
在安裝和測試hive之前,我們需要把Hadoop的所有服務啟動 在安裝Hive之前,我們需要安裝mysql資料庫 ...
在安裝和測試hive之前,我們需要把Hadoop的所有服務啟動
在安裝Hive之前,我們需要安裝mysql資料庫
--mysql的安裝 - (https://segmentfault.com/a/1190000003049498) --檢測系統是否自帶安裝mysql yum list installed | grep mysql --刪除系統自帶的mysql及其依賴 yum -y remove mysql-libs.x86_64 --給CentOS添加rpm源,並且選擇較新的源 wget dev.mysql.com/get/mysql-community-release-el6-5.noarch.rpm yum localinstall mysql-community-release-el6-5.noarch.rpm yum repolist all | grep mysql yum-config-manager --disable mysql55-community yum-config-manager --disable mysql56-community yum-config-manager --enable mysql57-community-dmr yum repolist enabled | grep mysql --安裝mysql 伺服器 yum install mysql-community-server --啟動mysql service mysqld start --查看mysql是否自啟動,並且設置開啟自啟動 chkconfig --list | grep mysqld chkconfig mysqld on --查找初始化密碼 grep 'temporary password' /var/log/mysqld.log --mysql安全設置 mysql_secure_installation --啟動mysql service mysqld start --登錄 mysql –u root –p --設置的密碼 !QAZ2wsx3edc --開通遠程訪問 grant all on *.* to root@'%' identified by '!QAZ2wsx3edc'; select * from mysql.user; --讓node1也可以訪問 grant all on *.* to root@'node1' identified by '!QAZ2wsx3edc'; --創建hive資料庫,後面要用到,hive不會 自動創建 create database hive;
安裝和配置Hive
--安裝Hive cd ~ tar -zxvf apache-hive-0.13.1-bin.tar.gz --創建軟鏈 ln -sf /root/apache-hive-0.13.1-bin /home/hive --修改配置文件 cd /home/hive/conf/ cp -a hive-default.xml.template hive-site.xml --啟動Hive cd /home/hive/bin/ ./hive --退出hive quit; --修改配置文件 cd /home/hive/conf/ vi hive-site.xml --以下需要修改的地方 <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1/hive</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>!QAZ2wsx3edc</value> <description>password to use against metastore database</description> </property> :wq
添加mysql驅動
--拷貝mysql驅動到/home/hive/lib/ cp -a mysql-connector-java-5.1.23-bin.jar /home/hive/lib/
在這裡我寫了一個生成文件的java文件
GenerateTestFile.java
import java.io.BufferedWriter; import java.io.File; import java.io.FileWriter; import java.util.Random; /** * @author Hongwei * @created 31 Oct 2018 */ public class GenerateTestFile { public static void main(String[] args) throws Exception{ int num = 20000000; File writename = new File("/root/output1.txt"); System.out.println("begin"); writename.createNewFile(); BufferedWriter out = new BufferedWriter(new FileWriter(writename)); StringBuilder sBuilder = new StringBuilder(); for(int i=1;i<num;i++){ Random random = new Random(); sBuilder.append(i).append(",").append("name").append(i).append(",") .append(random.nextInt(50)).append(",").append("Sales").append("\n"); } System.out.println("done........"); out.write(sBuilder.toString()); out.flush(); out.close(); } }
編譯和運行文件:
cd
javac GenerateTestFile.java
java GenerateTestFile
最終就會生成/root/output1.txt文件,為上傳測試文件做準備。
啟動Hive
--啟動hive
cd /home/hive/bin/
./hive
創建t_tem2表
create table t_emp2( id int, name string, age int, dept_name string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
輸出結果:
hive> create table t_emp2( > id int, > name string, > age int, > dept_name string > ) > ROW FORMAT DELIMITED > FIELDS TERMINATED BY ','; OK Time taken: 0.083 seconds
上傳文件
load data local inpath '/root/output1.txt' into table t_emp2;
輸出結果:
hive> load data local inpath '/root/output1.txt' into table t_emp2; Copying data from file:/root/output1.txt Copying file: file:/root/output1.txt Loading data to table default.t_emp2 Table default.t_emp2 stats: [numFiles=1, numRows=0, totalSize=593776998, rawDataSize=0] OK Time taken: 148.455 seconds
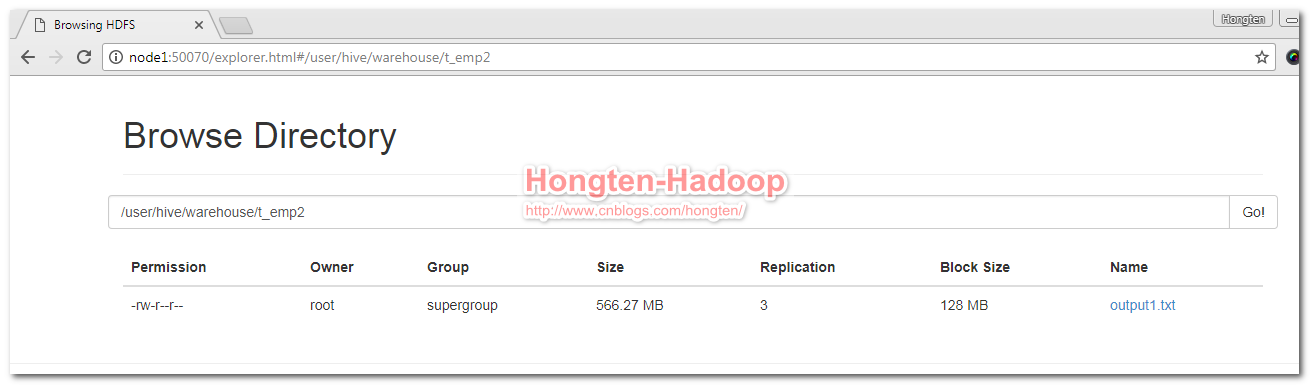

測試,查看t_temp2表裡面所有記錄的總條數:
hive> select count(*) from t_emp2; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1541003514112_0002, Tracking URL = http://node1:8088/proxy/application_1541003514112_0002/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1541003514112_0002 Hadoop job information for Stage-1: number of mappers: 3; number of reducers: 1 2018-10-31 09:41:49,863 Stage-1 map = 0%, reduce = 0% 2018-10-31 09:42:26,846 Stage-1 map = 33%, reduce = 0%, Cumulative CPU 33.56 sec 2018-10-31 09:42:47,028 Stage-1 map = 44%, reduce = 0%, Cumulative CPU 53.03 sec 2018-10-31 09:42:48,287 Stage-1 map = 56%, reduce = 0%, Cumulative CPU 53.79 sec 2018-10-31 09:42:54,173 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 56.99 sec 2018-10-31 09:42:56,867 Stage-1 map = 78%, reduce = 0%, Cumulative CPU 57.52 sec 2018-10-31 09:42:58,201 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 58.44 sec 2018-10-31 09:43:16,966 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 60.62 sec MapReduce Total cumulative CPU time: 1 minutes 0 seconds 620 msec Ended Job = job_1541003514112_0002 MapReduce Jobs Launched: Job 0: Map: 3 Reduce: 1 Cumulative CPU: 60.62 sec HDFS Read: 593794153 HDFS Write: 9 SUCCESS Total MapReduce CPU Time Spent: 1 minutes 0 seconds 620 msec OK 19999999 Time taken: 105.013 seconds, Fetched: 1 row(s)
查詢表中age=20的記錄總條數:
hive> select count(*) from t_emp2 where age=20; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1541003514112_0003, Tracking URL = http://node1:8088/proxy/application_1541003514112_0003/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1541003514112_0003 Hadoop job information for Stage-1: number of mappers: 3; number of reducers: 1 2018-10-31 09:44:28,452 Stage-1 map = 0%, reduce = 0% 2018-10-31 09:44:45,102 Stage-1 map = 11%, reduce = 0%, Cumulative CPU 5.54 sec 2018-10-31 09:44:49,318 Stage-1 map = 33%, reduce = 0%, Cumulative CPU 7.63 sec 2018-10-31 09:45:14,247 Stage-1 map = 44%, reduce = 0%, Cumulative CPU 13.97 sec 2018-10-31 09:45:15,274 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 14.99 sec 2018-10-31 09:45:41,594 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 18.7 sec 2018-10-31 09:45:50,973 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 26.08 sec MapReduce Total cumulative CPU time: 26 seconds 80 msec Ended Job = job_1541003514112_0003 MapReduce Jobs Launched: Job 0: Map: 3 Reduce: 1 Cumulative CPU: 33.19 sec HDFS Read: 593794153 HDFS Write: 7 SUCCESS Total MapReduce CPU Time Spent: 33 seconds 190 msec OK 399841 Time taken: 98.693 seconds, Fetched: 1 row(s)
========================================================
More reading,and english is important.
I'm Hongten
大哥哥大姐姐,覺得有用打賞點哦!你的支持是我最大的動力。謝謝。
Hongten博客排名在100名以內。粉絲過千。
Hongten出品,必是精品。
E | [email protected] B | http://www.cnblogs.com/hongten
========================================================


