;
public R(int count)
{
this.count = count;
}
public String toString()
{
return "R[count:" + count + "]";
}
//根據count來判斷兩個對象是否相等。
public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj!=null
&& obj.getClass()==R.class)
{
R r = (R)obj;
return r.count == this.count;
}
return false;
}
//根據count屬性值來判斷兩個對象的大小。
public int compareTo(Object obj)
{
R r = (R)obj;
return count > r.count ? 1 :
count < r.count ? -1 : 0;
}
}
public class MyCollectionsDemo {
public static void main(String[] args)
{
TreeMap treeMap = new TreeMap();
treeMap.put(new R(10010) , "treemap10010");
treeMap.put(new R(-4396) , "treemap-4396");
treeMap.put(new R(10086) , "treemap10086");
//treeMap自動排序
//輸出:{R[count:-4396]=treemap-4396, R[count:10010]=treemap10010, R[count:10086]=treemap10086}
System.out.println(treeMap);
//返回該TreeMap的第一個Entry對象
//輸出:R[count:-4396]=treemap-4396
System.out.println(treeMap.firstEntry());
//返回該TreeMap的最後一個key值
//輸出:R[count:10086]
System.out.println(treeMap.lastKey());
//返回該TreeMap的比new R(2)大的最小key值。
//輸出:R[count:10010]
System.out.println(treeMap.higherKey(new R(2)));
//返回該TreeMap的比new R(2)小的最大的key-value對。
////輸出:R[count:-4396]=treemap-4396
System.out.println(treeMap.lowerEntry(new R(2)));
//返回該TreeMap的子TreeMap
////輸出:{R[count:-4396]=treemap-4396, R[count:10010]=treemap10010}
System.out.println(treeMap.subMap(new R(-5000) , new R(10086)));
}
}Map 集合總結
1) Set和Map的關係十分密切,java源碼就是先實現了HashMap、TreeMap等集合,然後通過包裝一個所有的value都為null的Map集合實現了Set集合類。
2) HashMap和Hashtable的效率大致相同,因為它們的實現機制幾乎完全一樣。但HashMap通常比Hashtable要快一點,因為Hashtable需要額外的線程同步控制
3) TreeMap通常比HashMap、Hashtable要慢(尤其是在插入、刪除key-value對時更慢),因為TreeMap底層採用紅黑樹來管理key-value對
4) 使用TreeMap的一個好處就是: TreeMap中的key-value對總是處於有序狀態,無須專門進行排序操作
結束
歡迎對本文持有不同意見的人在評論中留言,大家一起互相討論,學習進步。
最後祝大家生活愉快,大吉大利!
如果我的文章對您有幫助的話,歡迎給我打賞,生活不易,工作艱苦,您的打賞是是對我最大的支持!
打賞6元,祝您合家幸福,生活安康。
打賞7元,祝您事業有成,實現夢想。
打賞8元,祝您財源滾滾,一生富貴。
。。。
聽說,打賞我的人最後都找到了真愛併進了福布斯排行榜。

- 本文標題:java集合介紹
- 文章作者:我不是陳浩南(Fooss)
- 發佈時間:2018-12-26 22:09 星期三
- 最後更新:2018-12-26 22:09 星期三


