
字元串的創建 字元串創建符號 ' ' " " ''' ''' """ """ 轉義符\ >>> string_long = """This is another long string ... value that will span multiple ... lines in the output ...
字元串的創建
字元串創建符號
' '
" "
''' '''
""" """
轉義符\
>>> string_long = """This is another long string
... value that will span multiple
... lines in the output"""
>>> print(string_long)
This is another long string
value that will span multiple
lines in the output
>>> string_long
'This is another long string\nvalue that will span multiple\nlines in the output'字元串索引
字元串:bright Hello!
| b | r | i | g | h | t | H | e | l | l | o | ! | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |


案例

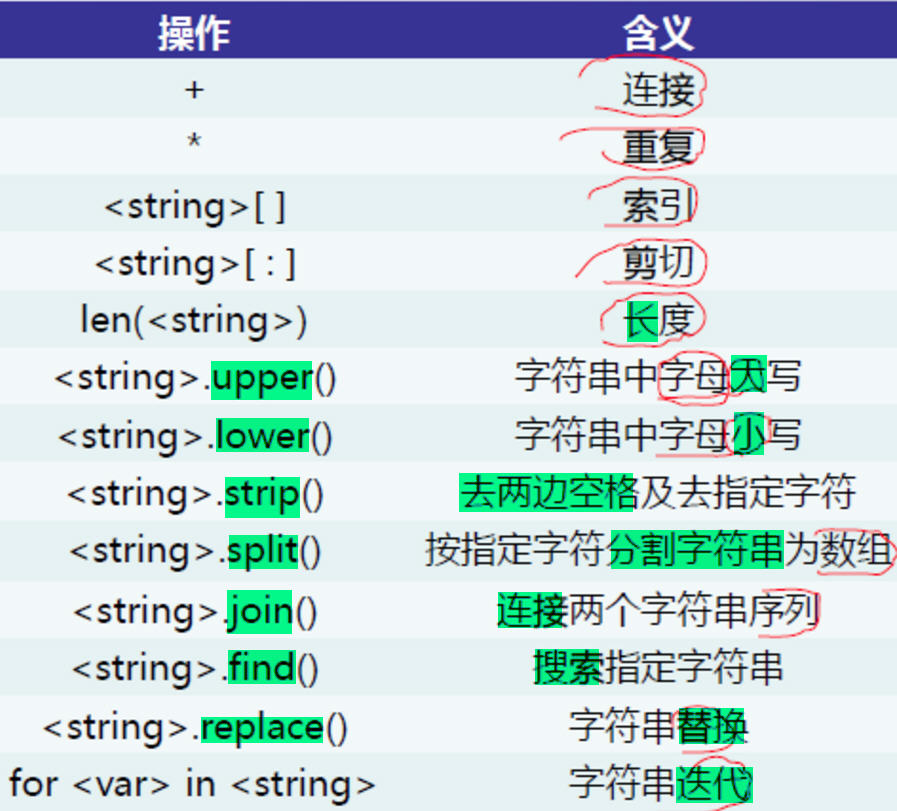
字元串操作
>>> dir(str)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
字元串去空格
通過strip(),lstrip(),rstrip()方法去除字元串的空格
S.strip()去掉字元串的左右空格
S.lstrip()去掉字元串的左邊空格
S.rstrip()去掉字元串的右邊空格
字元串大小寫
通過下麵的upper(),lower()等方法來轉換大小寫
S.upper()#S中的字母大寫
S.lower() #S中的字母小寫
S.capitalize() #首字母大寫
S.istitle() #S是否是首字母大寫的
S.isupper() #S中的字母是否全是大寫
S.islower() #S中的字母是否全是小寫
字元串其他方法
字元串相關的其他方法:count() join()方法等
S.center(width, [fillchar]) #中間對齊
S.count(substr, [start, [end]]) #計算substr在S中出現的次數
S.expandtabs([tabsize]) #把S中的tab字元替換沒空格,每個tab替換為tabsize個空格,預設是8個
S.isalnum() #是否全是字母和數字,並至少有一個字元
S.isalpha() #是否全是字母,並至少有一個字元
S.isspace() #是否全是空白字元,並至少有一個字元
S.join()#S中的join,把列表生成一個字元串對象
S.ljust(width,[fillchar]) #輸出width個字元,S左對齊,不足部分用fillchar填充,預設的為空格。
S.rjust(width,[fillchar]) #右對齊
S.splitlines([keepends]) #把S按照行分割符分為一個list,keepends是一個bool值,如果為真每行後而會保留行分割符。
S.swapcase() #大小寫互換
字元串相加
我們通過操作符號+來進行字元串的相加,不過建議還是用其他的方式來進行字元串的拼接,這樣效率高點。
原因:在迴圈連接字元串的時候,他每次連接一次,就要重新開闢空間,然後把字元串連接起來,再放入新的空間,再一次迴圈,又要開闢新的空間,把字元串連接起來放入新的空間,如此反覆,記憶體操作比較頻繁,每次都要計算記憶體空間,然後開闢記憶體空間,再釋放記憶體空間,效率非常低。
字元串編碼

格式化字元串



