
redis持久化 1.redis持久化介紹 我們知道redis性能之所以強悍,是因為redis在運行時將數據都存放在了訪問效率遠高於硬碟的記憶體之中。可是這帶來了新的問題:在redis或者外部系統重啟時,記憶體中的數據將會丟失,由於目前的記憶體介質RAM是易失的,非正常的斷電也會導致數據的丟失。 在一些場 ...
redis持久化
1.redis持久化介紹
我們知道redis性能之所以強悍,是因為redis在運行時將數據都存放在了訪問效率遠高於硬碟的記憶體之中。可是這帶來了新的問題:在redis或者外部系統重啟時,記憶體中的數據將會丟失,由於目前的記憶體介質RAM是易失的,非正常的斷電也會導致數據的丟失。
在一些場合下我們會希望redis能夠將記憶體中的數據永久性的保存起來。
例如:
1.redis作為資料庫,將數據永久的保存起來。
2.redis作為緩存伺服器,不希望出現大量緩存數據同時丟失造成緩存被穿透的"雪崩"現象。
而將redis運行在記憶體中的數據同步到諸如硬碟之類的永久性存儲介質上的過程,我們稱之為redis的持久化。redis目前支持兩種持久化的方式,RDB和AOF。
2.redis持久化之RDB
RDB(RedisDataBase)是基於快照(snapshoptting)實現的。redis在運行時會在滿足一定條件的情況下將運行中的數據同步轉儲到一個二進位的文件並保存在磁碟中作為副本。
redis會在以下幾種情況下進行RDB的持久化,生成快照文件:
2.1 滿足配置規則進行自動快照時
redis允許用戶在(固定時間間隔M)和(被修改的key的個數N)這兩個關鍵維度上面進行自定義的配置。
在redis的配置文件中預設存在了三個自定義條件:

第一行代表著在每900秒的時間間隔內,存在1個或以上的key被修改過,便會進行非同步快照存儲;
第二行代表著在每300秒內的時間間隔內,存在10個或以上的key被修改過,便會進行非同步快照存儲,以此類推。
自定義觸發條件可以同時存在N個。但是進行快照的持久化操作在增加了數據安全性的同時也會消耗額外的系統資源,因此不能過於頻繁。用戶可以根據自己的實際需求,在數據安全性和系統性能之間進行取捨。當配置設置為空字元串時,代表禁用該特性,永不進行自動快照。
2.2 執行手動備份命令時
有時在數據遷移,系統重啟等情況下,我們希望能夠手動的令redis立即進行快照備份。
redis提供了兩個命令來滿足這個需求:
1.SAVE命令:
在執行SAVE命令時,redis會執行同步阻塞式的快照操作,此時的redis會阻塞所有的其它請求。如果所要同步的數據量很大,會導致redis長時間的未響應,因此應該避免在生產環境中使用該命令。
2.BGSAVE命令:
在執行BGSAVE(BackGround SAVE)命令時,顧名思義,redis將會在後臺進行快照存儲。這個操作是非同步的,並不會阻塞其它的操作。由於redis是單線程架構,因此非同步的快照存儲實際上是redis從主進程中fork了一個子進程,這時主進程繼續對外提供服務,而子進程則在後臺默默的執行快照存儲操作,在生成新的備份文件後,會將之前過時的備份文件替換掉。
值得一提的是,由於redis在非同步快照操作時使用了操作系統支持的"寫時複製"策略,即fork時操作系統並不會立刻為子進程提供一片主進程同等大小的記憶體區域,而是fork完畢的瞬間,子進程和主進程共用同一片記憶體區域。當主進程的記憶體被寫入新數據時,逐步分配新的記憶體區域給主進程用於存儲新數據,這大大的提高了記憶體的利用效率。但是如果在子進程備份期間主進程寫入數據過多,由於系統必須同時維護主進程的實時數據和備份子進程中需要備份的舊數據,可能會比較多的記憶體,因此最好能預見到這種糟糕的情況,事先允許redis申請足夠多的記憶體空間,以避免記憶體溢出。
2.3 執行FLUSHALL命令時
執行FLUSHALL命令時,redis會將所有的數據都清除,此時如果開啟了自動快照功能,則無論清除操作執行之後是否滿足自定義條件,redis都預設會進行一次RDB快照,生成一個空的備份文件。如果未開啟自動快照功能,則FLUSHALL不會觸發快照操作。
2.4 主從模式複製時
當redis在進行主從複製時,會預設進行一次快照操作,這麼做的原因會在未來主從複製的文章中介紹。
RDB總結:
上面簡單的介紹了redis進行RDB持久化的幾種方式,對於RDB還有很多細節例如rdbcompression(生成的備份文件是否需要壓縮--->"壓縮文件占據更小的磁碟空間但是在壓縮和解壓縮時需要耗費更多的CPU資源")、stop-writes-on-bgsave-error(BGSAVE時如果出錯,是否允許繼續寫入新數據)等等,在這裡就不再展開。
仔細觀察和思考可以發現,對於設置2.1自定義觸發條件的方式,一旦出現系統故障,最近一次RDB快照操作到故障發生時這段時間內的全部更新記錄都會丟失,由於生成快照過於頻繁會使得redis的可用性大幅度下降,因此無法實時的生成快照。至於2.2、2.3、2.4這些幾乎不常用的操作更是無法滿足要求。雖然實際可能只會丟失少量的數據(一個時間間隔內的所有更新操作),可是依然存在一些對數據正確性要求很高的場合,用RDB進行持久化的方式是無法滿足的。這便引出了我們接下來要介紹的redis的AOF持久化方式。
3.redis持久化之AOF
當需要使用redis存儲一些非臨時性的,重要的數據時,推薦使用redis的AOF持久化方式。AOF(AppendOnlyFile)和RDB不同,RDB關註實時數據,通過備份實時的數據快照來達到數據的持久化,而AOF則是關註所執行的更新命令(造成數據變化的命令,查詢排序之類的不算),通過實時的保存redis執行的每一條更新命令,生成細粒度的更新命令日誌來達到數據的持久化。由於每一次更新命令都會被記錄下來並且保存在硬碟上,這會導致redis的性能降低,使用高性能的硬碟可以儘可能的降低負面影響,使之達到能夠被接受的程度。
重寫aof文件
由於對同一個記錄的數據更新操作會覆蓋之前的數據,這導致了在原始的AOF文件中可能會出現大量的冗餘記錄,redis提供了重寫aof文件的功能,通過剔除掉冗餘的記錄,可以降低文件占用的磁碟空間。
redis提供了兩種重寫(rewrite)aof文件的方式:
手動執行 BGREWRITEAOF命令:
執行BGREWRITEAOF時,和BGSAVE一樣,redis不希望重寫aof文件時阻塞服務,會在後臺fork新的進程非同步的進行AOF文件的重寫。
自動觸發:
除了手動觸發,redis還提供了自動重寫aof文件的功能,配置兩個關鍵參數auto-aof-rewrite-percentage和auto-aof-rewrite-min-size,redis會執行周期性的函數一直監聽aof文件的變化,當達到配置好的觸發條件時,便會自動的進行aof文件的重寫。
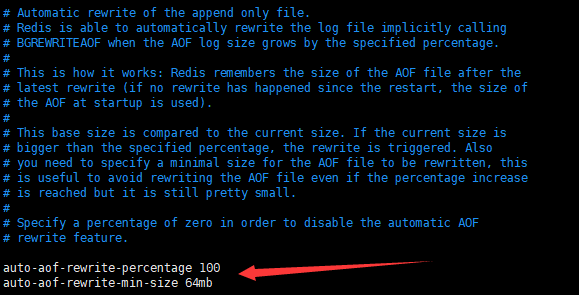
redis的配置文件中預設的參數如圖所示,第一行代表當AOF文件超過了上一次重寫文件的100%時,第二行代表當前aof文件大小是否超過了64M,當redis伺服器監聽發現滿足了上述兩個條件,而且此時沒有正在進行中的其它持久化操作(rdb和手動rewrite),便會執行自動的rewrite重寫操作。
同步硬碟數據
現代的操作系統為了彌補磁碟和記憶體之間存取速度的差距,都採用了磁碟緩存技術,緩存數據命中時操作系統優先操作磁碟緩存,操作系統會定期的將磁碟緩存中的數據刷新寫入磁碟。這意味著應用程式(例如redis)調用文件寫入磁碟的介面後,預設情況下並不會實時的寫入磁碟,而必須等待操作系統周期性的同步操作(一般是30s),而在次期間一旦出現系統故障,最新的aof文件變更記錄還是會丟失掉。因此redis提供了一個配置參數appendfsync來幫助用戶解決這個問題。
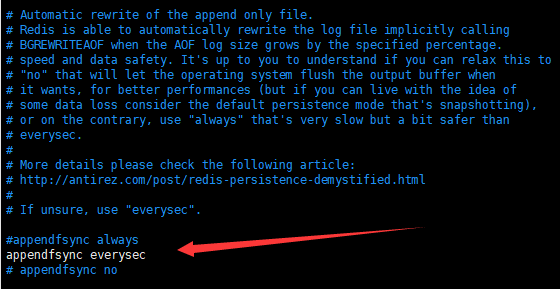
appendfsync有三種可選參數:
1.appendfsync always
代表著每一次的aof文件變更都會強制操作系統實時的寫入硬碟,這是最安全的方式,但由於這帶來了頻繁的IO,因此也是性能最差的。
2.appendfsync everysec
這是redis在配置中預設啟用的選項,代表著每秒鐘強制操作系統進行一次aof文件的硬碟同步,一秒一次的IO比起appendfsync always 每次插入都進行IO的方式,在系統繁忙時,性能上有著顯著提高。帶來的問題是:如果這一秒內出現系統故障,同步時間間隔之內的更新操作還是會丟失。
3.appendfsync no
redis 主動的進行硬碟同步操作,完全交給操作系統來同步,這是效率最高的方式。但是由於操作系統的硬碟同步時間間隔相對比較長,因此這是最不安全的方式。
用戶可以依據自己對性能和數據安全性上的綜合考量來決定同步硬碟數據的方式。
AOF總結:
上面簡單的介紹了redis的AOF持久化方式,對於AOF還有很多細節例如aof-load-truncated(當aof文件由於各種原因出現錯誤,redis啟動時初始化記憶體數據操作是否會被終止)、aof-use-rdb-preamble(是否開啟rdm,aof混合初始化)等等,在這裡就不再展開。
順帶一提:
當rdb文件和aof文件由於網路故障,系統故障等造成文件損壞時,redis提供了redis-check-rdb和redis-check-aof腳本來進行持久化文件的修複。

