1.排序概述 2.排序分類 3.WritableComparable案例 這個文件,是大數據-Hadoop生態(12)-Hadoop序列化和源碼追蹤的輸出文件,可以看到,文件根據key,也就是手機號進行了字典排序 欄位含義分別為手機號,上行流量,下行流量,總流量 需求是根據總流量進行排序 Bean對 ...
1.排序概述


2.排序分類

3.WritableComparable案例
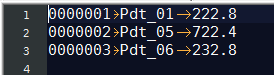
這個文件,是大數據-Hadoop生態(12)-Hadoop序列化和源碼追蹤的輸出文件,可以看到,文件根據key,也就是手機號進行了字典排序
13470253144 180 180 360
13509468723 7335 110349 117684
13560439638 918 4938 5856
13568436656 3597 25635 29232
13590439668 1116 954 2070
13630577991 6960 690 7650
13682846555 1938 2910 4848
13729199489 240 0 240
13736230513 2481 24681 27162
13768778790 120 120 240
13846544121 264 0 264
13956435636 132 1512 1644
13966251146 240 0 240
13975057813 11058 48243 59301
13992314666 3008 3720 6728
15043685818 3659 3538 7197
15910133277 3156 2936 6092
15959002129 1938 180 2118
18271575951 1527 2106 3633
18390173782 9531 2412 11943
84188413 4116 1432 5548
欄位含義分別為手機號,上行流量,下行流量,總流量
需求是根據總流量進行排序
Bean對象,需要實現序列化,反序列化和Comparable介面
package com.nty.writableComparable; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * author nty * date time 2018-12-12 16:33 */ /** * 實現WritableComparable介面 * 原先將bean序列化時,需要實現Writable介面,現在再實現Comparable介面 * * public interface WritableComparable<T> extends Writable, Comparable<T> * * 所以我們可以實現Writable和Comparable兩個介面,也可以實現WritableComparable介面 */ public class Flow implements WritableComparable<Flow> { private long upflow; private long downflow; private long total; public long getUpflow() { return upflow; } public void setUpflow(long upflow) { this.upflow = upflow; } public long getDownflow() { return downflow; } public void setDownflow(long downflow) { this.downflow = downflow; } public long getTotal() { return total; } public void setTotal(long total) { this.total = total; } //快速賦值 public void setFlow(long upflow, long downflow){ this.upflow = upflow; this.downflow = downflow; this.total = upflow + downflow; } @Override public String toString() { return upflow + "\t" + downflow + "\t" + total; } //重寫compareTo方法 @Override public int compareTo(Flow o) { return Long.compare(o.total, this.total); } //序列化方法 @Override public void write(DataOutput out) throws IOException { out.writeLong(upflow); out.writeLong(downflow); out.writeLong(total); } //反序列化方法 @Override public void readFields(DataInput in) throws IOException { upflow = in.readLong(); downflow = in.readLong(); total = in.readLong(); } }
Mapper類
package com.nty.writableComparable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * author nty * date time 2018-12-12 16:47 */ public class FlowMapper extends Mapper<LongWritable, Text, Flow, Text> { private Text phone = new Text(); private Flow flow = new Flow(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //13470253144 180 180 360 //分割行數據 String[] flieds = value.toString().split("\t"); //賦值 phone.set(flieds[0]); flow.setFlow(Long.parseLong(flieds[1]), Long.parseLong(flieds[2])); //寫出 context.write(flow, phone); } }
Reducer類
package com.nty.writableComparable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * author nty * date time 2018-12-12 16:47 */ //註意一下輸出類型 public class FlowReducer extends Reducer<Flow, Text, Text, Flow> { @Override protected void reduce(Flow key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text value : values) { //輸出 context.write(value,key); } } }
Driver類
package com.nty.writableComparable; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * author nty * date time 2018-12-12 16:47 */ public class FlowDriver { public static void main(String[] args) throws Exception { //1. 獲取Job實例 Configuration configuration = new Configuration(); Job instance = Job.getInstance(configuration); //2. 設置類路徑 instance.setJarByClass(FlowDriver.class); //3. 設置Mapper和Reducer instance.setMapperClass(FlowMapper.class); instance.setReducerClass(FlowReducer.class); //4. 設置輸出類型 instance.setMapOutputKeyClass(Flow.class); instance.setMapOutputValueClass(Text.class); instance.setOutputKeyClass(Text.class); instance.setOutputValueClass(Flow.class); //5. 設置輸入輸出路徑 FileInputFormat.setInputPaths(instance, new Path("d:\\Hadoop_test")); FileOutputFormat.setOutputPath(instance, new Path("d:\\Hadoop_test_out")); //6. 提交 boolean b = instance.waitForCompletion(true); System.exit(b ? 0 : 1); } }
結果
4.GroupingComparator案例
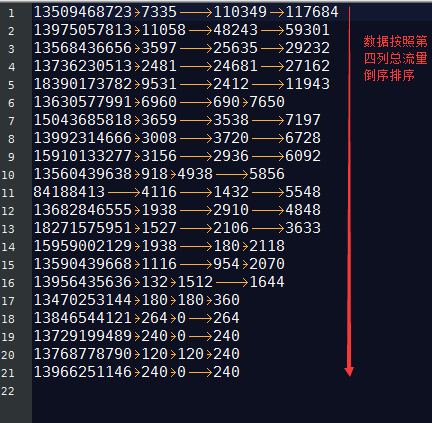
訂單id 商品id 商品金額
0000001 Pdt_01 222.8
0000002 Pdt_05 722.4
0000001 Pdt_02 33.8
0000003 Pdt_06 232.8
0000003 Pdt_02 33.8
0000002 Pdt_03 522.8
0000002 Pdt_04 122.4
求出每一個訂單中最貴的商品
需求分析:
1) 將訂單id和商品金額作為key,在Map階段先用訂單id升序排序,如果訂單id相同,再用商品金額降序排序
2) 在Reduce階段,用groupingComparator按照訂單分組,每一組的第一個即是最貴的商品
先定義bean對象,重寫序列化反序列話排序方法
package com.nty.groupingComparator; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * author nty * date time 2018-12-12 18:07 */ public class Order implements WritableComparable<Order> { private String orderId; private String productId; private double price; public String getOrderId() { return orderId; } public Order setOrderId(String orderId) { this.orderId = orderId; return this; } public String getProductId() { return productId; } public Order setProductId(String productId) { this.productId = productId; return this; } public double getPrice() { return price; } public Order setPrice(double price) { this.price = price; return this; } @Override public String toString() { return orderId + "\t" + productId + "\t" + price; } @Override public int compareTo(Order o) { //先按照訂單排序,正序 int compare = this.orderId.compareTo(o.getOrderId()); if(0 == compare){ //訂單相同,再比較價格,倒序 return Double.compare( o.getPrice(),this.price); } return compare; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(orderId); out.writeUTF(productId); out.writeDouble(price); } @Override public void readFields(DataInput in) throws IOException { this.orderId = in.readUTF(); this.productId = in.readUTF(); this.price = in.readDouble(); } }
Mapper類
package com.nty.groupingComparator; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * author nty * date time 2018-12-12 18:07 */ public class OrderMapper extends Mapper<LongWritable, Text, Order, NullWritable> { private Order order = new Order(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //0000001 Pdt_01 222.8 //分割行數據 String[] fields = value.toString().split("\t"); //為order賦值 order.setOrderId(fields[0]).setProductId(fields[1]).setPrice(Double.parseDouble(fields[2])); //寫出 context.write(order,NullWritable.get()); } }
GroupingComparator類
package com.nty.groupingComparator; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * author nty * date time 2018-12-12 18:08 */ public class OrderGroupingComparator extends WritableComparator { //用作比較的對象的具體類型 public OrderGroupingComparator() { super(Order.class,true); } //重寫的方法要選對哦,一共有三個,選擇參數為WritableComparable的方法 //預設的compare方法調用的是a,b對象的compare方法,但是現在我們排序和分組的規則不一致,所以要重寫分組規則 @Override public int compare(WritableComparable a, WritableComparable b) { Order oa = (Order) a; Order ob = (Order) b; //按照訂單id分組 return oa.getOrderId().compareTo(ob.getOrderId()); } }
Reducer類
package com.nty.groupingComparator; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * author nty * date time 2018-12-12 18:07 */ public class OrderReducer extends Reducer<Order, NullWritable,Order, NullWritable> { @Override protected void reduce(Order key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { //每一組的第一個即是最高價商品,不需要遍歷 context.write(key, NullWritable.get()); } }
Driver類
package com.nty.groupingComparator; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * author nty * date time 2018-12-12 18:07 */ public class OrderDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //1獲取實例 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); //2設置類路徑 job.setJarByClass(OrderDriver.class); //3.設置Mapper和Reducer job.setMapperClass(OrderMapper.class); job.setReducerClass(OrderReducer.class); //4.設置自定義分組類 job.setGroupingComparatorClass(OrderGroupingComparator.class); //5. 設置輸出類型 job.setMapOutputKeyClass(Order.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Order.class); job.setOutputValueClass(NullWritable.class); //6. 設置輸入輸出路徑 FileInputFormat.setInputPaths(job, new Path("d:\\Hadoop_test")); FileOutputFormat.setOutputPath(job, new Path("d:\\Hadoop_test_out")); //7. 提交 boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); } }
輸出結果