
一、Greenplum背景 時間回到2002年,互聯網行業經過近10年的發展,數據量正處於快速增長期: 1、傳統的主機計算模式在海量數據面前,除了造價昂貴外,在CPU計算和IO吞吐上不能滿足海量數據的計算需求; 2、傳統資料庫大多基於SMP架,縱向擴容(scale-up)模式遇到了瓶頸。 3、分散式 ...
一、Greenplum背景
時間回到2002年,互聯網行業經過近10年的發展,數據量正處於快速增長期:
1、傳統的主機計算模式在海量數據面前,除了造價昂貴外,在CPU計算和IO吞吐上不能滿足海量數據的計算需求;
2、傳統資料庫大多基於SMP架,縱向擴容(scale-up)模式遇到了瓶頸。
3、分散式存儲和分散式計算理論剛剛被提出來,Google的兩篇著名論文關於GFS分散式文件系統和關於MapReduce 並行計算框架的理論引起業界的關註,分散式計算模式在互聯網行業特別是收索引擎和分詞檢索等方面獲得了巨大成功。
Greenplum是為解決以上問題產生的可以支持scale-out橫向擴展的基於資料庫的MPP架構的分散式數據存儲和並行計算的工具。
二、Greenplum架構
2.1 Greenplum MPP架構
在介紹Greenplum架構前,先來瞭解下背景里出現的MPP架構。所謂的MPP架構即Massively Parallel Processing大規模並行進程。其基本特征是由多個SMP伺服器通過節點互聯網路連接而成,每個節點只訪問自己的本地資源(記憶體、存儲等),是一種完全無共用(Share Nothing)結構,因而橫向擴展能力好,性能隨著硬體增加呈線性提升,理論上其擴展無限制。
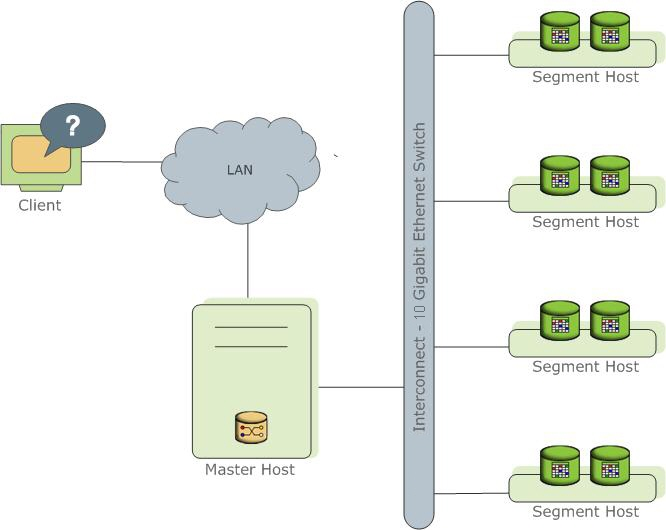
可以看到,每個segment的硬體內容是獨立的,在上層通過網路進行通信,Greenplum架構是典型的MPP架構。Master節點保存著global system catalog,並提供外部訪問入口。業務數據都根據分佈規則存放在Segment節點上。
2.2 Master高可用之 Master&Standby
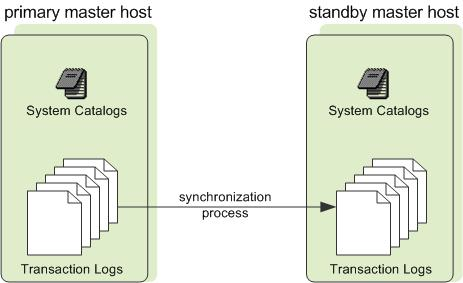
由於Greenplum所有的並行任務都是在Segment數據節點上完成後,Master只負責生成和優化查詢計劃、派發任務、協調數據節點進行並行計算。Master節點並不會因為因為數據壓力過大導致資源緊張成為瓶頸。
2.3 Segment高可用之鏡像策略
在上一期安裝初始化的時候有講到ssh協議不通會導致初始化互相copy primary文件到別的鏡像主機當做mirror文件失效報錯,現在詳細介紹下鏡像策略。
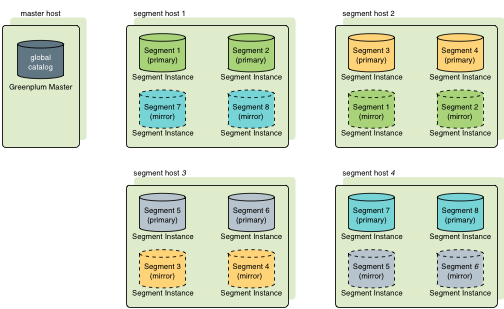
Greenplum有兩種鏡像策略,分別為group(預設策略)和spread模式。其中group模式每個Host的鏡像文件都放在下一個Host上,所有計算節點形成一個環。如下圖
而spread模式是將每個Host的鏡像依次分散到後續Host上,如下圖
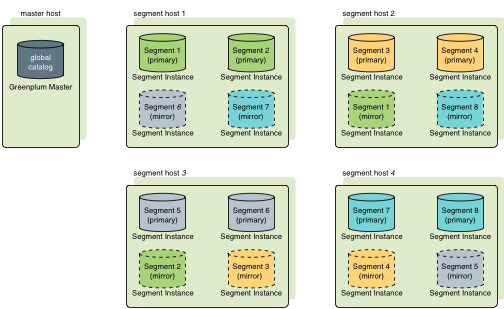
兩者的差異在於可宕機數量以及宕機後仍處在正常狀態伺服器的壓力。
以上兩圖為例,group模式下segment host1掛掉後,集群會使用segment host2鏡像實例當做segment host1主實例的備選,使集群繼續使用。即使在segment host1掛掉後,segment host3掛掉,segment host2和segment host4的主實例和鏡像實例扔能支撐整個集群正常使用;
而在spread模式下segment host1掛掉後,其他三台任意出現故障導致服務不可用時,整個集群會有部分節點無法訪問導致異常(例如segment host2和segment host3掛掉綠色不可用,segment host4掛掉藍色不可用),spread對比group的優點在於,當只出現一臺機器如segment host1掛掉時,spread能將segment host1的壓力平分到segment host2和segment host3上,而group模式會將壓力全都轉移到segment host2上。
鏡像模式可自動實現故障轉移功能;如何選擇鏡像模式,需要根據實際情況來選擇。
gpinitsystem_config初始化文件
################################################ #### OPTIONAL MIRROR PARAMETERS ################################################ #### Base number by which mirror segment port numbers #### are calculated. MIRROR_PORT_BASE=53000 #### Base number by which primary file replication port #### numbers are calculated. REPLICATION_PORT_BASE=43000 #### Base number by which mirror file replication port #### numbers are calculated. MIRROR_REPLICATION_PORT_BASE=54000 #### File system location(s) where mirror segment data directories #### will be created. The number of mirror locations must equal the #### number of primary locations as specified in the #### DATA_DIRECTORY parameter. #declare -a MIRROR_DATA_DIRECTORY=(/data1/mirror /data1/mirror /data1/mirror /data2/mirror /data2/mirror /data2/mirror) declare -a MIRROR_DATA_DIRECTORY=(/home/gpadmin/gpdata/gpdatam1 /home/gpadmin/gpdata/gpdatam2)
參考文檔:
1、Greenplum架構 https://gpdb.docs.pivotal.io/5100/admin_guide/intro/arch_overview.html
2、鏡像模式 https://gpdb.docs.pivotal.io/570/admin_guide/highavail/topics/g-overview-of-segment-mirroring.html
3、Master-Slave https://gpdb.docs.pivotal.io/5100/admin_guide/highavail/topics/g-overview-of-master-mirroring.html


