
1. CFS如何選擇最合適的進程 每個調度器類sched_class都必須提供一個pick_next_task函數用以在就緒隊列中選擇一個最優的進程來等待調度, 而我們的CFS調度器類中, 選擇下一個將要運行的進程由pick_next_task_fair函數來完成 之前我們在將主調度器的時候, 主調 ...
1. CFS如何選擇最合適的進程
每個調度器類sched_class都必須提供一個pick_next_task函數用以在就緒隊列中選擇一個最優的進程來等待調度, 而我們的CFS調度器類中, 選擇下一個將要運行的進程由pick_next_task_fair函數來完成
之前我們在將主調度器的時候, 主調度器schedule函數在進程調度搶占時, 會通過__schedule函數調用全局pick_next_task選擇一個最優的進程, 在pick_next_task中我們就按照優先順序依次調用不同調度器類提供的pick_next_task方法
今天就讓我們窺探一下完全公平調度器類CFS的pick_next_task方法pick_next_fair
pick_next_task_fair
選擇下一個將要運行的進程pick_next_task_fair執行. 其代碼執行流程如下
對於pick_next_task_fair函數的講解, 我們從simple標簽開始, 這個是常規狀態下pick_next的思路, 簡單的來說pick_next_task_fair的函數框架如下
again:
控制迴圈來讀取最優進程
#ifdef CONFIG_FAIR_GROUP_SCHED
完成組調度下的pick_next選擇
返回被選擇的調度時實體的指針
#endif
simple:
最基礎的pick_next函數
返回被選擇的調度時實體的指針
idle :
如果系統中沒有可運行的進行, 則需要調度idle進程可見我們會發現,
- simple標簽是CFS中最基礎的pick_next操作
- idle則使得在沒有進程被調度時, 調度idle進程
- again標簽用於迴圈的進行pick_next操作
- CONFIG_FAIR_GROUP_SCHED巨集指定了組調度情況下的pick_next操作, 如果不支持組調度, 則pick_next_task_fair將直接從simple開始執行
2 simple無組調度最簡單的pick_next_task_fair
在不支持組調度情況下(選項CONFIG_FAIR_GROUP_SCHED), CFS的pick_next_task_fair函數會直接執行simple標簽, 優選下一個函數, 這個流程清晰而且簡單, 但是已經足夠我們理解cfs的pick_next了
2.1 simple的基本流程
pick_next_task_fair函數的simple標簽定義在kernel/sched/fair.c, line 5526), 代碼如下所示
simple:
cfs_rq = &rq->cfs;
#endif
/* 如果nr_running計數器為0,
* 當前隊列上沒有可運行進程,
* 則需要調度idle進程 */
if (!cfs_rq->nr_running)
goto idle;
/* 將當前進程放入運行隊列的合適位置 */
put_prev_task(rq, prev);
do
{
/* 選出下一個可執行調度實體(進程) */
se = pick_next_entity(cfs_rq, NULL);
/* 把選中的進程從紅黑樹移除,更新紅黑樹
* set_next_entity會調用__dequeue_entity完成此工作 */
set_next_entity(cfs_rq, se);
/* group_cfs_rq return NULL when !CONFIG_FAIR_GROUP_SCHED
* 在非組調度情況下, group_cfs_rq返回了NULL */
cfs_rq = group_cfs_rq(se);
} while (cfs_rq); /* 在沒有配置組調度選項(CONFIG_FAIR_GROUP_SCHED)的情況下.group_cfs_rq()返回NULL.因此,上函數中的迴圈只會迴圈一次 */
/* 獲取到調度實體指代的進程信息 */
p = task_of(se);
if (hrtick_enabled(rq))
hrtick_start_fair(rq, p);
return p;其基本流程如下
| 流程 | 描述 |
|---|---|
| !cfs_rq->nr_running -=> goto idle; | 如果nr_running計數器為0, 當前隊列上沒有可運行進程, 則需要調度idle進程 |
| put_prev_task(rq, prev); | 將當前進程放入運行隊列的合適位置, 每次當進程被調度後都會使用set_next_entity從紅黑樹中移除, 因此被搶占時需要重新加如紅黑樹中等待被調度 |
| se = pick_next_entity(cfs_rq, NULL); | 選出下一個可執行調度實體 |
| set_next_entity(cfs_rq, se); | set_next_entity會調用__dequeue_entity把選中的進程從紅黑樹移除,並更新紅黑樹 |
2.2 put_prev_task
2.2.1 全局put_prev_task函數
put_prev_task用來將前一個進程prev放回到就緒隊列中, 這是一個全局的函數, 而每個調度器類也必須實現一個自己的put_prev_task函數(比如CFS的put_prev_task_fair),
由於CFS調度的時候, prev進程不一定是一個CFS調度的進程, 因此必須調用全局的put_prev_task來調用prev進程所屬調度器類sched_class的對應put_prev_task方法, 完成將進程放回到就緒隊列中
全局的put_prev_task函數定義在kernel/sched/sched.h, line 1245, 代碼如下所示
static inline void put_prev_task(struct rq *rq, struct task_struct *prev)
{
prev->sched_class->put_prev_task(rq, prev);
}2.2.2 CFS的put_prev_task_fair函數
然後我們來分析一下CFS的put_prev_task_fair函數, 其定義在kernel/sched/fair.c, line 5572
在選中了下一個將被調度執行的進程之後,回到pick_next_task_fair中,執行set_next_entity
/*
* Account for a descheduled task:
*/
static void put_prev_task_fair(struct rq *rq, struct task_struct *prev)
{
struct sched_entity *se = &prev->se;
struct cfs_rq *cfs_rq;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
put_prev_entity(cfs_rq, se);
}
}前面我們說到過函數在組策略情況下, 調度實體之間存在父子的層次, for_each_sched_entity會從當前調度實體開始, 然後迴圈向其父調度實體進行更新, 非組調度情況下則只執行一次
而put_prev_task_fair函數最終會調用put_prev_entity函數將prev的調度時提se放回到就緒隊列中等待下次調度
2.2.3 put_prev_entity函數
put_prev_entity函數定義在kernel/sched/fair.c, line 3443, 他在更新了虛擬運行時間等信息後, 最終通過__enqueue_entity函數將prev進程(即current進程)放回就緒隊列rq上
2.3 pick_next_entity
2.3.1 pick_next_entity函數完全註釋
/*
* Pick the next process, keeping these things in mind, in this order:
* 1) keep things fair between processes/task groups
* 2) pick the "next" process, since someone really wants that to run
* 3) pick the "last" process, for cache locality
* 4) do not run the "skip" process, if something else is available
*
* 1. 首先要確保任務組之間的公平, 這也是設置組的原因之一
* 2. 其次, 挑選下一個合適的(優先順序比較高的)進程
* 因為它確實需要馬上運行
* 3. 如果沒有找到條件2中的進程
* 那麼為了保持良好的局部性
* 則選中上一次執行的進程
* 4. 只要有任務存在, 就不要讓CPU空轉,
* 只有在沒有進程的情況下才會讓CPU運行idle進程
*/
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
/* 摘取紅黑樹最左邊的進程 */
struct sched_entity *left = __pick_first_entity(cfs_rq);
struct sched_entity *se;
/*
* If curr is set we have to see if its left of the leftmost entity
* still in the tree, provided there was anything in the tree at all.
*
* 如果
* left == NULL 或者
* curr != NULL curr進程比left進程更優(即curr的虛擬運行時間更小)
* 說明curr進程是自動放棄運行權利, 且其比最左進程更優
* 因此將left指向了curr, 即curr是最優的進程
*/
if (!left || (curr && entity_before(curr, left)))
{
left = curr;
}
/* se = left存儲了cfs_rq隊列中最優的那個進程
* 如果進程curr是一個自願放棄CPU的進程(其比最左進程更優), 則取se = curr
* 否則進程se就取紅黑樹中最左的進程left, 它必然是當前就緒隊列上最優的
*/
se = left; /* ideally we run the leftmost entity */
/*
* Avoid running the skip buddy, if running something else can
* be done without getting too unfair.
*
* cfs_rq->skip存儲了需要調過不參與調度的進程調度實體
* 如果我們挑選出來的最優調度實體se正好是skip
* 那麼我們需要選擇次優的調度實體se來進行調度
* 由於之前的se = left = (curr before left) curr left
* 則如果 se == curr == skip, 則選擇left = __pick_first_entity進行即可
* 否則則se == left == skip, 則選擇次優的那個調度實體second
*/
if (cfs_rq->skip == se)
{
struct sched_entity *second;
if (se == curr) /* se == curr == skip選擇最左的那個調度實體left */
{
second = __pick_first_entity(cfs_rq);
}
else /* 否則se == left == skip, 選擇次優的調度實體second */
{
/* 摘取紅黑樹上第二左的進程節點 */
second = __pick_next_entity(se);
/* 同時與left進程一樣,
* 如果
* second == NULL 沒有次優的進程 或者
* curr != NULL curr進程比left進程更優(即curr的虛擬運行時間更小)
* 說明curr進程比最second進程更優
* 因此將second指向了curr, 即curr是最優的進程*/
if (!second || (curr && entity_before(curr, second)))
second = curr;
}
/* 判斷left和second的vruntime的差距是否小於sysctl_sched_wakeup_granularity
* 即如果second能搶占left */
if (second && wakeup_preempt_entity(second, left) < 1)
se = second;
}
/*
* Prefer last buddy, try to return the CPU to a preempted task.
*
*
*/
if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1)
se = cfs_rq->last;
/*
* Someone really wants this to run. If it's not unfair, run it.
*/
if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1)
se = cfs_rq->next;
/* 用過一次任何一個next或者last
* 都需要清除掉這個指針
* 以免影響到下次pick next sched_entity */
clear_buddies(cfs_rq, se);
return se;
}2.3.2 從left, second和curr進程中選擇最優的進程
pick_next_entity則從CFS的紅黑樹中摘取一個最優的進程, 這個進程往往在紅黑樹的最左端, 即vruntime最小, 但是也有例外, 但是不外乎這幾個進程
| 調度實體 | 描述 |
|---|---|
| left = __pick_first_entity(cfs_rq) | 紅黑樹的最左節點, 這個節點擁有當前隊列中vruntime最小的特性, 即應該優先被調度 |
| second = __pick_first_entity(left) | 紅黑樹的次左節點, 為什麼這個節點也可能呢, 因為內核支持skip跳過某個進程的搶占權力的, 如果left被標記為skip(由cfs_rq->skip域指定), 那麼可能就需要找到次優的那個進程 |
| curr結點 | curr節點的vruntime可能比left和second更小, 但是由於它正在運行, 因此它不在紅黑樹中(進程搶占物理機的時候對應節點同時會從紅黑樹中刪除), 但是如果其vruntime足夠小, 意味著cfs調度器應該儘可能的補償curr進程, 讓它再次被調度 |
其中__pick_first_entity會返回cfs_rq紅黑樹中的最左節點rb_leftmost所屬的調度實體信息, 該函數定義在kernel/sched/fair.c, line 543
而__pick_next_entity(se)函數則返回se在紅黑樹中中序遍歷的下一個節點信息, 該函數定義在kernel/sched/fair.c, line 544, 獲取下一個節點的工作可以通過內核紅黑樹的標準操作rb_next完成
2.3.3 cfs_rq的last和next指針域
在pick_next_entity的最後, 要把紅黑樹最左下角的進程和另外兩個進程(即next和last)做比較, next是搶占失敗的進程, 而last則是搶占成功後被搶占的進程, 這三個進程到底哪一個是最優的next進程呢?
Linux CFS實現的判決條件是:
- 儘可能滿足需要剛被喚醒的進程搶占其它進程的需求
- 儘可能減少以上這種搶占帶來的緩存刷新的影響
cfs_rq的last和next指針,last表示最後一個執行wakeup的sched_entity,next表示最後一個被wakeup的sched_entity。他們在進程wakeup的時候會賦值,在pick新sched_entity的時候,會優先選擇這些last或者next指針的sched_entity,有利於提高緩存的命中率
因此我們優選出來的進程必須同last和next指針域進行對比, 其實就是檢查就緒隊列中的最優進程, 即紅黑樹中最左節點last是否可以搶占last和next指針域, 檢查是否可以搶占是通過wakeup_preempt_entity函數來完成的.
2.3.4 wakeup_preempt_entity檢查是否可以被搶占
// http://lxr.free-electrons.com/source/kernel/sched/fair.c?v=4.6#L5317
/*
* Should 'se' preempt 'curr'.
*
* |s1
* |s2
* |s3
* g
* |<--->|c
*
* w(c, s1) = -1
* w(c, s2) = 0
* w(c, s3) = 1
*
*/
static int
wakeup_preempt_entity(struct sched_entity *curr, struct sched_entity *se)
{
/* vdiff為curr和se vruntime的差值*/
s64 gran, vdiff = curr->vruntime - se->vruntime;
/* cfs_rq的vruntime是單調遞增的,也就是一個基準
* 各個進程的vruntime追趕競爭cfsq的vruntime
* 如果curr的vruntime比較小, 說明curr更加需要補償,
* 即se無法搶占curr */
if (vdiff <= 0)
return -1;
/* 計算curr的最小搶占期限粒度 */
gran = wakeup_gran(curr, se);
/* 當差值大於這個最小粒度的時候才搶占,這可以避免頻繁搶占 */
if (vdiff > gran)
return 1;
return 0;
}
// http://lxr.free-electrons.com/source/kernel/sched/fair.c?v=4.6#L5282
static unsigned long
wakeup_gran(struct sched_entity *curr, struct sched_entity *se)
{
/* NICE_0_LOAD的基準最小運行期限 */
unsigned long gran = sysctl_sched_wakeup_granularity;
/*
* Since its curr running now, convert the gran from real-time
* to virtual-time in his units.
*
* By using 'se' instead of 'curr' we penalize light tasks, so
* they get preempted easier. That is, if 'se' < 'curr' then
* the resulting gran will be larger, therefore penalizing the
* lighter, if otoh 'se' > 'curr' then the resulting gran will
* be smaller, again penalizing the lighter task.
*
* This is especially important for buddies when the leftmost
* task is higher priority than the buddy.
*
* 計算進程運行的期限,即搶占的粒度
*/
return calc_delta_fair(gran, se);
}到底能不能選擇last和next兩個進程, 則是wakeup_preempt_entity函數來決定的, 看下麵的圖解即可:
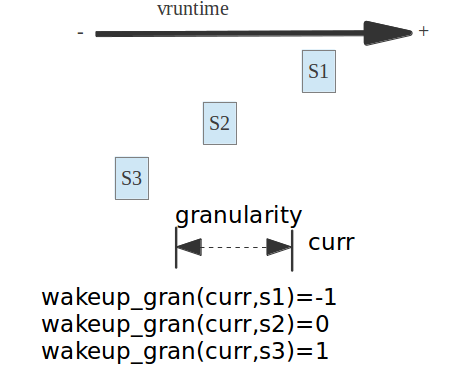
如果S3是left,curr是next或者last,left的vruntime值小於curr和next, 函數wakeup_preempt_entity肯定返回1,那麼就說明next和last指針的vruntime和left差距過大,這個時候沒有必要選擇這個last或者next指針,而是應該優先補償left
如果next或者last是S2,S1,那麼vruntime和left差距並不大,並沒有超過sysctl_sched_wakeup_granularity ,那麼這個next或者last就可以被優先選擇,而代替了left
而清除last和next這兩個指針的時機有這麼幾個:
- sched_tick的時候, 如果一個進程的運行時間超過理論時間(這個時間是根據load和cfs_rq的load, 平均分割sysctl_sched_latency的時間), 那麼如果next或者last指針指向這個正在運行的進程, 需要清除這個指針, 使得pick sched_entity不會因為next或者last指針再次選擇到這個sched_entity
- 當一個sched_entity調度實體dequeue出運行隊列,那麼如果有next或者last指針指向這個sched_entity, 那麼需要刪除這個next或者last指針。
- 剛纔說的那種case,如果next,last指針在pick的時候被使用了一次,那麼這次用完了指針,需要清除相應的指針,避免使用過的next,last指針影響到下次pick
- 當進程yield操作的時候,進程主動放棄了調度機會,那麼如果next,last指針指向了這個sched_entity,那麼需要清除相應指針。
2.4 set_next_entity
現在我們已經通過pick_next_task_fair選擇了進程, 但是還需要完成一些工作, 才能將其標記為運行進程. 這是通過set_next_entity來處理的. 該函數定義在kernel/sched/fair.c, line 3348
當前執行進程(我們選擇出來的進程馬上要搶占處理器開始執行)不應該再保存在就緒隊列上, 因此set_next_entity()函數會調用__dequeue_entity(cfs_rq, se)把選中的下一個進程移出紅黑樹. 如果當前進程是最左節點, __dequeue_entity會將leftmost指針設置到次左進程
/* 'current' is not kept within the tree. */
if (se->on_rq) /* 如果se尚在rq隊列上 */
{
/* ...... */
/* 將se從cfs_rq的紅黑樹中刪除 */
__dequeue_entity(cfs_rq, se);
/* ...... */
}儘管該進程不再包含在紅黑樹中, 但是進程和就緒隊列之間的關聯並沒有丟失, 因為curr標記了當前進程cfs_rq->curr = se;
cfs_rq->curr = se;然後接下來是一些統計信息的處理, 如果內核開啟了調度統計CONFIG_SCHEDSTATS標識, 則會完成調度統計的計算和更新
#ifdef CONFIG_SCHEDSTATS
/*
* Track our maximum slice length, if the CPU's load is at
* least twice that of our own weight (i.e. dont track it
* when there are only lesser-weight tasks around):
*/
if (schedstat_enabled() && rq_of(cfs_rq)->load.weight >= 2*se->load.weight) {
se->statistics.slice_max = max(se->statistics.slice_max,
se->sum_exec_runtime - se->prev_sum_exec_runtime);
}
#endif在set_next_entity的最後, 將選擇出的調度實體se的sum_exec_runtime保存在了prev_sum_exec_runtime中, 因為該調度實體指向的進程, 馬上將搶占處理器成為當前活動進程, 在CPU上花費的實際時間將記入sum_exec_runtime, 因此內核會在prev_sum_exec_runtime保存此前的設置. 要註意進程中的sum_exec_runtime沒有重置. 因此差值sum_exec_runtime - prev_sum_runtime確實標識了在CPU上執行花費的實際時間.
最後我們附上set_next_entity函數的完整註釋信息
static void
set_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
/* 'current' is not kept within the tree. */
if (se->on_rq) /* 如果se尚在rq隊列上 */
{
/*
* Any task has to be enqueued before it get to execute on
* a CPU. So account for the time it spent waiting on the
* runqueue.
*/
if (schedstat_enabled())
update_stats_wait_end(cfs_rq, se);
/* 將se從cfs_rq的紅黑樹中刪除 */
__dequeue_entity(cfs_rq, se);
update_load_avg(se, 1);
}
/* 新sched_entity中的exec_start欄位為當前clock_task */
update_stats_curr_start(cfs_rq, se);
/* 將se設置為curr進程 */
cfs_rq->curr = se;
#ifdef CONFIG_SCHEDSTATS
/*
* Track our maximum slice length, if the CPU's load is at
* least twice that of our own weight (i.e. dont track it
* when there are only lesser-weight tasks around):
*/
if (schedstat_enabled() && rq_of(cfs_rq)->load.weight >= 2*se->load.weight) {
se->statistics.slice_max = max(se->statistics.slice_max,
se->sum_exec_runtime - se->prev_sum_exec_runtime);
}
#endif
/* 更新task上一次投入運行的從時間 */
se->prev_sum_exec_runtime = se->sum_exec_runtime;
}3 idle進程的調度
/* 如果nr_running計數器為0,
* 當前隊列上沒有可運行進程,
* 則需要調度idle進程 */
if (!cfs_rq->nr_running)
goto idle;如果系統中當前運行隊列上沒有可調度的進程, 那麼會調到idle標簽去調度idle進程.
idle標簽如下所示
idle:
/*
* This is OK, because current is on_cpu, which avoids it being picked
* for load-balance and preemption/IRQs are still disabled avoiding
* further scheduler activity on it and we're being very careful to
* re-start the picking loop.
*/
lockdep_unpin_lock(&rq->lock);
new_tasks = idle_balance(rq);
lockdep_pin_lock(&rq->lock);
/*
* Because idle_balance() releases (and re-acquires) rq->lock, it is
* possible for any higher priority task to appear. In that case we
* must re-start the pick_next_entity() loop.
*/
if (new_tasks < 0)
return RETRY_TASK;
if (new_tasks > 0)
goto again;
return NULL;其關鍵就是調用idle_balance進行任務的遷移
每個cpu都有自己的運行隊列, 如果當前cpu上運行的任務都已經dequeue出運行隊列,而且idle_balance也沒有移動到當前運行隊列的任務,那麼schedule函數中,按照stop > idle > rt > cfs > idle這三種調度方式順序,尋找各自的運行任務,那麼如果rt和cfs都未找到運行任務,那麼最後會調用idle schedule的idle進程,作為schedule函數調度的下一個任務
如果某個cpu空閑, 而其他CPU不空閑, 即當前CPU運行隊列為NULL, 而其他CPU運行隊列有進程等待調度的時候, 則內核會對CPU嘗試負載平衡, CPU負載均衡有兩種方式: pull和push, 即空閑CPU從其他忙的CPU隊列中pull拉一個進程複製到當前空閑CPU上, 或者忙的CPU隊列將一個進程push推送到空閑的CPU隊列中.
idle_balance其實就是pull的工作.
4 組調度策略的支持
組調度的情形下, 調度實體之間存在明顯的層次關係, 因此在跟新子調度實體的時候, 需要更新父調度實體的信息, 同時我們為了保證同一組內的進程不能長時間占用處理機, 必須補償其他組內的進程, 保證公平性
#ifdef CONFIG_FAIR_GROUP_SCHED
/* 如果nr_running計數器為0, 即當前隊列上沒有可運行進程,
* 則需要調度idle進程 */
if (!cfs_rq->nr_running)
goto idle;
/* 如果當前運行進程prev不是被fair調度的普通非實時進程 */
if (prev->sched_class != &fair_sched_class)
goto simple;
/*
* Because of the set_next_buddy() in dequeue_task_fair() it is rather
* likely that a next task is from the same cgroup as the current.
*
* Therefore attempt to avoid putting and setting the entire cgroup
* hierarchy, only change the part that actually changes.
*/
do {
struct sched_entity *curr = cfs_rq->curr;
/*
* Since we got here without doing put_prev_entity() we also
* have to consider cfs_rq->curr. If it is still a runnable
* entity, update_curr() will update its vruntime, otherwise
* forget we've ever seen it.
*/
if (curr)
{
/* 如果當前進程curr在隊列上,
* 則需要更新起統計量和虛擬運行時間
* 否則設置curr為空 */
if (curr->on_rq)
update_curr(cfs_rq);
else
curr = NULL;
/*
* This call to check_cfs_rq_runtime() will do the
* throttle and dequeue its entity in the parent(s).
* Therefore the 'simple' nr_running test will indeed
* be correct.
*/
if (unlikely(check_cfs_rq_runtime(cfs_rq)))
goto simple;
}
/* 選擇一個最優的調度實體 */
se = pick_next_entity(cfs_rq, curr);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq); /* 如果被調度的進程仍屬於當前組,那麼選取下一個可能被調度的任務,以保證組間調度的公平性 */
/* 獲取調度實體se的進程實體信息 */
p = task_of(se);
/*
* Since we haven't yet done put_prev_entity and if the selected task
* is a different task than we started out with, try and touch the
* least amount of cfs_rqs.
*/
if (prev != p)
{
struct sched_entity *pse = &prev->se;
while (!(cfs_rq = is_same_group(se, pse)))
{
int se_depth = se->depth;
int pse_depth = pse->depth;
if (se_depth <= pse_depth)
{
put_prev_entity(cfs_rq_of(pse), pse);
pse = parent_entity(pse);
}
if (se_depth >= pse_depth)
{
set_next_entity(cfs_rq_of(se), se);
se = parent_entity(se);
}
}
put_prev_entity(cfs_rq, pse);
set_next_entity(cfs_rq, se);
}
if (hrtick_enabled(rq))
hrtick_start_fair(rq, p);
return p;5 與主調度器schedule進行通信
我們在之前講解主調度器的時候就提到過, 主調度器函數schedule會調用__schedule來完成搶占, 而主調度器的主要功能就是選擇一個新的進程來搶占到當前的處理器. 因此其中必然不能缺少pick_next_task工作
參見主調度器schedule)中調用全局的pick_next_task選擇搶占的進程一節的內容
__schedule調用全局的pick_next_task函數選擇一個最優的進程, 內核代碼參見kernel/sched/core.c, line 3142
static void __sched notrace __schedule(bool preempt)
{
/* ...... */
next = pick_next_task(rq);
/* ...... */
}全局的pick_next_task函數會從按照優先順序遍歷所有調度器類的pick_next_task函數, 去查找最優的那個進程, 當然因為大多數情況下, 系統中全是CFS調度的非實時進程, 因而linux內核也有一些優化的策略
其執行流程如下
- 如果當前cpu上所有的進程都是cfs調度的普通非實時進程, 則直接用cfs調度, 如果無程式可調度則調度idle進程
- 否則從優先順序最高的調度器類sched_class_highest(目前是stop_sched_class)開始依次遍歷所有調度器類的pick_next_task函數, 選擇最優的那個進程執行
其定義在kernel/sched/core.c, line 3068


