
一.遞歸函數的弊端 遞歸函數雖然編寫時用很少的代碼完成了龐大的功能,但是它的弊端確實非常明顯的,那就是時間與空間的消耗。 用一個斐波那契數列來舉例 import time #@lru_cache(20) def fibonacci(n): if n < 2: return 1 else: retur ...
一.遞歸函數的弊端
遞歸函數雖然編寫時用很少的代碼完成了龐大的功能,但是它的弊端確實非常明顯的,那就是時間與空間的消耗。
用一個斐波那契數列來舉例
import time
#@lru_cache(20)
def fibonacci(n):
if n < 2:
return 1
else:
return fibonacci(n - 1) + fibonacci(n - 2)
t1 = time.time()
print(fibonacci(35))
t2 = time.time()
print(t2 - t1) # 4.007285118103027
t1 = time.time()
print(fibonacci(36))
t2 = time.time()
print(t2 - t1) # 6.479698419570923
前面輸入的數較小,所以算的還算很快,但輸入到35、36來測試時已經要花上好幾秒來計算了,而且36比35計算時間多了兩秒多,可想而知數據再增大後消耗的時間增加的是越來越大的,因為這個遞歸函數的複雜性是O(2**n)
我們想一下這個函數遞歸的原理,流程,發現一個問題,計算fibonacci(35)的時候,是計算fibonacci(34)+fibonacci(33)的和,計算fibonacci(34)時,是計算的fibonacci(33)+fibonacci(32)的和,問題出現了,fibonacci(33)需要計算兩次,那不是重覆了嘛,我們繼續遞歸向下拆分發現,幾乎所有的遞歸函數拆分為兩個函數的和時都會有重覆計算,就想下麵這個圖:
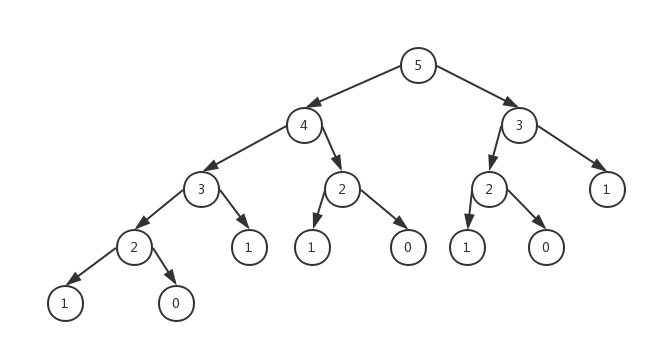
以fibonacci(5)舉例,這個圖裡面有一大部分的數字是重覆的,也就是說執行了很多的重覆的函數,這使我們產生了一個想法,既然重覆執行了,那我讓它直接返回之前執行時的返回值不就行了,至於之前執行時的返回值,給他存起來不就好了嗎,這就用到了我們下麵要說的緩存思想
二.用緩存優化遞歸函數
我們定義一個裝飾器來做函數的緩存
import time
def cache_decorator(func):
cache_dict = {}
def decorator(arg):
try:
return cache_dict[arg]
except KeyError:
return cache_dict.setdefault(arg, func(arg))
return decorator
@cache_decorator
def fibonacci(n):
if n < 2:
return 1
else:
return fibonacci(n - 1) + fibonacci(n - 2)
t1 = time.time()
print(fibonacci(35))
t2 = time.time()
print(t2 - t1) # 0
t1 = time.time()
print(fibonacci(36))
t2 = time.time()
print(t2 - t1) # 0
當使用了緩存的方式後,發現計算所用的時間已經接近0,我們把數再改大一點
t1 = time.time()
print(fibonacci(300))
t2 = time.time()
print(t2 - t1) # 0.001026153564453125
t1 = time.time()
print(fibonacci(301))
t2 = time.time()
print(t2 - t1) # 0.0
這也太厲害了,當把數增大到300時,花費的時間才是0.001秒,而且t2的計算結果為0也證明瞭的確裝飾器中緩存了數據,計算fibonacci(301)可直接從緩存中拿fibonacci(300)和fibonacci(299),我們用圖來更清晰的解釋
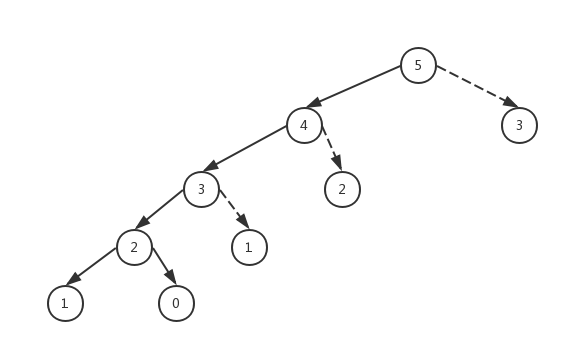
圖中用虛線所指的結點都不需要重新計算了,只計算了不重覆的數字,也就是意味著複雜度從O(2**n)降到了O(n)
這種緩存的思想,給我們的優化帶來了巨大的收益
三.lru_cache裝飾器
上面的裝飾器是我們自己寫的,但它不適用與其他函數,比如有多個參數的函數,但是python標準庫為我們提供了一個非常方便的裝飾器來進行緩存
它是functools模塊中的lru_cache(maxsize,typed)
通過其名就能讓我們瞭解它,它是通過lru演算法來進行緩存內容的淘汰,
maxsize參數設置緩存記憶體占用上限,其值應當設為2的冪,值為None時表示沒有上限
typed參數設置表示不同參數類型的調用是否分別緩存,這個參數的意思是如果設置為True,那麼fibonacci(5)和fibonacci(5.0)將分別緩存,不存為一個。
lru_cache的使用只需要將上面我們自定義的裝飾器替換為 lru_cache(None,False)即可。
參考《python高級編程(第2版)》


-
比較符合中國人的思維模式,舉的例子也多為作者自己經歷過的項目,容易產生共鳴。 六大原則和23個模式都有覆蓋,內容沒有GoF的書精辟,但也講解清楚。代碼的例子沒有大問題,對於理解有幫助。對GoF提出的23個模式的C++代碼都提供了相應的Java代碼實現,並且是基於JDK5的標準之上,使用了泛型和枚舉,... ...
-
1、什麼叫迭代 現在,我們已經獲得了一個新線索,有一個叫做“可迭代的”概念。 首先,我們從報錯來分析,好像之所以1234不可以for迴圈,是因為它不可迭代。那麼如果“可迭代”,就應該可以被for迴圈了。 這個我們知道呀,字元串、列表、元組、字典、集合都可以被for迴圈,說明他們都是可迭代的。 我們怎 ...
-
除了使用 new 操作符之外,還有更多的製造對象的方法。你將瞭解到實例化這個活動不應該總是公開進行,也會認識到初始化經常造成“耦合”問題。 ...
-
以上實例中,100,1000.0和"John"分別賦值給counter,miles,name變數。 執行以上程式會輸出如下結果: ...
-
一 開發環境說明: python3.5+wxpython包+math包 win10環境下開發,兼任win7 編譯工具:pycharm 二 運行界面展示: 三 開源共用: 四 打包xe文件下載地址: 百度網盤:https://pan.baidu.com/s/1xn9hjBsAvCFFq8XSpqS0L ...
-
Spring-data-jpa中非常簡單的查詢介面方式與CUBA相結合,簡化CUBA開發人員操作數據的方法,能有效提升代碼質量和交付速度 ...
-
背景 首先,我們達成以下共識: 一個服務方法,如果入參太多,且基本為非pojo,會給調用方造成不必要的干擾。儘管可以把文檔寫的很完善,但還是建議使用pojo對多個參數合理封裝。 如下示例: 執行方法都應該對入參進行校驗。對於一些 通用的簡單的不涉及業務邏輯 的校驗,比如字元串不為空,數字的範圍限制, ...
-
Java線程通信方法 0、(why)每個線程都有自己的棧空間,我們要線程之間進行交流,合作共贏。 1、synchronized和volatile關鍵字 a) 看下麵的synchronized關鍵字 b) 看下麵的volatile關鍵字 2、等待/通知機制:一個線程A調用對象的wait()方法,另一個 ...
