
Ref:https://www.aliyun.com/jiaocheng/1109809.html 摘要: 簡介 undrop-for-innodb 是針對 innodb 的一套數據恢復工具,可以從文件級別恢復諸如:DROP/TRUNCATE table, 刪除表中某些記錄,innodb 文件被刪除 ...
Ref:https://www.aliyun.com/jiaocheng/1109809.html
摘要: 簡介 undrop-for-innodb 是針對 innodb 的一套數據恢復工具,可以從文件級別恢復諸如:DROP/TRUNCATE table, 刪除表中某些記錄,innodb 文件被刪除,文件系統損壞,磁碟 corruption 等幾種情況。
簡介
undrop-for-innodb 是針對 innodb 的一套數據恢復工具,可以從文件級別恢復諸如:DROP/TRUNCATE table, 刪除表中某些記錄,innodb 文件被刪除,文件系統損壞,磁碟 corruption 等幾種情況。本文簡單介紹下使用方法和原理淺析。
準備
git clone https://github.com/twindb/undrop-for-innodb.git
make
需要聯合 MySQL 的安裝路徑編譯工具 sys_parser,
gcc `$basedir/bin/mysql_config --cflags` `$basedir/bin/mysql_config --libs` -o sys_parser sys_parser.c
需要的工具都已經完備:

- 重要的工具:
c_parser && stream_parser && sys_parser - 其中
test.sh && recover_dictionary.sh && fetch_data.sh是測試的腳本,可以看下裡面的邏輯理解工具的用法。 - 三個目錄
- dictionary 裡面是模擬 innodb 系統表結構寫的 CREATE TABLE 語句,innodb 的系統表對用戶不可見,可以在 informatioin_schema 表中找到一些值,但實際上系統表是保存在 ibdata 固定的頁上的。
- sakila 是一些 SQL 語句,用來測試用。
- include 是從 innodb 拿出來的一些用到的頭文件和源文件。
DROP TABLE
表結構恢復
一般情況下表結構是存儲在 frm 文件中,drop table 會刪除 frm 文件,還好我們可以從 innodb 系統表裡讀取一些信息恢復表結構。innodb 系統表有
SYS_COLUMNS | SYS_FIELDS | SYS_INDEXES | SYS_TABLES
關於系統表結構的具體介紹可以參考 系統表 , 這幾個表對於恢復非常重要,下麵以一個恢復表結構的例子來說明。
使用目錄 sakila/actor.sql 中的例子:
CREATE TABLE `actor` (
`actor_id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8; insert into actor(first_name, last_name) values('zhang', 'jian'); insert into actor(first_name, last_name) values('zhan', 'jian'); insert into actor(first_name, last_name) values('zha', 'jian'); insert into actor(first_name, last_name) values('zh', 'jian'); insert into actor(first_name, last_name) values('z', 'jian');
mysql> checksum table actor;
+-----------+------------+
| Table | Checksum |
+-----------+------------+
| per.actor | 2184463059 |
+-----------+------------+ 1 row in set (0.00 sec)
DROP TABLE actor
需要從系統表中恢復,而系統表是保存在 $datadir/ibdata1 文件中的,使用工具 stream_parser 解析文件內容。
$./stream_parser -f /home/zj118228/rds_5616/data/ibdata1
執行完畢後會在當前目錄下生成文件夾 pages-ibdata1 , 目錄下按照每個頁為一個文件,分為索引頁和數據較大的 BLOB 頁,我們訪問系統表的話,是存在索引頁中的。使用另外一個重要的工具 c_parser 來解析頁的內容。
$./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -t dictionary/SYS_TABLES.sql | grep 'sakila/actor' 000000005927 24000001C809C6 SYS_TABLES "sakila/actor" 52 4 1 0 80 "" 38 參數解析:
- 4 表示文件格式是 REDUNDANT,系統表的格式預設值。另外可以取值 5 表示 COMPACT 格式,6 表示 MySQL 5.6 格式。
- D 表示只恢復被刪除的記錄。
- f 後面跟著文件。
- t 後面跟著 CREATE TABLE 語句,需要根據表的格式來解析文件。
得到的結果 ‘SYS_TABLES’ 欄位後面的就是系統表 SYS_TABLE 中對應存的記錄。 同樣的恢復其它三個系統表:
/* --- SYS_INDEXES 'grep 52' 是對應 SYS_TABLE 的 TALE ID --- */
$./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -t dictionary/SYS_INDEXES.sql | grep '52' 000000005927 24000001C807FF SYS_INDEXES 52 57 "PRIMARY" 1 3 38 4294967295 000000005927 24000001C80871 SYS_INDEXES 52 58 "idx\_actor\_last\_name" 1 0 38 4294967295 /* --- SYS_COLUMNS --- */
./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000002.page -t dictionary/SYS_COLUMNS.sql | grep 52 000000005927 24000001C808F2 SYS_COLUMNS 52 0 "actor\_id" 6 1794 2 0 000000005927 24000001C80927 SYS_COLUMNS 52 1 "first\_name" 12 2162959 135 0 000000005927 24000001C8095C SYS_COLUMNS 52 2 "last\_name" 12 2162959 135 0 000000005927 24000001C80991 SYS_COLUMNS 52 3 "last\_update" 3 525575 4 0 /* --- SYS_FIELD 'grep 57\|58' 對應 SYS_INDEXES 的 ID 列 --- */
$./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000004.page -t dictionary/SYS_FIELDS.sql | grep '57\|58' 000000005927 24000001C807CA SYS_FIELDS 57 0 "actor\_id" 000000005927 24000001C8083C SYS_FIELDS 58 0 "last\_name" 我們恢復表結構的數據都在這四張系統表中了,SYS_COLUMNS 後面幾列的表示 MySQL 內部對於數據類型的編號。
接下來是恢復階段
- 使用目錄 dictionary 下的四個文件創建四張表(這裡資料庫名為 recover )。
- 把上面恢復出來的數據分別導入到對應的表中(註意相同的行去重)。
- 使用工具 sys_parser 恢復 CREATE TABLE 語句。
$./sys_parser -h 127.0.0.1 -u root -P 56160 -d recover sakila/actor
CREATE TABLE `actor`(
`actor_id` SMALLINT UNSIGNED NOT NULL,
`first_name` VARCHAR(45) CHARACTER SET 'utf8' COLLATE 'utf8_general_ci' NOT NULL,
`last_name` VARCHAR(45) CHARACTER SET 'utf8' COLLATE 'utf8_general_ci' NOT NULL,
`last_update` TIMESTAMP NOT NULL,
PRIMARY KEY (`actor_id`)
) ENGINE=InnoDB; 對比發現,恢復出來的 CREATE TABLE 語句相比原來創建的語句信息量有點缺少,因為 innodb 系統表裡面存的數據相比 frm 文件是不足的,比如 AUTO_INCREMENT, DECIMAL 類型的精度信息都會缺失,也不會恢復二級索引,外建等。可以看成是表存儲結構的恢復。如果有 frm 文件就可以完完整整的恢復了,這篇文章介紹了恢復方法:Get Create Table From frm
表數據恢復
innodb_file_per_table off
這種情況表中的數據是保存在 ibdata 文件中的,雖然表的數據在資料庫中被刪除了,但是如果沒有被重寫,數據還在保存在文件中的,執行下列步驟來恢復:
- 使用 stream_parser 分析 ibdata 文件,分別得到每個頁的文件。
$./stream_parser -f /home/zj118228/rds_5616/data/ibdata1
- 如表結構分析小節中所示,使用
c_parser分析系統表 SYS_TABLES 和 SYS_INDEXES ,根據表名得到 TABLE ID, 根據 TABLE ID 得到 INDEX ID。(INDEX ID 就是上述例子的第 5 列,值為 57 和 58) - 根據得到的 INDEX ID,到目錄 pages-ibdata1 下去找對應的頁號,這就是對應的索引表數據所在的數據頁。
- 使用 c_parser 讀取第 3 步得到的頁文件,得到數據。
$./c_parser -6f pages-ibdata1/FIL_PAGE_INDEX/0000000000000065.page -t actor.sql
-- Page id: 579, Format: COMPACT, Records list: Valid, Expected records: (5 5)
000000005D95 E5000001960110 actor 201 "zhang" "jian" "2017-11-04 12:30:07" 000000005D96 E6000001970110 actor 202 "zhan" "jian" "2017-11-04 12:30:07" 000000005D98 E80000019A0110 actor 203 "zha" "jian" "2017-11-04 12:30:07" 000000005D99 E90000019B0110 actor 204 "zh" "jian" "2017-11-04 12:30:07" 000000005DA9 F1000002480110 actor 205 "z" "jian" "2017-11-04 12:30:08" 數據看起來沒什麼問題,表結構和數據都有了,導進去即可,看一下 checksum 也相同。
mysql> checksum table actor;
+-----------+------------+
| Table | Checksum |
+-----------+------------+
| per.actor | 2184463059 |
+-----------+------------+
1 row in set (0.00 sec)innodb_file_per_table on
這種情況下表是保存在各自的 ibd 文件中的,當 drop table 之後 ,ibd 文件會被刪除,此時最好能夠設置磁碟整體只讀,避免有其它進程重寫文件塊。整體的恢復步驟和上一個小節(innodb_file_per_table off) 相同,只是無法從 pages-ibdata1 目錄下麵找到對應的 page 號。 假設已經完成了前兩步,拿到了 INDEX ID。
stream_parser 這個工具不但可以讀文件,還可以讀磁碟,會根據 innodb 數據格式把數據頁讀出來。為了恢復 68 號數據頁,我們執行下麵幾個步驟:
-
找到被刪除的 ibd 文件的掛載磁碟 /dev/sda5:
$df Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda2 52327276 47003636 2702200 95% / tmpfs 99225896 9741300 89484596 10% /dev/shm /dev/sda1 258576 55291 190229 23% /boot /dev/sda5 1350345636 1142208356 208137280 85% /home /dev/sdb1 3278622264 2277365092 1001257172 70% /disk1 -
根據 INDEX ID , 磁碟大小執行
stream_parser,-t 表示磁碟的大小。$./stream_parser -f /dev/sda5 -s 1G -t 1142G - 在目錄 pages—sda5 下找到 68 號頁,像上一個小節第 4 步一樣恢複數據即可。
- <劃重點> 測試了三次,有兩次是恢復不出來的,因為文件很可能被其它進程重寫,這取決於文件系統調度還有整體伺服器的負載。
- 如果掛載的磁碟上還有其它 mysqld 的數據目錄,那麼很可能一個 page 文件會很大,監測到其它 ibd 文件的數據,同一個頁號的綜合在一起,這樣辨別出我們需要的數據就比較麻煩。
文件頁臟寫
MySQL 每次從磁碟讀取數據的時候都會進行 checksum 校驗,如果校驗失敗,整個進程就會重啟或者退出,校驗失敗很可能是文件頁被臟寫了。使用恢復工具直接讀取文件很可能可以把未被臟寫的行或者頁讀取出來,損失降到最低。
模擬臟寫
同樣使用目錄 sakila/actor.sql 中的例子,innodb_per_file_table = on:
CREATE TABLE `actor` (
`actor_id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8; insert into actor(first_name, last_name) values('zhang', 'jian'); insert into actor(first_name, last_name) values('zhan', 'jian'); insert into actor(first_name, last_name) values('zha', 'jian'); insert into actor(first_name, last_name) values('zh', 'jian'); insert into actor(first_name, last_name) values('z', 'jian'); 模擬臟寫,打開 actor.ibd 文件, 使用 ‘#’ 覆蓋其中一行數據,
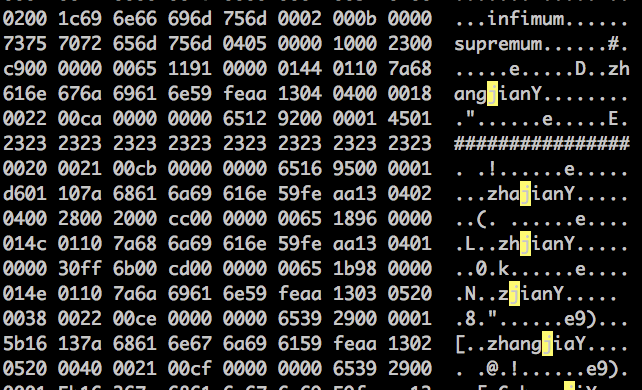
從系統表空間確定 INDEX ID (參考 表結構恢復 小節)
$./stream_parser -f /home/zj118228/rds_5616/data/ibdata1
$./stream_parser -f ~/rds_5616/data/per/actor.ibd
$./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -t dictionary/SYS_TABLES.sql
$./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -t dictionary/SYS_INDEXES.sql
INDEX ID 為 76,讀取數據:
$./c_parser -6f pages-actor.ibd/FIL_PAGE_INDEX/0000000000000076.page -t sakila/actor.sql

看到有一行數據被 # 號覆蓋,然後丟失了一行。
臟寫之後資料庫是起不來的,因為 ibd 文件已經損壞了,但此時我們已經拿到了恢復之後的數據,需要把恢復之後的數據導入到資料庫里。導入之前刪除 actor.ibd 文件,然後啟動資料庫後執行 drop table actor, 然後再重新創建表,導入數據即可。如果不小心把 frm 文件也刪掉了,是沒法 drop table 的,可以在其它資料庫里建一個同名,結構相同的表生成 frm 文件,然後拷貝到被刪除的目錄下,然後再執行 drop table。參考:Troubleshooting
原理淺析
c_parser
恢復工具 c_parser 其實是按照 innodb 存儲數據的格式來分析哪些是我們需要的數據本身,所以頁上的數據可以分為兩類:1. 用戶數據 2. 元數據。而元數據的功能其實並不相同,有些損壞無傷大雅,有些損壞卻可能導致整個頁無法恢復。這裡有幾篇介紹Innodb 行記錄格式1 and Innodb 行記錄格式2 ,上一個小節中行記錄格式是 Compact,來分析一下為什麼會丟了一行數據。
這是完好的數據頁,上面是臟寫是把第 12 行數據全部覆蓋了,根據 Compact 類型的格式,12 行末尾的 04 03 表示下一行變長數據類型(‘zha’ ‘jian’)的長度倒序,被覆蓋之後當然無法解析,於是就丟了一行。那麼為什麼沒有影響後續的行數據呢?第 13 行第 2 列的數據 21 表示下行數據的偏移,幸運的沒有被覆蓋。如果這個位元組被覆蓋,那麼整個格式就亂了,無法解析。
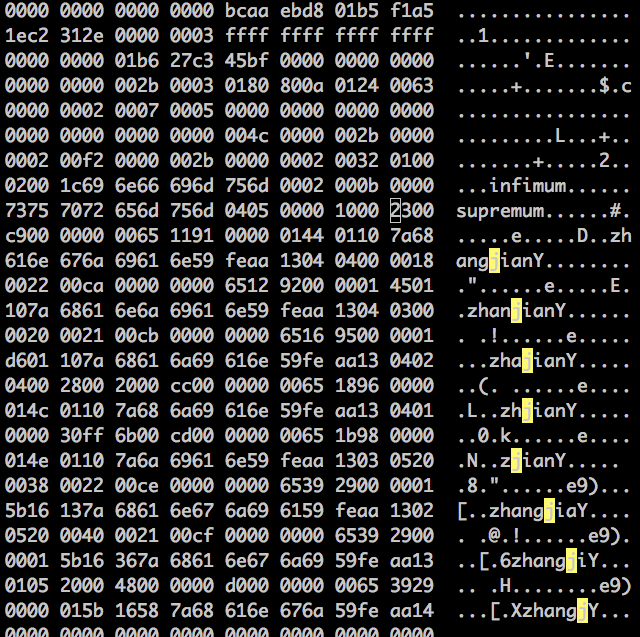
試了其它幾種情況:
- 第六行第五列 004C 表示 page 的號,破壞之後 stream 出來的頁號會變,所以從 Innodb 系統表得到的主鍵索引頁號就不對了。
infimum和supremum破壞之後 stream 無法檢測出頁,所以根本產生不了可恢復的數據。
stream_parser
c_parser 是分析頁面中用戶的行數據,從參數中傳入 CREATE TABLE 語句,根據定義的數據格式逐行解析,得到最終恢復的數據。而 stream_parser 是分析 ibd/ibdata 文件(或者掛載的磁碟),得到每一個數據頁的。根據數據頁的元數據,如果滿足下列條件,就被認為是一個合法的 Innodb Index 數據頁:
- 頁面最開始前四個位元組(checksum)不為 0
- 頁面 5-8 位元組(頁面在 tablespace 中的偏移)不為零,且小於 (ib_size / UNIV_PAGE_SIZE) 最大偏移量,ibd 文件大小除以 Innodb 頁大小。
- 在固定偏移處找到
infimum和supremum
參考 stream_parser.c 中的函數 valid_innodb_page, 關於 Blob page 判定條件略有不同,詳細參考 valid_blob_page,這裡以 Index page 為例。
得到一個合法的頁後就以 UNIV_PAGE_SIZE 為大小寫入到以 index_id 命名的文件中(也就是 c_parser 讀入的頁號判斷標準)。
頁數據格式
這裡引用下登博畫的大圖:
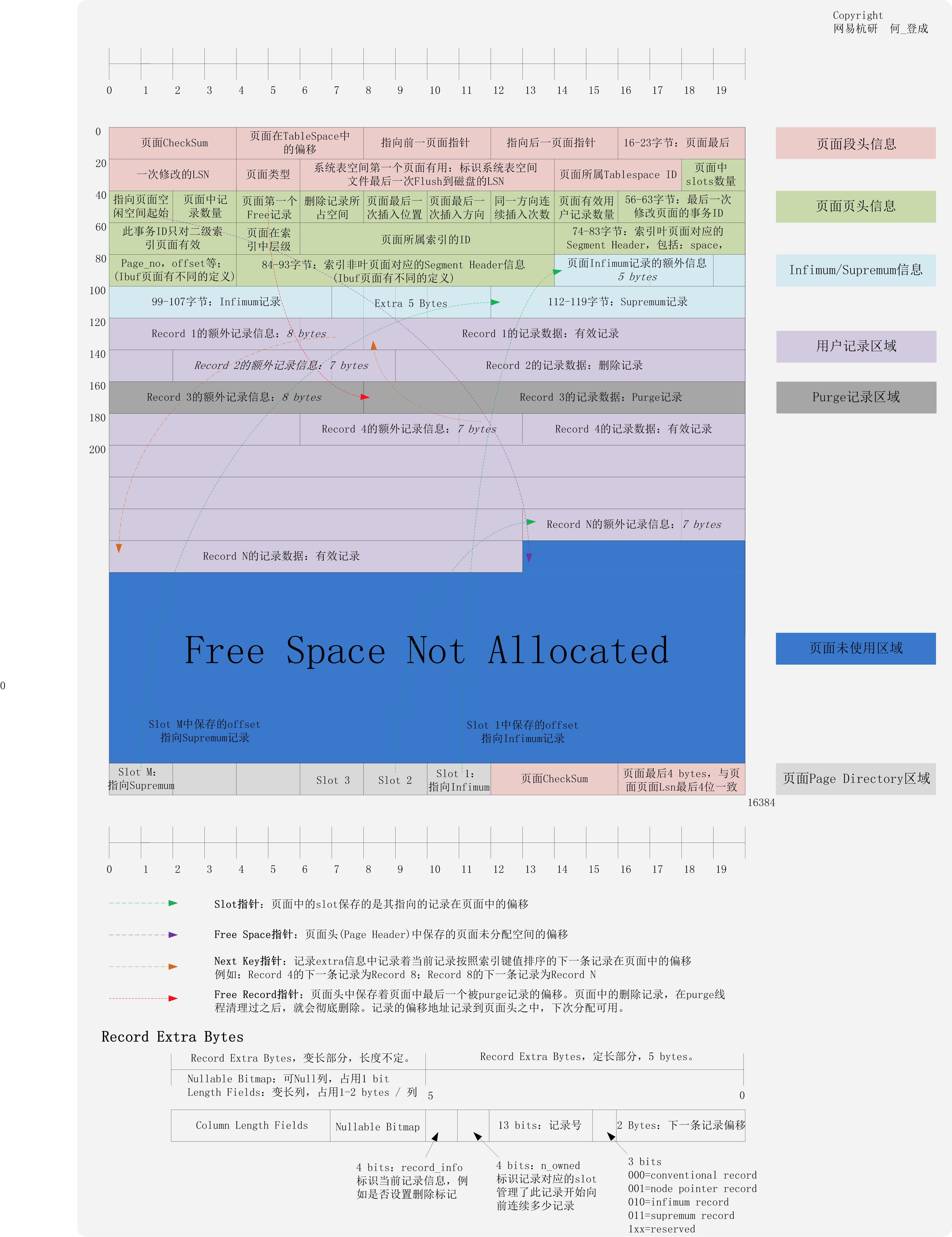
根據圖中數據格式,如果頁面前 8 位元組被重寫為 0 ,infimum 和 supremum 被寫壞,stream_parser 無法檢測出有效頁。如果圖中 Page_no 被寫壞,那麼我們從 Innodb 數據字典中獲得的需要解析的文件頁號恐怕就不對了,也不知道從那裡去恢復。
所以這種恢復方式是寄托在重要頁元數據和行元數據沒有被臟寫的前提下的,上述分析過後,重要的元數據所占比例較小,如果每個位元組被臟寫的概率相同,那麼數據的可恢復性還是比較可觀的。
最後,對於文件系統損壞或者磁碟 corruption,最重要的把數據拷貝出來,而不是去恢覆文件系統或者磁碟,因為上述工具的恢復是基於數據的,參考這篇文章,第一時間使用 dd 命令製作磁碟鏡像,再走上述的恢復流程即可。
原文地址: https://yq.aliyun.com/articles/281230?utm_content=m_37044


