
五、物理記憶體的管理 在內核初始化完成後,記憶體管理的責任由伙伴系統(高效、高速)承擔。 1、伙伴系統的結構 系統記憶體中的每個物理記憶體頁(頁幀),都對應於一個struct page實例。每個記憶體域都關聯了一個struct zone的實例,其中保存了用於管理伙伴數據的主要數組。 sruct free_ar ...
五、物理記憶體的管理
在內核初始化完成後,記憶體管理的責任由伙伴系統(高效、高速)承擔。
1、伙伴系統的結構
系統記憶體中的每個物理記憶體頁(頁幀),都對應於一個struct page實例。每個記憶體域都關聯了一個struct zone的實例,其中保存了用於管理伙伴數據的主要數組。
1 struct zone { 2 ... 3 struct free_area free_area[MAX_ORDER]; //不同長度的空閑區域 4 ... 5 } ;
sruct free_area是一個輔助結構,如下所示。
1 struct free_area { 2 struct list_head free_list[MIGRATE_TYPES]; //用於連接空閑頁的鏈表 3 unsigned long nr_free; //當前記憶體區中空閑頁塊的數目 4 };
階(order)是伙伴系統中一個非常重要的術語。它描述了記憶體分配的數量單位記憶體區的管理單位,記憶體塊的長度是2的order次方。圖1是伙伴系統中相互連接的記憶體區,記憶體區中第1頁內的鏈表元素,可用於將記憶體區維持在鏈表中。因此,也不必引入新的數據結構來管理物理上連續的頁,否則這些頁不可能在同一記憶體區中,MAX_ORDER根據硬體不同而設置不同的值,表示一次分配可以請求的最大頁數的以2為底的對數。
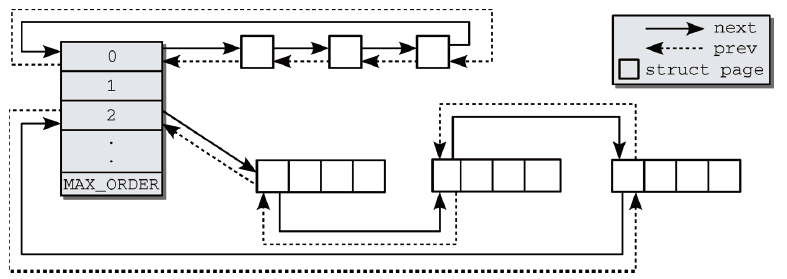
圖1 伙伴系統相互連接的記憶體區
伙伴不必是彼此連接的。如果一個記憶體區在分配其間分解為兩半,內核會自動將未用的一半加入到對應的鏈表中。如果在未來的某個時刻,由於記憶體釋放的緣故,兩個記憶體區都處於空閑狀態,可通過其地址判斷其是否為伙伴。
基於伙伴系統的記憶體管理專註於某個結點的某個記憶體域,例如,DMA或高端記憶體域。但所有記憶體域和結點的伙伴系統都通過備用分配列表連接起來。如圖2所示。
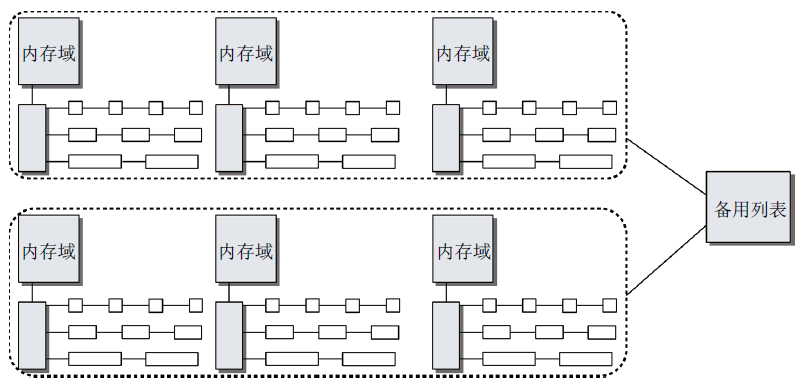
圖2 伙伴系統和記憶體域/結點之間的關係
2、避免碎片
Linux系統啟動並長期運行後,物理記憶體會產生很多碎片。這對用戶空間應用程式沒有問題(其記憶體通過頁表進行映射,物理記憶體分佈與應用程式看到的記憶體無關),但對內核來說,碎片是一個問題(大多數物理記憶體一致映射到地址空間內核部分)。
(1)依據可移動性組織頁
文件系統的碎片主要通過碎片合併工具解決,不同於物理記憶體,許多物理記憶體頁不能移動到任意位置,阻礙了該方法的實施。內核處理避免碎片的方法是反碎片(版本2.6.24),試圖從最初開始儘可能防止碎片。
內核將已分配頁劃分為以下3種不同類型:
- 不可移動頁:在記憶體中有固定位置,不能移動到其他地方。核心內核分配的大多數記憶體屬於該類別;
- 可回收頁:不能直接移動,但可以刪除,其內容可以從某些源重新生成。例如,映射自文件的數據屬於該類別,kswapd守護進程會根據可回收頁訪問的頻繁程度,周期性釋放此類記憶體;
- 可移動頁:可以隨意地移動。屬於用戶空間應用程式的頁屬於該類別。它們是通過頁表映射的。如果它們複製到新位置,頁表項可以相應地更新,應用程式不會註意到任何事。
頁的可移動性,依賴該頁屬於3種類別的哪一種。內核使用的反碎片技術,將具有相同可移動性的頁進行分組。根據頁的可移動性,將其分配到不同的列表中,防止不可移動的頁位於可移動記憶體區中間的情況出現。這樣對於不可移動頁中仍然難以找到較大的連續空閑時間,但對可回收的頁就相對容易了。
內核定義了一些巨集來表示遷移類型:
1 #define MIGRATE_UNMOVABLE 0 //類型 2 #define MIGRATE_RECLAIMABLE 1 //類型 3 #define MIGRATE_MOVABLE 2 //類型 4 #define MIGRATE_RESERVE 3 //向具有特定可移動性的列表請求分配記憶體失敗,從MIGRATE_RESERVE分配記憶體(緊急分配) 5 #define MIGRATE_ISOLATE 4 //不能從這裡分配,特殊的虛擬區域,用於跨越NUMA結點移動物理記憶體頁 6 #define MIGRATE_TYPES 5
對伙伴系統的主要數據結構影響是將空閑列表分解為MIGRATE_TYPE個列表,代碼如下:
1 struct free_area { 2 struct list_head free_list[MIGRATE_TYPES]; 3 unsigned long nr_free; //所有列表上空閑頁的數目 4 };
內核提供了一個備用列表,規定了在指定列表中無法滿足分配請求時,接下來使用的遷移類型的種類。(在內核想要分配不可移動頁時,如果對應鏈表為空,則後退到可回收頁鏈表,接下來到可移動頁鏈表,最後到緊急分配鏈表。)
頁可移動性分組特性總是編譯到內核中,但只有在系統中有足夠記憶體可以分配到多個遷移類型對應的鏈表時,才會起作用。兩個全局變數pageblock_order和pageblock_nr_pages提供每個遷移鏈表對應的適當數量的記憶體。第一個表示內核認為是“大”的一個分配階,pageblock_nr_pages則表示該分配階對應的頁數。如果體繫結構提供了巨型頁機制,則pageblock_order通常定義為巨型頁對應的分配階(IA-32巨型頁長度是4MB),如果體繫結構不支持巨型頁,則將其定義為第二高的分配階(MAX_ORDER-1)。如果各遷移類型的鏈表中沒有一塊較大的連續記憶體,那麼頁面遷移不會提供任何好處,因此在可用記憶體太少時內核會通過設置全局變數page_group_by_mobility為0關閉該特性(一旦停用了頁面遷移特性,所有頁都是不可移動的)。
在記憶體子系統初始化期間,memmap_init_zone負責處理記憶體域的page實例。它將所有的頁最初都標記為可移動的,此時如果需要分配不可移動的記憶體,則必須“盜取”(見4分配API)。實際上,啟動期間分配可移動記憶體區的情況較少,分配器有很高的幾率分配長度最大的記憶體區,並將其從可移動列表轉換到不可移動列表。由於分配的記憶體區長度是最大的,因此不會向可移動記憶體中引入碎片。這種做法避免了啟動期間內核分配的記憶體(經常在系統的整個運行時間都不釋放)散佈到物理記憶體各處,從而使其他類型的記憶體分配免受碎片的干擾,這也是頁可移動性分組框架的最重要的目標之一。
(2)虛擬可移動記憶體域
依據可移動性組織頁是防止物理記憶體碎片的一種可能方法,內核還提供了另一種阻止該問題的手段:虛擬記憶體域ZONE_MOVABLE,其特性必須由管理員顯示激活。
基本思想:可用的物理記憶體劃分為兩個記憶體域,一個用於可移動分配,一個用於不可移動分配。
kernelcore參數用來指定用於不可移動分配的記憶體數量(用於既不能回收也不能遷移的記憶體數量)。參數movablecore控制用於可移動記憶體分配的記憶體數量。如果同時指定兩個參數,內核會按照一定的方法進行計算,取指定值與計算值中較大的一個。
ZONE_MOVABLE並不關聯到任何硬體上有意義的記憶體範圍,該記憶體域中的記憶體取自高端記憶體域或普通記憶體域,因此稱虛擬記憶體域。
從物理記憶體域提取用於ZONE_MOVABLE的記憶體數量主要考慮以下兩個因素:
- 用於不可移動分配的記憶體會平均地分佈到所有記憶體結點上;
- 只使用來自最高記憶體域的記憶體(在記憶體較多的32位系統上,通常是ZONE_HIGHMEM,對於64位系統,使用ZONE_NORMAL或ZONE_DMA32)。
最後是計算結果,用於為虛擬記憶體域ZONE_MOVABLE提取記憶體頁的物理記憶體域,保存在全局變數movable_zone中;對每個結點來說,zone_movable_pfn[node_id]表示ZONE_MOVABLE在movable_zone記憶體域中所取得記憶體的起始地址。
(虛擬記憶體域具體的實現在4分配API中)
3、初始化記憶體域和結點數據結構
在啟動期間,各體繫結構相關的代碼需要確立系統中各記憶體域的頁幀的邊界(max_zone_pfn數組);確定各結點頁幀的分配情況(全局變數early_node_map)。
(1)管理數據結構的創建
圖3概述了管理數據結構建立的過程。
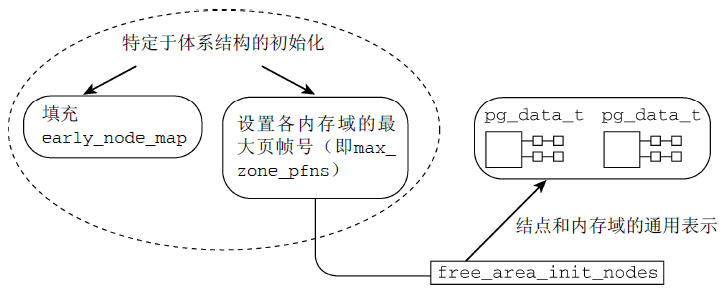
圖3 管理數據結構構建過程示意圖
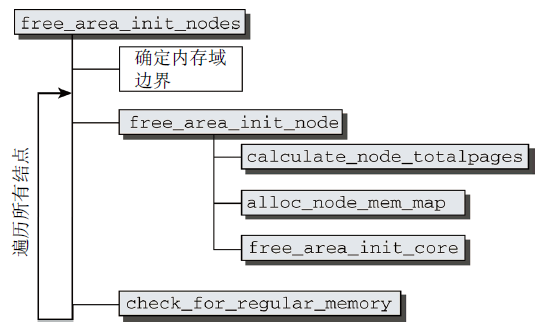
圖4 free_area_init_nodes的代碼流程圖
free_area_init_nodes代碼流程圖如圖4所示,完成以下工作:
- 首先分析並改寫特定於體繫結構的代碼提供的信息(對照在zone_max_pfn和zone_min_pfn中指定的記憶體域的邊界,計算各個記憶體域可使用的最低和最高的頁幀編號);
- 根據結點的第一個頁幀start_pfn,對early_node_map中的各項進行排序;
- 以[low, high]形式描述各個記憶體域的頁幀區間,存儲在對應的全局變數中;
- 接下來構建其他記憶體域的頁幀區間,方法很直接:第n個記憶體域的最小頁幀,即前一個(第n-1個)記憶體域的最大頁幀(當前記憶體域的最大頁幀由max_zone_pfn給出);
- 最後遍歷所有活動結點,並分別對各個結點調用free_area_init_node建立數據結構。
(2)對各個結點創建數據結構
在記憶體域邊界已經確定之後,free_area_init_nodes分別對各個記憶體域調用free_area_init_node創建數據結構。這涉及到幾個輔助函數(見圖4):
- calculate_node_totalpages首先累計各個記憶體域的頁數,計算結點中頁的總數;
- alloc_node_mem_map負責初始化一個簡單但非常重要的數據結構(struct page);
- free_area_init_core依次遍歷結點的所有記憶體域,負責初始化記憶體域數據結構涉及的繁重工作(記憶體域的真實長度、系統中的頁數、初始化zone結構中各個表頭、將各個結構成員初始化為0)。
此時,空閑頁的數目(nr_free)當前仍然規定為0,這顯然沒有反映真實情況。直至停用bootmem分配器、普通的伙伴分配器生效,才會設置正確的數值。
4、分配器API
伙伴系統介面對於NUMA和UMA體繫結構沒有差別,但是它只能分配2的整數冪個頁(分配必須指定階),內核中的細粒度分配只能藉助於slab分配器(或者slub、slob分配器)。
- alloc_pages(mask, order)分配2order頁並返回一個struct page的實例,表示分配的記憶體塊的起始頁;
- get_zeroed_page(mask)分配一頁並返回一個page實例,頁對應的記憶體填充0(所有其他函數,分配之後頁的內容是未定義的);
- __get_free_pages(mask, order)和__get_free_page(mask)的工作方式與上述函數相同,但返回分配記憶體塊的虛擬地址,而不是page實例;
- get_dma_pages(gfp_mask, order)用來獲得適用於DMA的頁。
- 有4個函數用於釋放不再使用的頁:
- free_page(struct page *)和free_pages(struct page *, order)用於將一個或2的order次冪的頁返回給記憶體管理子系統,記憶體區的起始地址由指向該記憶體區的第一個page實例的指針表示;
- __free_page(addr)和__free_pages(addr, order)的語義類似於前兩個函數,但在表示需要釋放的記憶體區時,使用了虛擬記憶體地址而不是page實例。
(1)分配掩碼
分配器API中的mask參數,稱為掩碼,它包含了圖5所示的內容。 (GFP表示get free page)

圖5 GFP掩碼佈局
- 記憶體域修飾符(最低4個比特位)用於指定從哪個記憶體孕育分配所需的頁;
- 標誌位在不限制從哪個物理記憶體段分配記憶體的基礎上,改變分配器的行為(比如查找空閑記憶體時的積極程度)。(具體含義及用法見源碼及手冊)
(2)記憶體分配巨集
通過使用標誌、記憶體域修飾符和各個分配函數,內核提供了一種非常靈活的記憶體分配體系,所有介面函數都可以追溯到一個基本函數alloc_pages_node,如圖6所示。

圖6 伙伴系統的各分配函數之間關係
- 分配單頁的函數alloc_page和__get_free_page是藉助於巨集定義的,alloc_pages也是同樣;
- get_zeroed_page的實現是對alloc_pages使用__GFP_ZERO標誌,即可分配填充位元組0的頁;
- __get_free_pages訪問了alloc_pages,而alloc_pages又藉助了alloc_pages_node。
類似地,記憶體釋放函數也可以歸約到一個主要的函數__free_pages,如圖7所示(只是調用參數不同)。
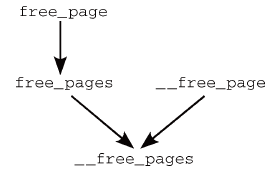
圖7 伙伴系統各記憶體釋放函數之間關係
free_pages和__free_pages之間的關係通過函數而不是巨集建立,因為首先必須將虛擬地址轉換為指向struct page的指針。
5、分配頁
內核源代碼將__alloc_pages稱之為“伙伴系統的心臟”,因為它處理的是實質性的記憶體分配。
(1)選擇頁
內核定義了一些函數使用的標誌,用於控制到達各水印指定的臨界狀態時的行為。
#define ALLOC_NO_WATERMARKS 0x01 /* 完全不檢查水印 */ #define ALLOC_WMARK_MIN 0x02 /* 使用pages_min水印 */ #define ALLOC_WMARK_LOW 0x04 /* 使用pages_low水印 */ #define ALLOC_WMARK_HIGH 0x08 /* 使用pages_high水印 */ #define ALLOC_HARDER 0x10 /* 試圖更努力地分配,即放寬限制 */ #define ALLOC_HIGH 0x20 /* 設置了__GFP_HIGH */ #define ALLOC_CPUSET 0x40 /* 檢查記憶體結點是否對應著指定的CPU集合 */
預設情況下(即沒有因其他因素帶來的壓力而需要更多的記憶體),只有記憶體域包含頁的數目至少為zone->pages_high時,才能分配頁。這對應於ALLOC_WMARK_HIGH標誌。如果要使用較低(zone->pages_low)或最低(zone->pages_min)設置,則必須相應地設置ALLOC_WMARK_MIN或ALLOC_WMARK_LOW。ALLOC_HARDER通知伙伴系統在急
需記憶體時放寬分配規則。在分配高端記憶體域的記憶體時,ALLOC_HIGH進一步放寬限制。最後,ALLOC_CPUSET告知內核,記憶體只能從當前進程允許運行的CPU相關聯的記憶體結點分配,當然該選項只對NUMA系統有意義。
__alloc_pages是伙伴系統的主函數,函數比較復長,可用記憶體足夠時必要工作很快完成,可用記憶體太少或逐漸用完時,函數就會變得比較複雜。
在最簡單的情形中,分配空閑記憶體區只涉及調用一次get_page_from_freelist,然後返回所需數目的頁(由標號got_pg處的代碼處理)。
其他情況中,會進行多次記憶體分配嘗試:
- 第一次記憶體分配嘗試不會特別積極。如果在某個記憶體域中無法找到空閑記憶體,則意味著記憶體沒剩下多少了,內核需要增加較多的工作量才能找到更多記憶體。內核再次遍歷備用列表中的所有記憶體域,每次都會喚醒負責換出頁的kswapd守護進程(任務見頁面回收和頁同步),此時,空閑記憶體可以通過縮減內核緩存和頁面回收穫得。
- 此後,內核開始新的嘗試,在記憶體域之一查找適當的記憶體塊。這一次進行的搜索更為積極,對分配標誌進行了調整,修改為一些在當前特定情況下更有可能分配成功的標誌。同時,將水印降低到最小值。然後用修改的標誌集,再一次調用get_page_from_freelist,試圖獲得所需的頁。
- 如果再次失敗,若設置了PF_MEMALLOC或進程設置了TIF_MEMDIE標誌,會再次調用get_page_from_freelist試圖獲得所需的頁(完全忽略水印);若沒有設置PF_MEMALLOC,內核仍然還有一些選項可以嘗試,進入一條低速路徑,分配掩碼中設置__GFP_WAIT標誌,為使守護進程取得一定的進展,其他進程可能進入睡眠狀態,然後使用輔助函數try_to_free_pages查找當前不急需的頁,以便換出(如果需要分配多頁,那麼per-CPU緩存中的頁也會被try_to_free_pages拿回到伙伴系統),最後內核再次調用get_page_from_freelist嘗試分配記憶體。
- 如果依然申請不到記憶體(會涉及到一些對VFS層的影響,此處不作介紹),內核只能放棄,並向用戶返回NULL指針,並輸出一條記憶體請求無法滿足的警告消息。
(2)移除選擇的頁
如果內核找到適當的記憶體域,具有足夠的空閑頁可供分配,那麼還有兩件事情需要完成。首先它必須檢查這些頁是否是連續的;其次,必須按伙伴系統的方式從free_lists移除這些頁,這可能需要分解並重排記憶體區。
內核將工作委托給輔助函數buffered_rmqueue完成,其代碼流程圖如圖8所示。
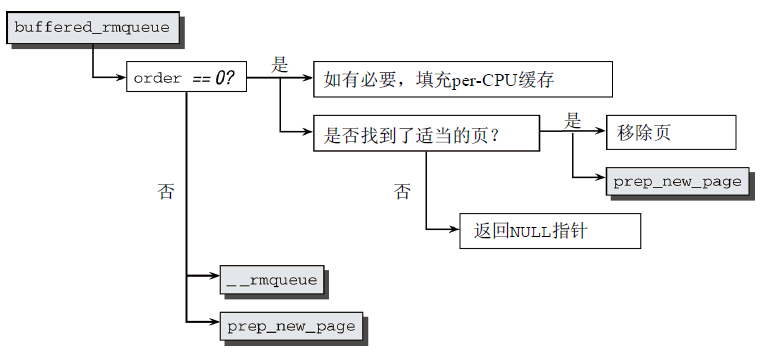
圖8 buffered_rmqueue代碼流程圖
首先,判斷階數,若為0,則表示只請求一頁。此時,內核試圖藉助於per-CPU緩存加速請求的處理。如果緩存為空,內核可藉機檢查緩存填充水平。如果per-CPU緩存中無法找到適當的頁,則向緩存添加一些符合當前要求遷移類型的頁,然後從per-CPU列表移除一頁,接下來進一步處理。
若不是0,則表示請求多頁。內核調用__rmqueue(要求頁連續)會從記憶體域的伙伴列表中選擇適當的記憶體塊。如有必要,該函數會自動分解大塊記憶體,將未用的部分放回列表中。若分配失敗,則會返回NULL指針。所有失敗情形都跳轉到標號failed處理,這可以確保內核到達當前點之後,page指向一系列有效的頁。在返回指針之前,prep_new_page需要做一些準備工作,以便內核能夠處理這些頁(如果所選擇的頁出了問題,則該函數返回正值。在這種情況下,分配將從頭重新開始)。
6、釋放頁
__free_pages是一個基礎函數,用於實現內核API中所有涉及記憶體釋放的函數。其代碼流程圖如圖9所示。
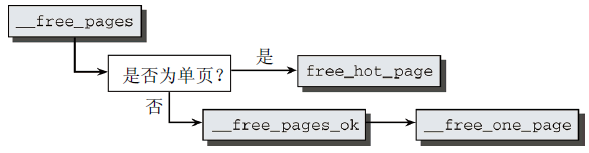
圖9 __free_pages代碼流程圖
__free_pages首先判斷所需釋放的記憶體是單頁還是較大的記憶體塊?如果釋放單頁,則不還給伙伴系統,而是置於per-CPU緩存中,對很可能出現在CPU高速緩存的頁,則放置到熱頁的列表中。出於該目的,內核提供了free_hot_page輔助函數,該函數只是作一下參數轉換,接下來調用free_hot_cold_page。如果釋放多個頁,那麼__free_pages將工作委托給__free_pages_ok,最後到__free_one_page。與其名稱不同,該函數不僅處理單頁的釋放,也處理複合頁釋放。
7、內核中不連續頁的分配
物理上連續的映射對內核是最優的,但不可能總是成功使用。對此,內核分配了其虛擬地址空間的一部分,用於建立連續映射。如圖10所示,在IA-32系統中,緊隨直接映射的前892 MiB物理記憶體,在插入的8 MiB安全隙之後,是一個用於管理不連續記憶體的區域。這一段具有線性地址空間的所有性質。通過修改負責該區域的內核頁表,可以將其中的頁映射到物理記憶體的任何地方。每個vmalloc分配的子區域都是自包含的,與其他vmalloc子區域通過一個記憶體頁分隔。類似於直接映射和vmalloc區域之間的邊界,不同vmalloc子區域之間的分隔也是為防止不正確的記憶體訪問操作。
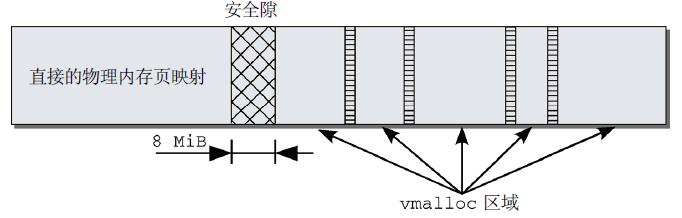
圖10 IA-32系統上內核的虛擬地址空間中的vmalloc區域
(1)用vmalloc分配記憶體
vmalloc是一個介面函數,內核使用它來分配虛擬記憶體中連續但在物理記憶體中不一定連續的記憶體。
void *vmalloc(unsigned long size);
該函數只需要一個參數,用於指定所需記憶體區的長度(位元組)。
內核對模塊的實現中,有很多使用vmalloc的地方,因為函數可能在任何時候載入,如果模塊數比較多,那麼無法保證有足夠的連續記憶體可用(尤其是系統已經運行了比較長時間的情況下)。因為用於vmalloc的記憶體頁總是必須映射在內核地址空間中,因此使用ZONE_HIGHMEM記憶體域的頁要優於其他記憶體域。這使得內核可以節省更寶貴的較低端記憶體域,而又不會帶來額外的壞處。
vmalloc的代碼流程圖如圖11所示。

圖11 vmalloc代碼流程圖
vmalloc的實現分為三個部分,首先,get_vm_area在vmalloc地址空間中找到一個適當的區域。接下來從物理記憶體分配各個頁,最後將這些頁連續地映射到vmalloc區域中,完成分配虛擬記憶體的工作。
(2)備選映射方法
- 除了vmalloc之外,還有其他方法可以創建虛擬連續映射:
- vmalloc_32的工作方式與vmalloc相同,但會確保所使用的物理記憶體總是可以用普通32位指針定址;
- vmap使用一個page數組作為起點,來創建虛擬連續記憶體區;
- 不同於上述的所有映射方法,ioremap是一個特定於體繫結構上的函數,它將取自物理地址空間、由系統匯流排用於I/O操作的一個記憶體塊,映射到內核的地址空間中。
(3)釋放記憶體
有兩個函數用於向內核釋放記憶體,vfree用於釋放vmalloc和vmalloc_32分配的區域,而vunmap用於釋放由vmap或ioremap創建的映射。兩個函數都會歸結到__vunmap。其代碼流程圖如圖12所示。
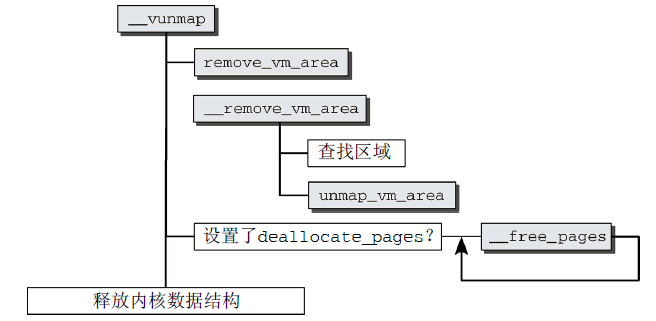
圖12 __vunmap代碼流程圖
- __vunmap首先在__remove_vm_area(由remove_vm_area在完成鎖定之後調用)中掃描該鏈表,以找到相關項;
- 然後使用找到的vm_area實例,從頁表刪除不再需要的項;
- 如果__vunmap的參數deallocate_pages設置為1(在vfree中),內核會遍歷指向所涉及的物理記憶體頁的page實例的指針,然後對每一項調用__free_page,將頁釋放到伙伴系統;
- 最後釋放用於管理該記憶體區的內核數據結構。
8、內核映射
儘管vmalloc函數族可用於從高端記憶體域向內核映射頁幀,但這並不是這些函數的實際用途。內核提供了其他函數用於將ZONE_HIGHMEM頁幀顯式映射到內核空間。
(1)持久內核映射
如果需要將高端頁幀長期映射(作為持久映射)到內核地址空間中,必須使用kmap函數。需要映射的頁用指向page的指針指定,作為該函數的參數。如果沒有啟用高端支持,該函數只需要返回頁的地址;如果啟用了高端支持,則類似於vmalloc,內核首先必須建立高端頁和所映射到的地址之間的關聯,在虛擬地址空間中分配一個區域以映射頁幀,最後,內核必須記錄該虛擬區域的哪些部分在使用中,哪些仍然是空閑的。
內核在IA-32平臺上vmalloc區域之後分配了一個區域,從PKMAP_BASE到FIXADDR_START,該區域用於持久映射,不同體繫結構使用的方案是類似的。
(pkmap_count是一容量為LAST_PKMAP的整數數組,其中每個元素都對應於一個持久映射頁。它實際上是被映射頁的一個使用計數器,0意味著相關的頁沒有使用,1有特殊語義,n代表內核中有n-1處使用該頁(n≥2)。)
用kmap映射的頁,如果不再需要,必須用kunmap解除映射。
(2)臨時內核映射
kmap函數不能用於中斷處理程式,因為它可能進入睡眠狀態(pkmap數組中沒有空閑位置時)。內核提供了kmap_atomic,該函數執行是原子的,比普通的kmap快速,不能用於可能進入睡眠的代碼,對於很快就需要一個臨時頁的簡短代碼是非常理想的。
kmap_atomic的定義在IA-32、PPC、Sparc32上是特定於體繫結構的,但這3種實現只有非常細微的差別,其原型是相同的。
void *kmap_atomic(struct page *page, enum km_type type) //page是一個指向高端記憶體頁的管理結構的指針,type定義了所需的映射類型
(內核的固定映射機制,使之可以在內核地址空間中訪問用於建立原子映射的記憶體。可以在FIX_KMAP_BEGIN和FIX_KMAP_END之間建立一個用於映射高端記憶體頁的區域,該區域位於fixed_addresses數組中,準確的位置需要根據當前活動的CPU和所需映射類型計算。)
在使用kmap_atomic時不會阻塞。如果發生阻塞,那麼另一個進程可能建立同樣類型的映射,覆蓋現存的項。
kunmap_atomic函數從虛擬記憶體解除一個現存的原子映射,該函數根據映射類型和虛擬地址,從頁表刪除對應的項。
(3)沒有高端記憶體的電腦上的映射函數
許多體繫結構不需要支持高端記憶體(比如AMD64),為了不需要總是區分高端記憶體和非高端記憶體體繫結構,內核定義了幾個在普通記憶體實現相容函數的巨集(在支持高端記憶體的電腦上,如果停用了高端記憶體,也會使用這些巨集)。
1 #ifdef CONFIG_HIGHMEM 2 ... 3 #else 4 static inline void *kmap(struct page *page) 5 { 6 might_sleep(); 7 return page_address(page); 8 } 9 #define kunmap(page) do { (void) (page); } while (0) 10 #define kmap_atomic(page, idx) page_address(page) 11 #define kunmap_atomic(addr, idx) do { } while (0) 12 #endif
六、slab分配器
類似於C語言中的malloc,slab分配器提供小塊記憶體,同時它也用作一個緩存,主要針對經常分配並釋放的對象。slab分配器將釋放記憶體塊保存在一個內部列表中,並不馬上返回給伙伴系統,以便下一次高速的記憶體分配。這樣內核不必使用伙伴系統演算法,處理時間會變短,同時該記憶體塊仍然駐留在CPU告訴緩存的概率較高。
slab分配器有兩大好處:
- 調用伙伴系統的操作對系統的數據和指令高速緩存有相當的影響。內核越浪費這些資源,這些資源對用戶空間進程就越不可用。更輕量級的slab分配器在可能的情況下減少了對伙伴系統的調用。
- 如果數據存儲在伙伴系統直接提供的頁中,那麼其地址總是出現在2的冪次的整數倍附近(許多將頁劃分為更小塊的其他分配方法,也有同樣的特征)。這對CPU高速緩存的利用有負面影響,由於這種地址分佈,使得某些緩存行過度使用,而其他的則幾乎為空。多處理器系統可能會加劇這種不利情況,因為不同的記憶體地址可能在不同的匯流排上傳輸,上述情況會導致某些匯流排擁塞,而其他匯流排則幾乎沒有使用。通過slab著色(slab coloring),slab分配器能夠均勻地分佈對象,以實現均勻的緩存利用。
1、備選分配器
在大型系統上僅slab的數據結構就需要很多GB記憶體。對嵌入式系統來說,slab分配器代碼量和複雜性都太高,因此誕生了slob分配器和slub分配器。
slob分配器進行了特別優化,以便減少代碼量。它圍繞一個簡單的記憶體塊鏈表展開,在分配記憶體時,使用了同樣簡單的最先適配演算法(速度非最高效,不適用大型系統);
slub分配器通過將頁幀打包為組,並通過struct page中未使用的欄位來管理這些組,試圖最小化所需的記憶體開銷。
所有分配器的前端介面都是相同的。每個分配器都實現了一組特定的函數,用於記憶體分配和緩存。
- kmalloc、__kmalloc和kmalloc_node是一般的(特定於結點)記憶體分配函數;
- kmem_cache_alloc、kmem_cache_alloc_node提供(特定於結點)特定類型的內核緩存。
圖13闡釋了物理頁幀、伙伴系統、通用分配器與一般內核代碼介面關聯。
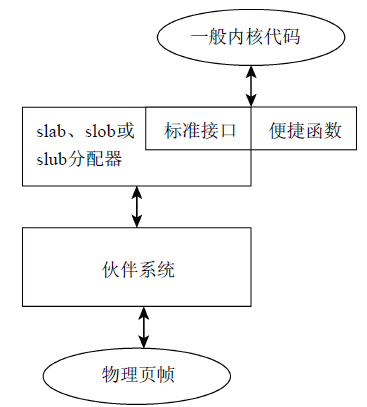
圖13 伙伴系統、通用分配器與一般內核代碼介面關聯示意圖
2、內核中的記憶體管理
內核中一般的記憶體分配和釋放函數與C標準庫中等價函數的名稱類似,用法也幾乎相同。
- kmalloc(size, flags)分配長度為size位元組的一個記憶體區,並返回指向該記憶體區起始處的一個void指針,如果沒有足夠記憶體,則結果為NULL指針;
- kfree(*ptr)釋放*ptr指向的記憶體區。
與用戶空間程式設計相比,內核還包括percpu_alloc和percpu_free函數,用於為各個系統CPU分配和釋放所需記憶體區。
所有活動緩存的列表保存在/proc/slabinfo中(終端輸入cat /proc/slabinfo即可查看),包含用於標識各個緩存的字元串名稱,緩存中活動對象的數量,緩存中對象的總數(已用和未用),所管理對象的長度(按位元組計算),一個slab中對象的數量,每個slab中頁的數量,活動slab的數量,在內核決定向緩存分配更多記憶體時,所分配對象的數量。
3、slab分配的原理
slab分配器由一個緊密地交織的數據和記憶體結構的網路組。如圖14所示,slab緩存由保存管理性數據的緩存對象和保存被管理對象的各個slab。
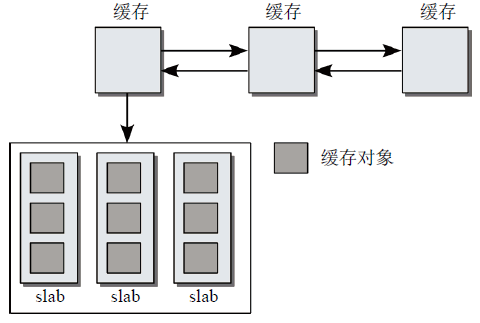
圖14 slab分配器各個部分
每個緩存只負責一種對象類型,或提供一般性的緩衝區。各個緩存中slab的數目各有不同,這與已經使用的頁的數目、對象長度和被管理對象的數目有關。
系統中所有的緩存都保存在一個雙鏈表中。這使得內核有機會依次遍歷所有的緩存。
(1)緩存的精細結構
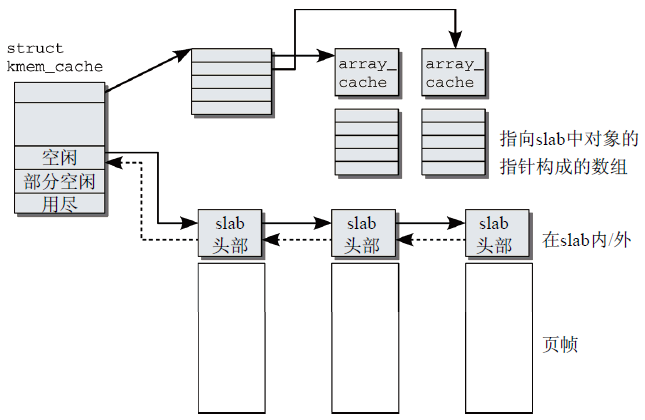
圖15 slab緩存的精細結構
圖15描述了緩存各組成部分,除了管理性數據,緩存結構包括兩個特別重要的成員:
- 指向一個數組的指針,其中保存了各個CPU最後釋放的對象;
- 每個記憶體結點都對應3個表頭,用於組織slab的鏈表。第1個鏈表包含完全用盡的slab,第2個是部分空閑的slab,第3個是空閑的slab。
緩存結構指向一個數組,其中包含了與系統CPU數目相同的數組項。每個元素都是一個指針,指向一個進一步的結構稱之為數組緩存(array cache),其中包含了對應於特定系統CPU的管理數據(就總體來看,不是用於緩存)。管理性數據之後的記憶體區包含了一個指針數組,各個數組項指向slab中未使用的對象。
為最好地利用CPU高速緩存,在分配和釋放對象時,採用後進先出原理(LIFO,last in first out)。內核假定剛釋放的對象仍然處於CPU高速緩存中,會儘快再次分配它。僅當per-CPU緩存為空時,才會用slab中的空閑對象重新填充它們。這樣,對象分配的體系就形成了一個三級的層次結構(分配成本和操作對CPU高速緩存和TLB的負面影響逐級升高):
- 仍然處於CPU高速緩存中的per-CPU對象;
- 現存slab中未使用的對象;
- 剛使用伙伴系統分配的新slab中未使用的對象。
(2)slab精細結構
用於每個對象的長度進行了舍入,以滿足某些對齊方式的要求,對於對齊方案,有兩種:
slab創建時使用標誌SLAB_HWCACHE_ALIGN,slab用戶可以要求對象按硬體緩存行對齊;
如果不要求按硬體緩存行對齊,那麼內核保證對象按BYTES_PER_WORD對齊,該值是表示void指針所需位元組的數目。
在32位處理器上,void指針需要4個位元組。因此,對有6個位元組的對象,則需要8 = 2×4個位元組,多餘的位元組稱為填充位元組。填充位元組可以加速對slab中對象的訪問,如果使用對齊的地址,那麼在幾乎所有的體繫結構上,記憶體的訪問都會更快。
slab的起始處是管理結構,保存了所有的管理數據(和用於連接緩存鏈表的鏈表元素)。其後面是一個數組,每個(整數)數組項對應於slab中的一個對象(只有在對象沒有分配時,相應的數組項才有意義)。此時,它指定了下一個空閑對象的索引。由於最低編號的空閑對象的編號還保存在slab起始處的管理結構中,內核無需使用鏈表或其他複雜的關聯機制,即可找到當前可用的所有對象。數組的最後一項總是一個結束標記,值為BUFCTL_END。管理數組與slab對象的關係如圖16所示。
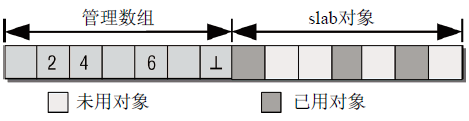
圖16 slab中空閑對象的管理
管理數據可以放置在slab自身,也可以放置到使用kmalloc分配的不同記憶體區中。內核的選擇取決於slab的長度和已用對象的數量。
最後,內核通過對象自身(page結構的一個鏈表元素lru.next和lru.prev)識別slab(以及對象駐留的緩存)。根據對象的物理記憶體地址,找到相關的頁,從而在全局mem_map數組中找到對應的page實例。
4、實現
slab系統帶有大量調試選項,代碼中遍佈著預處理語句:
- 危險區(Red Zoning):在每個對象的開始和結束處增加一個額外的記憶體區,其中填充已知的位元組模式。如果模式被修改,程式員在分析內核記憶體時註意到,可能某些代碼訪問了不屬於它們的記憶體區;
- 對象毒化(Object Poisoning):在建立和釋放slab時,將對象用預定義的模式填充。如果在對象分配時註意到該模式已經改變,此處已經發生了未授權訪問等。
(1)數據結構
每個緩存由kmem_cache結構的一個實例表示。結構內容如下:
1 struct kmem_cache { 2 /* 1) per-CPU數據,在每次分配/釋放期間都會訪問 */ 3 struct array_cache *array[NR_CPUS]; //指向數組的指針,每個數組項都對應於系統中的一個CPU。每個數組項都包含了另一個指針,指向下文討論的array_cache結構的實例 4 /* 2) 可調整的緩存參數。由cache_chain_mutex保護 */ 5 unsigned int batchcount; //per-CPU列表為空時,從緩存的slab中獲取對象的數目;還表示在緩存增長時分配的對象數目 6 unsigned int limit; //指定了per-CPU列表中保存的對象的最大數目 7 unsigned int shared; 8 unsigned int buffer_size; //指定了緩存中管理的對象的長度 9 u32 reciprocal_buffer_size; 10 /* 3) 後端每次分配和釋放記憶體時都會訪問 */ 11 unsigned int flags; /* 常數標誌 */ 12 unsigned int num; /* 每個slab中對象的數量 */ 13 /* 4) 緩存的增長/縮減 */ 14 unsigned int gfporder; //指定了slab包含的頁數目以2為底的對數 15 /* 強制的GFP標誌,例如GFP_DMA */ 16 gfp_t gfpflags; 17 size_t colour; //顏色的最大數目 18 unsigned int colour_off; //著色偏移 19 struct kmem_cache *slabp_cache; //slab頭部的管理數據存儲在slab外部時,指向分配所需記憶體的一般性緩存; slab頭部在slab上時,為NULL指針 20 unsigned int slab_size; 21 unsigned int dflags; // 標誌集合,描述slab的“動態性質” 22 void (*ctor)(struct kmem_cache *, void *); //指向在對象創建時調用的構造函數 23 /* 5) 緩存創建/刪除 */ 24 const char *name; //是一個字元串,包含該緩存的名稱 25 struct list_head next; //用於將kmem_cache的所有實例保存在全局鏈表cache_chain上 26 /* 6) 統計量 */ 27 ... 28 struct kmem_list3 *nodelists[MAX_NUMNODES]; 29 };
(2)初始化
為初始化slab數據結構,內核需要若幹小記憶體塊(最適合由kmalloc分配),但是只有slab系統啟用之後,才能使用kmalloc,因而內核藉助了一些技巧。
kmem_cache_init函數用於初始化slab分配器。它在內核初始化階段(start_kernel)、伙伴系統啟用之後調用。第一步:kmem_cache_init創建系統中的第一個slab緩存,以便為kmem_cache的實例提供記憶體,內核使用的主要是在編譯時創建的靜態數據;第二步:kmem_cache_init接下來初始化一般性的緩存,用作kmalloc記憶體的來源(針對所需的各個緩存長度,分別調用kmem_cache_create);第三步:在kmem_cache_init的最後一步,把到現在為止一直使用的數據結構的所有靜態實例化的成員,用kmalloc動態分配的版本替換。
(3)創建緩存
創建新的slab緩存必須調用kmem_cache_create,這是一個冗長的過程,其代碼示意圖如圖17所示。
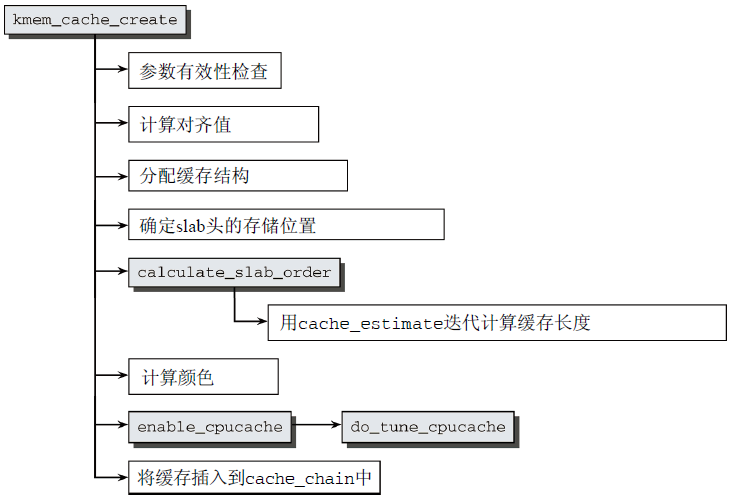
圖17 kmem_cache_create的代碼流程圖
- 首先,進行參數檢查,以確保沒有指定無效值,然後才執行第一個重要步驟,計算對齊所需填充位元組數;
- 接著在數據對齊值計算完畢後,分配struct kmem_cache一個實例(一個獨立的slab緩存,名為cache_cache);
- 然後確定是否將slab頭存儲在slab之上,如果對象長度大於頁幀的1/8,則將頭部管理數據存儲在slab之外,否則存儲在slab上,隨後,增加對象的長度size,直至對應到上文計算的對齊值;
- 至此,對象長度定義完成,以下定義slab長度(選擇適當的頁數作為slab長度)。
- 首先,內核通過calculate_slab_order進行迭代,找到理想的slab長度(基於給定對象長度,cache_estimate針對特定的頁數,來計算對象數目、浪費的空間、著色所需的空間);
- 接著計算顏色(即slab上的浪費空間除以顏色偏移量的商);
- 然後通過enable_cpucache產生per-CPU緩存;
- 最後將初始化過的kmem_cache實例添加到全局鏈表,表頭為cache_chain。
(4)分配對象
kmem_cache_alloc用於從特定的緩存獲取對象,它需要用於獲取對象的緩存,以及精確描述分配特征的標誌變數兩個參數,結果可能是指向分配記憶體區的指針,也可能分配失敗返回NULL。
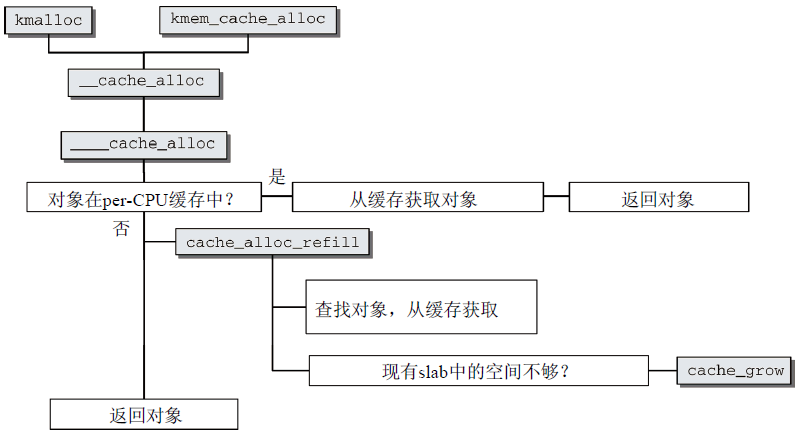
圖18 kmem_cache_alloc的代碼流程圖
- 首先,kmem_cache_alloc基於參數相同的內部函數__cache_alloc,後者可以直接調用(採用這種結構,目的是儘快合併kmalloc和kmem_cache_alloc的實現)。__cache_allloc只是一個前端函數,只執行了所有必要的鎖定操作。實際工作委托給____cache_alloc進行;
- 然後選擇被緩存對象,如果在per-CPU緩存中有對象,則從緩存中獲取對象後返回;如果沒有對象在per-CPU緩存中,需要調用cache_alloc_refill重新填充緩存,內核先按一定的順序掃描slab,如果找到空閑對象則返回,如果沒有找到空閑對象,那麼必須使用cache_grow擴大緩存(見下)。
(5)緩存的增長
圖19描述了cache_grow代碼流程圖。

圖19 cache_grow的代碼流程圖
- 首先計算顏色和偏移量,如果達到了顏色的最大數目,則內核重新開始從0計數,這自動導致零偏移;
- 接著使用kmem_getpages輔助函數從伙伴系統逐頁分配所需的記憶體空間;
- 然後調用相關的alloc_slabmgmt函數分配所需空間;
- 接下來,調用slab_map_pages創建slab的各頁與slab或緩存之間的關聯;
- 隨後cache_init_objs調用各個對象的構造器函數(假如有的話),初始化新slab中的對象;
- 最後將完全初始化的slab添加到緩存的slabs_free鏈表中。
(6)釋放對象
當一個分配的對象不再需要時,使用kmem_cache_free將其返回給


