
一、概述 記憶體管理涵蓋領域: 記憶體中的物理記憶體頁管理; 分配大塊記憶體的伙伴系統; 分配較小塊記憶體的slab、slub和slob分配器; 分配連續記憶體塊的vmalloc機制; 進程的地址空間。 Linux內核一般將處理器的虛擬地址分為兩個部分,以IA-32為例,地址空間在用戶進程和內核之間的劃分比例為 ...
一、概述
記憶體管理涵蓋領域:
- 記憶體中的物理記憶體頁管理;
- 分配大塊記憶體的伙伴系統;
- 分配較小塊記憶體的slab、slub和slob分配器;
- 分配連續記憶體塊的vmalloc機制;
- 進程的地址空間。
Linux內核一般將處理器的虛擬地址分為兩個部分,以IA-32為例,地址空間在用戶進程和內核之間的劃分比例為3:1。4GB的虛擬地址空間,3GB用於用戶空間,1GB用於內核。
IA-32系統中,假設物理記憶體4GB,則所有物理記憶體無法直接映射到內核態(內核的地址空間小於1GB),對於用戶空間的記憶體,無法進行直接映射。為了便於管理,定義內核空間896MB記憶體用於DMA和直接映射到物理記憶體,剩餘的部分被稱為高端記憶體,內核藉助內核空間剩餘的128MB空間實現對所有物理記憶體(896MB-4GB)的管理。
如果採用PAE(page address extension)技術,在IA-32中可以管理64GB記憶體,但每次只能定址一個4GB的記憶體段。(目前記憶體超過4GB的IA-32系統很少,主要使AMD64體繫結構替代,目前64位無需高端記憶體模式)
有兩種類型電腦,對應著兩種方法管理記憶體:
- UMA(uniform memory access,一致記憶體訪問)電腦將可用記憶體以連續方式組織起來(可能有小的缺口)。SMP系統中的每個處理器訪問各個記憶體區都是同樣快。
- NUMA(non-uniform memory access,非一致記憶體訪問)電腦總是多處理器電腦。系統的各個CPU都有本地記憶體,可支持特別快速的訪問。各個處理器之間通過匯流排連接起來,以支持對其他CPU的本地記憶體的訪問,速度比訪問本地記憶體慢。
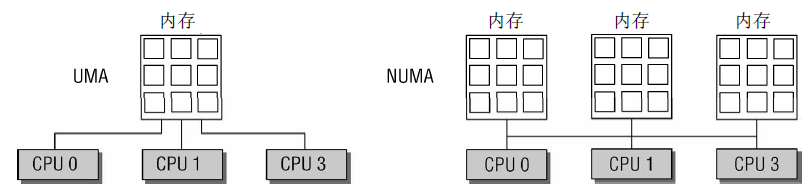
圖1 UMA和NUMA系統
圖1描述了UMA核NUMA電腦的區別。兩種類型電腦的混合也是存在的,比如在UMA系統中,記憶體不是連續的,有比較大的洞,這裡應用NUMA體繫結構的原理通常有所幫助,可以使內核的記憶體訪問更簡單。
內核會區分3 種配置選項: FLATMEM(平坦記憶體模型)、DISCONTIGMEM(不連續記憶體模型)和SPARSEMEM(稀疏記憶體模型)。SPARSEMEM和DISCONTIGMEM實際上作用相同。一般認為SPARSEMEM更多是試驗性的,不那麼穩定,但有一些性能優化。DISCONTIGMEM相關代碼更穩定一些,但不具備記憶體熱插拔之類的新特性。多數配置中都使用該記憶體組織類型為FLATMEM(內核的預設值)。真正的NUMA需要設置CONFIG_NUMA,對於UMA系統,則不用不考慮(不意味著NUMA相關的數據結構可以完全忽略。由於UMA系統可以在地址空間包含比較大的洞時選擇配置選項CONFIG_DISCONTIGMEM,這種情況下在不採用NUMA技術的系統上也會有多個記憶體結點)。圖2綜述了記憶體佈局有關的各種可能配置選項。

圖2 UMA和NUMA電腦上可能的記憶體配置(平攤、稀疏和不連續模型)
*對於分配階(alloction order),表示記憶體區中頁的數目取以2為底的對數。
二、(N)UMA模型中的記憶體組織
內核對一致和非一致記憶體訪問系統使用相同的數據結構,在UMA系統上,只使用一個NUMA結點來管理整個系統記憶體,記憶體管理的其他部分認為是在處理一個偽NUMA系統。
1、概述
圖3是對於NUMA系統記憶體劃分的示例。
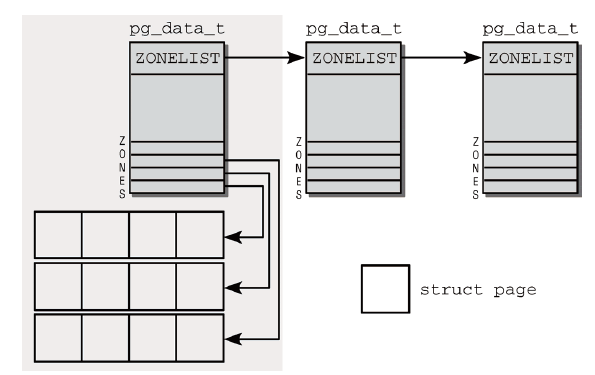
圖3 NUMA系統中的記憶體劃分
將記憶體劃分為結點。每個結點關聯到系統中的一個處理器,在內核中表示為pg_data_t的實例。各個節點又劃分為記憶體域(從低到高為DMA記憶體域,普通記憶體域和超出內核段物理記憶體的高端記憶體域)。
內核使用常量枚舉系統中的所有記憶體域:
1 enum zone_type { 2 #ifdef CONFIG_ZONE_DMA 3 ZONE_DMA, //標記適合DMA的記憶體域,長度依賴於處理器類型 4 #endif 5 #ifdef CONFIG_ZONE_DMA32 6 ZONE_DMA32, //標記了使用32位地址字可定址、適合DMA的記憶體域。 7 #endif 8 ZONE_NORMAL, //標記了可直接映射到內核段的普通記憶體域 9 #ifdef CONFIG_HIGHMEM 10 ZONE_HIGHMEM, 11 #endif 12 ZONE_MOVABLE, 13 MAX_NR_ZONES 14 };
2、數據結構
pg_data_t是用於表示結點的基本元素,定義如下:


1 typedef struct pglist_data { 2 struct zone node_zones[MAX_NR_ZONES]; //包含了結點中各記憶體域的數據結構 3 struct zonelist node_zonelists[MAX_ZONELISTS]; //指定了備用結點及其記憶體域的列表 4 int nr_zones; //結點中不同記憶體域的數目 5 struct page *node_mem_map; //指向page實例數組的指針,用於描述結點的所有物理記憶體頁 6 struct bootmem_data *bdata; //指向自舉記憶體分配器數據結構的實例 7 unsigned long node_start_pfn; //該NUMA結點第一個頁幀的邏輯編號 8 unsigned long node_present_pages; /* 物理記憶體頁的總數 */ 9 unsigned long node_spanned_pages; /* 物理記憶體頁的總長度,包含洞在內 */ 10 int node_id; //全局結點ID,系統中的NUMA結點都從0開始編號 11 struct pglist_data *pgdat_next; //連接到下一個記憶體結點 12 wait_queue_head_t kswapd_wait; //交換守護進程(swap daemon)的等待隊列 13 struct task_struct *kswapd; //指向負責該結點的交換守護進程的task_struct 14 int kswapd_max_order; //用來定義需要釋放的區域的長度 15 } pg_data_t;struct pglist_data
如果系統中結點多於一個,內核會維護一個點陣圖,用以提供各個結點的狀態信息。狀態是用位掩碼指定的,可使用下列值:
1 enum node_states { 2 N_POSSIBLE, /* 結點在某個時候可能變為聯機,用於記憶體的熱插拔 */ 3 N_ONLINE, /* 結點是聯機的 ,用於記憶體的熱插拔*/ 4 N_NORMAL_MEMORY, /* 結點有普通記憶體域 */ 5 #ifdef CONFIG_HIGHMEM 6 N_HIGH_MEMORY, /* 結點有普通或高端記憶體域 */ 7 #else 8 N_HIGH_MEMORY = N_NORMAL_MEMORY, 9 #endif 10 N_CPU, /* 結點有一個或多個CPU ,用於CPU的熱插拔*/ 11 NR_NODE_STATES 12 };enum node_states
如果內核編譯為只支持單個結點(即使用平坦記憶體模型),則沒有結點點陣圖。
內核使用zone結構來描述記憶體域。
1 struct zone { 2 /*該結構是由ZONE_PADDING分隔為幾個部分,內核使用ZONE_PADDING巨集生成“填充”欄位添加到結構中,以確保每個自旋鎖都處於自身的緩存行中。還使用了編譯器關鍵字__cacheline_maxaligned_in_smp,用以實現最優的高速緩存對齊方式。該結構的最後兩個部分也通過填充欄位彼此分隔開來。兩者都不包含鎖,主要目的是將數據保持在一個緩存行中,便於快速訪問,從而無需從記憶體載入數據*/ 3 4 /*通常由頁分配器訪問的欄位 */ 5 unsigned long pages_min, pages_low, pages_high; //頁換出時使用的“水印”(記憶體不足內核可以將頁寫入硬碟) 6 unsigned long lowmem_reserve[MAX_NR_ZONES]; //分別為各種記憶體域指定了若幹頁,用於一些無論如何都不能失敗的關鍵性記憶體分配 7 struct per_cpu_pageset pageset[NR_CPUS]; //用於實現每個CPU的熱/冷頁幀列表 8 /* 9 * 不同長度的空閑區域 10 */ 11 spinlock_t lock; 12 struct free_area free_area[MAX_ORDER]; //用於實現伙伴系統 13 ZONE_PADDING(_pad1_) 14 /*第二部分涉及的結構成員,用來根據活動情況對記憶體域中使用的頁進行編目。*/ 15 /* 通常由頁面收回掃描程式訪問的欄位 */ 16 spinlock_t lru_lock; 17 struct list_head active_list; //活動頁的集合 18 struct list_head inactive_list; //不活動頁的集合 19 unsigned long nr_scan_active; //在回收記憶體時需要掃描的活動頁的數目 20 unsigned long nr_scan_inactive; //在回收記憶體時需要掃描的不活動頁的數目 21 unsigned long pages_scanned; /* 上一次回收以來掃描過的頁 */ 22 unsigned long flags; /* 記憶體域標誌*/ 23 /* 記憶體域統計量 */ 24 atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS]; //維護了大量有關該記憶體域的統計信息 25 int prev_priority; //存儲了上一次掃描操作掃描該記憶體域的優先順序 26 ZONE_PADDING(_pad2_) 27 /* 很少使用或大多數情況下只讀的欄位 */ 28 wait_queue_head_t * wait_table; 29 unsigned long wait_table_hash_nr_entries; 30 unsigned long wait_table_bits; // 以上三個變數實現了一個等待隊列,可供等待某一頁變為可用的進程使用 31 /* 支持不連續記憶體模型的欄位。 */ 32 struct pglist_data *zone_pgdat; //建立記憶體域和父結點之間的關聯 33 unsigned long zone_start_pfn; //記憶體域第一個頁幀的索引 34 unsigned long spanned_pages; /* 總長度,包含空洞 */ 35 unsigned long present_pages; /* 記憶體數量(除去空洞) */ 36 /* 37 * 很少使用的欄位: 38 */ 39 char *name; 40 } ____cacheline_maxaligned_in_smp;struct zone
記憶體域水印值:需要為關鍵性分配保留的記憶體空間的最小值;該值該值隨可用記憶體的大小而非線性增長,保存在全局變數min_free_kbytes中。
數據結構中水印值的填充由init_per_zone_pages_min處理,該函數由內核在啟動期間調用,無需顯式調用。圖4為主記憶體大小與可用於關鍵性分配的記憶體空間最小值之間的關係示意圖。

圖4 主記憶體大小與可用於關鍵性分配的記憶體空間最小值之間的關係
冷熱頁:熱頁表示頁已載入到CPU告訴緩存,冷頁則沒有。struct zone的pageset成員用於實現冷熱分配器(hot-n-cold allocator)。在多處理器系統上每個CPU都有一個或多個高速緩存,各個CPU的管理必須是獨立的。
儘管記憶體域可能屬於一個特定的NUMA結點,因而關聯到某個特定的CPU,但其他CPU的高速緩存仍然可以包含該記憶體域中的頁。所以,每個處理器都可以訪問系統中所有的頁,儘管速度不同(特定於記憶體域的數據結構不僅要考慮到所屬NUMA結點相關的CPU,還必須照顧到系統中其他的CPU)。
相關數據結構及定義如下:
1 struct zone { 2 ... 3 struct per_cpu_pageset pageset[NR_CPUS]; // NR_CPUS是是內核支持的CPU的最大數目 4 ... 5 };struct zone
1 struct per_cpu_pages { 2 int count; /* 列表中頁數 */ 3 int high; /* 頁數上限水印,在需要的情況下清空列表 */ 4 int batch; /* 添加/刪除多頁塊的時候,塊的大小 */ 5 struct list_head list; /* 頁的鏈表 */ 6 };struct per_cpu_pages
頁幀:頁幀代表系統記憶體的最小單位,對記憶體中的每個頁都會創建struct page的一個實例(內核儘力保持這個結構儘可能小)。
頁的廣泛使用,增加了保持結構長度的難度:記憶體管理的許多部分都使用頁,用於各種不同的用途。對此,內核的一個部分可能完全依賴於struct page提供的特定信息,而該信息對內核的另一部分可能完全無用,該部分依賴於struct page提供的其他信息,為了使struct page結構儘可能小,C語言的聯合(union)對某些欄位進行了雙重解釋。
page的定義如下:
1 struct page { 2 unsigned long flags; /* 原子標誌,有些情況下會非同步更新 */ 3 atomic_t _count; /* 使用計數,見下文。 */ 4 union { 5 atomic_t _mapcount; /* 記憶體管理子系統中映射的頁表項計數, 6 * 用於表示頁是否已經映射,還用於限制逆向映射搜索。 7 */ 8 unsigned int inuse; /* 用於SLUB分配器:對象的數目 */ 9 }; 10 union { 11 struct { 12 unsigned long private; /* 由映射私有,不透明數據: 13 *如果設置了PagePrivate,通常用於buffer_heads; 14 *如果設置了PageSwapCache,則用於swp_entry_t; 15 * 如果設置了PG_buddy,則用於表示伙伴系統中的階。 16 */ 17 struct address_space *mapping; /* 如果最低位為0,則指向inode 18 * address_space,或為NULL。 19 * 如果頁映射為匿名記憶體,最低位置位, 20 * 而且該指針指向anon_vma對象: 21 * 參見下文的PAGE_MAPPING_ANON。 22 */ 23 }; 24 ... 25 struct kmem_cache *slab; /* 用於SLUB分配器:指向slab的指針 */ 26 struct page *first_page; /* 用於複合頁的尾頁,指向首頁 */ 27 }; 28 union { 29 pgoff_t index; /* 在映射內的偏移量 */ 30 void *freelist; /* SLUB: freelist req. slab lock */ 31 }; 32 struct list_head lru; /* 換出頁列表,例如由zone->lru_lock保護的active_list! 33 */ 34 #if defined(WANT_PAGE_VIRTUAL) 35 void *virtual; /* 內核虛擬地址(如果沒有映射則為NULL,即高端記憶體) */ 36 #endif /* WANT_PAGE_VIRTUAL */ 37 }; 38struct page
體繫結構無關的頁標誌頁的不同屬性通過一系列頁標誌描述,存儲為struct page的flags成員中的各個比特位。這些標誌獨立於使用的體繫結構,因而無法提供特定於CPU或電腦的信息(該信息保存在頁表中)。各個標誌是由page-flags.h中的巨集定義的,此外還生成了一些巨集,用於標誌的設置、刪除、查詢。這樣做時,內核遵守了一種通用的命名方案(巨集的實現是原子操作)。
三、頁表
層次化的頁表用於支持對大地址空間的快速、高效的管理。
頁表用於建立用戶進程的虛擬地址空間和系統物理記憶體(記憶體、頁幀)之間的關聯。頁表用於向每個進程提供一致的虛擬地址空間。應用程式看到的地址空間是一個連續的記憶體區。該表也將虛擬記憶體頁映射到物理記憶體,因而支持共用記憶體的實現(幾個進程同時共用的記憶體),還可以在不額外增加物理記憶體的情況下,將頁換出到塊設備來增加有效的可用記憶體空間。
頁表管理分為兩個部分,第一部分依賴於體繫結構(不同的CPU的實現有一些較大差別),第二部分是體繫結構無關的。
1、數據結構
在C語言中,通常用void *定義可能指向記憶體中任何位元組位置的指針。在Linux支持的所有體繫結構中,sizeof(void *) == sizeof(unsigned long),所以它們之間進行強制轉換不會損失信息。記憶體管理多使用unsigned long類型變數,它更易於處理和操作(技術上兩者都有效)。
(1)記憶體地址的分解
根據四級頁表結構的需要,虛擬記憶體地址分為5部分(4個表項用於選擇頁,1個索引表示頁內位置)。各個體繫結構不僅地址字長度不同,而且地址字拆分的方式也不同。內核定義了巨集將地址分解為各個分量。
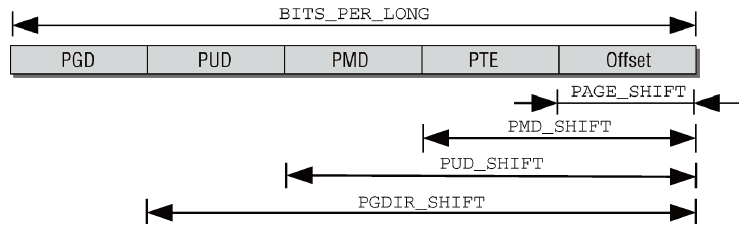
圖5 分解虛擬記憶體地址
圖5為用比特位移定義地址字各分量位置的方法。每個指針末端的幾個比特位,用於指定所選頁幀內部的位置。比特位的具體數目由PAGE_SHIFT指定。PMD_SHIFT指定了頁內偏移量和最後一級頁表項所需比特位的總數。PUD_SHIFT 由PMD_SHIFT加上中間層頁表索引所需的比特位長度組成。PGDIR_SHIFT由PUD_SHIFT加上上層頁表索引所需的比特位長度組成。
在各級頁目錄/頁表中所能存儲的指針數目通過巨集定義確定。PTRS_PER_PGD指定了全局頁目錄中項的數目,PTRS_PER_PMD對應於中間頁目錄,PTRS_PER_PUD對應於上層頁目錄中項的數目,PTRS_PER_PTE則是頁表中項的數目。兩級頁表的體繫結構會將PTRS_PER_PMD和PTRS_PER_PUD定義為1。
(2)頁表的格式
內核提供了4個數據結構來標識
- pgd_t用於全局頁目錄項。
- pud_t用於上層頁目錄項。
- pmd_t用於中間頁目錄項。
- pte_t用於直接頁表項。
此外,根據不同的體繫結構,內核通過巨集定義或內聯函數定義了一些用於分析頁表項的標準函數。
儘管使用了C結構來表示頁表項,但大多數頁表項都只有一個成員,通常是unsigned long類型,AMD64體繫結構的頁表項如下:
1 typedef struct { unsigned long pte; } pte_t; 2 typedef struct { unsigned long pmd; } pmd_t; 3 typedef struct { unsigned long pud; } pud_t; 4 typedef struct { unsigned long pgd; } pgd_t;
使用struct而不是基本類型,以確保頁表項的內容只能由相關的輔助函數處理,而決不能直接訪問。
虛擬地址分為幾個部分,用作各個頁表的索引。根據使用的體繫結構字長不同,各個單獨的部分長度小於32或64個比特位。內核(以及處理器)使用32或64位類型來表示頁表項(不管頁表的級數)。這意味著並非表項的所有比特位都存儲了有用的數據,即下一級表的基地址。多餘的比特位用於保存額外的信息。
(3)特定於PTE的信息
最後一級頁表中的項不僅包含了指向頁的記憶體位置的指針,還在上述的多餘比特位包含了與頁有關的附加信息(有關頁訪問控制的一些信息)。
_PAGE_PRESENT指定了虛擬記憶體頁是否存在於記憶體中;CPU每次訪問頁時,會自動設置_PAGE_ACCESSED(活躍程度);_PAGE_DIRTY表示該頁內容是否已修改;_PAGE_FILE的數值與_PAGE_DIRTY相同,用於頁不在記憶體中的時候;_PAGE_USER指定是否允許用戶空間代碼訪問該頁;_PAGE_READ、_PAGE_WRITE和_PAGE_EXECUTE指定了普通的用戶進程是否允許讀取、寫入、執行該頁中的機器代碼;IA-32和AMD64提供了_PAGE_BIT_NX,作為保護位用於將頁標記為不可執行的功能。
內核還定義了各種函數,用於查詢和設置記憶體頁與體繫結構相關的狀態。(不詳述)
2、頁表項的創建和操作

圖6 用於創建新頁表項的函數
所有體繫結構都實現了圖6中的函數,以便於記憶體管理代碼創建和銷毀頁表。
四、初始化記憶體管理
許多CPU需要顯式設置適用於Linux內核的記憶體模型(IA-32需要切換到保護模式),內核在記憶體管理完全初始化之前就需要使用記憶體,在系統啟動過程期間,使用一個額外的簡化形式的記憶體管理模塊,然後丟棄,確認系統中記憶體的總數量,及其在各個結點和記憶體域之間的分配情況。
1、建立數據結構
對相關數據結構的初始化是從全局啟動start_kernel開始的,由於記憶體管理在內核中非常重要,特定於體繫結構的設置步驟中檢測記憶體並確定系統中記憶體的分佈情況後,會立即執行記憶體的初始化。此時,已經對各種系統記憶體模式生成了一個pgdata_t實例,用於保存諸如結點中記憶體數量以及記憶體在各個記憶體域之間分配情況的信息。
(1)先決條件
內核在mm/page_alloc.c中定義了一個pg_data_t實例(稱作contig_page_data)管理所有的系統記憶體,以保證記憶體管理代碼的可移植性。
體繫結構相關的初始化代碼將numnodes變數設置為系統中結點的數目。在UMA系統上因為只有一個(形式上的)結點,因此該數量是1。
(2)系統啟動
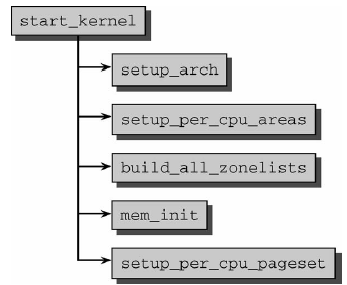
圖7 從記憶體管理看內核初始化
圖7是start_kernel代碼流程圖,首先是設置函數setup_arch(其中會初始化自舉分配器);然後setup_per_cpu_areas定義靜態per_cpu變數(非SMP系統上為空操作);接著build_all_zonelists建立結點和記憶體域的數據結構;之後mem_init停用bootmem分配器並遷移到實際的記憶體管理函數;最後setup_per_cpu_pageset為pageset數組的第一個數組元素分配記憶體。
(3)結點和記憶體域初始化
內核定義了記憶體的一個層次結構,首先試圖分配“廉價的”記憶體。如果失敗,則根據訪問速度和容量,逐漸嘗試分配“更昂貴的”記憶體。高端記憶體是最廉價的,普通記憶體域的情況其次,DMA記憶體域最昂貴。內核還針對當前記憶體結點的備選結點,定義了一個等級次序(build_zonelists作用)。用於當前結點所有記憶體域的記憶體都用盡時,確定備選結點。
build_all_zonelists將所有工作都委托給__build_all_zonelists,後者對系統中的各個NUMA結點分別調用build_zonelists,對所有記憶體創建記憶體域列表。UMA系統中,build_zonelists在當前處理的結點和系統中其他結點的記憶體域之間建立一種等級次序(這種次序在期望的結點記憶體域中沒有空閑記憶體時很重要)。
圖8以某個系統的結點2為例,描述了一個備用列表在多次迴圈中不斷填充的過程。(numnodes=4)

圖8 連續填充備用列表
第一步之後,列表中的分配目標是高端記憶體,接下來是第二個結點的普通和DMA記憶體域。第二步檢查大於當前結點編號的一個結點,最後檢查編號小於當前結點的結點生成備用列表項。備用列表中項的數目一般無法準確知道,因為系統中不同結點的記憶體域配置可能並不相同。因此列表的最後一項賦值為空指針,顯式標記列表結束。
對總數N個結點中的結點m來說,內核生成備用列表時,選擇備用結點的順序總是:m、m+1、m+2、…、N1、0、1、…、m1。
圖9為4個結點系統中為第三個結點建立的備用列表。

圖9 完成的備用列表
2、特定於體繫結構的設置
(1)內核在記憶體中的佈局
IA-32體繫結構中,對於其物理記憶體,前4KB(第一個頁幀)留給BIOS用,接下來640K空白,該區域後用於映射各種ROM(通常是系統BIOS和顯卡ROM)。IA-32內核使用0x100000作為起始地址,對應於記憶體中第二兆位元組的開始處。
內核占據的記憶體分為幾個段,其邊界保存在變數中:
- _text和_etext是代碼段的起始和結束地址,包含了編譯後的內核代碼;
- 數據段位於_etext和_edata之間,保存了大部分內核變數;
- 初始化數據在內核啟動過程結束後不再需要(例如,包含初始化為0的所有靜態全局變數的BSS段)保存在最後一段,從_edata到_end。
編譯器在編譯時,只有在目標文件鏈接完成後,才能知道內核大小確切的數值,接下來則打包為二進位文件。該操作是由arch/arch/vmlinux.ld.S控制的(對IA-32來說,該文件是arch/x86/vmlinux_32.ld.S),其中也劃定了內核的記憶體佈局。
每次編譯內核時,都生成一個文件System.map並保存在源代碼目錄下(cat System.map命令查看)。除了所有其他(全局)變數、內核定義的函數和常式的地址,該文件還包括_text,_etext,_edata,_end等常數的值。
用戶和內核地址空間之間採用標準的3 : 1劃分,內核段的起始地址0xC0000000,該地址是虛擬地址,因為物理記憶體映射到虛擬地址空間的時候,採用了從該地址開始的線性映射方式。減去0xC0000000,則可獲得對應的物理地址。
(2)初始化步驟
內核載入記憶體、初始化的彙編部分執行完畢後,內核需要執行的記憶體管理相關操作流程如圖10所示。
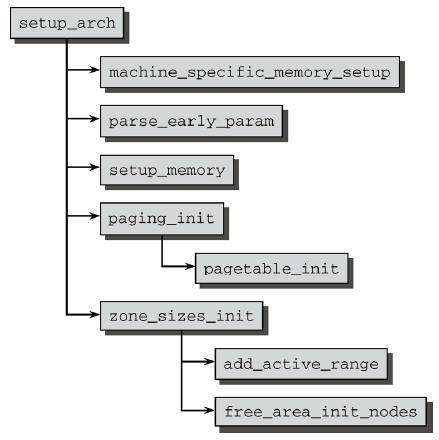
圖10 IA-32系統上記憶體初始化的代碼流程圖
- 首先調用machine_specific_memory_setup,創建一個列表,包括系統占據的記憶體區和空閑記憶體區。
- 內核接下來用parse_cmdline_early分析命令行,主要關註類似mem=XXX[KkmM]、highmem=XXX[kKmM]或memmap=XXX[KkmM]" "@XXX[KkmM]之類的參數。
- 下一個主要步驟在setup_memory中執行,該函數有兩個版本。一個用於連續記憶體系統,另一個用於不連續記憶體系統,二者的效果相同:確定(每個結點)可用的物理記憶體頁的數目;初始化bootmem分配器;接下來分配各種記憶體區。
- paging_init初始化內核頁表並啟用記憶體分頁。
- 最後調用zone_sizes_init會初始化系統中所有結點的pgdata_t實例。
- AMD64電腦上記憶體有關的初始化次序非常類似。
(3)分頁機制初始化
IA-32系統上,內核通常將總4GB可用虛擬地址空間按3:1的劃分,劃分原因有兩個:
- 在用戶應用程式的執行切換到核心態時,內核必須裝載在一個可靠的環境中。因此有必要將地址空間的一部分分配給內核專用。
- 物理記憶體頁則映射到內核地址空間的起始處,以便內核直接訪問,而無需複雜的頁表操作(安全問題:不能讓所有物理記憶體頁都映射到用戶空間進程的地址空間中)。
雖然用於用戶層進程的虛擬地址部分隨進程切換而改變,但是內核部分總是相同的。
如圖11所示,內核地址空間自身又分為各個段,標明瞭虛擬地址空間的各個區域的用途(與物理記憶體的分配無關)。

圖11 IA-32系統上內核地址空間劃分
地址的第一段與系統的所有物理記憶體頁映射到內核虛擬地址空間中,是一個簡單的線性平移。直接映射區域從0xC0000000到high_memory(最高896MB)地址,如果物理記憶體超過896MB,則內核無法直接映射全部物理記憶體。剩餘的128MB(超過896MB到1GB的部分)用作以下三個用途:
- 虛擬記憶體中連續、但物理記憶體中不連續的記憶體區,可以在vmalloc區域分配。該機制通常用於用戶過程,內核自身會試圖儘力避免非連續的物理地址。內核通常會成功,因為大部分大的記憶體塊都在啟動時分配給內核,那時記憶體的碎片尚不嚴重。如果在已經運行了很長時間的系統上,在內核需要物理記憶體時,就可能出現可用空間不連續的情況。此類情況,主要出現在動態載入模塊時;
- 持久映射用於將高端記憶體域中的非持久頁映射到內核中;
- 固定映射是與物理地址空間中的固定頁關聯的虛擬地址空間項,但具體關聯的頁幀可以自由選擇。它與通過固定公式與物理記憶體關聯的直接映射頁相反,虛擬固定映射地址與物理記憶體位置之間的關聯可以自行定義,定義後不能改變。優點在於,在編譯時對此類地址的處理類似於常數,內核一啟動即為其分配了物理地址(地址解引用比普通指針快)。
(__VMALLOC_RESERVE設置了vmalloc區域的長度, MAXMEM表示內核可以直接定址的物理記憶體的最大可能數量,內核中,將記憶體劃分為各個區域是通過圖11所示的各個常數控制的(常數值可能不同),直接映射的邊界由high_memory指定)
vmalloc區域的起始地址,取決於在直接映射物理記憶體時,使用了多少虛擬地址空間記憶體(high_memory)。
vmalloc區域在何處結束取決於是否啟用了高端記憶體支持。如果沒有啟用,那麼就不需要持久映射區域,因為整個物理記憶體都可以直接映射。
IA-32系統中,將虛擬地址空間按3:1比例劃分不是唯一選項,通過修改__PAGE_OFFSET實現。按3∶1之外的比例劃分地址空間,在特定的應用場景下可能是有意義的。比如對主要在內核中運行代碼的電腦,例如網路路由器。
paging_init負責建立只能用於內核的頁表,用戶空間無法訪問。代碼流程圖如圖12所示。
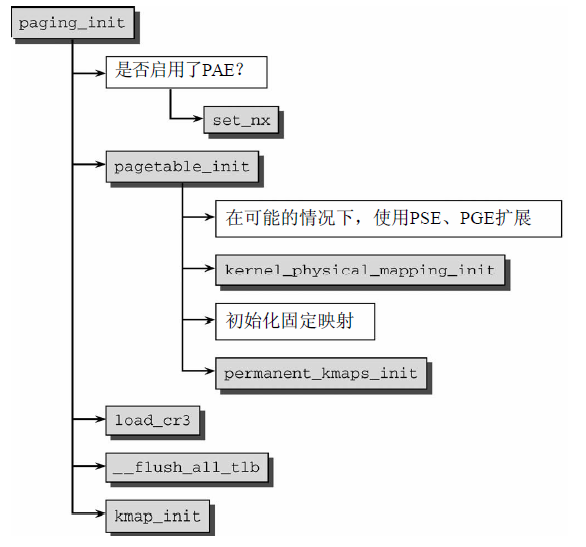
圖12 paging_init代碼流程圖
- 首先劃分虛擬地址空間;
- 然後由pagetable_init以swapper_pg_dir(全局頁目錄指針)為基礎初始化系統的頁表。接下來啟用在所有現代IA-32系統上可用的兩個擴展(只有一些非常古老的Pentium實現不支持這些)。
- 對超大記憶體頁的支持。這些特別標記的頁,其長度為4 MiB,而不是普通的4 KiB。該選項用於不會換出的內核頁。增加頁大小,意味著需要的頁表項變少,這對地址轉換後備緩衝器(TLB)的影響是正面的,可以減少其中來自內核的緩存項。
- 如有可能,內核頁會設置另一個屬性(__PAGE_GLOBAL),這也是__PAGE_KERNEL和__PAGE_KERNEL_EXEC變數中__PAGE_GLOBAL比特位已經置位的原因。這些變數指定內核自身分配頁幀時的標誌集,因此這些設置會自動地應用到內核頁。
- 接著藉助於kernel_physical_mapping_init,將物理記憶體頁(或前896 MiB)映射到虛擬地址空間中從PAGE_OFFSET開始的位置。內核接下來掃描各個頁目錄的所有相關項,將指針設置為正確的值。
- 隨後建立固定映射項和持久內核映射對應的記憶體區。同樣是用適當的值填充頁表。
- 最後將cr3寄存器設置為指向全局頁目錄(swapper_pg_dir)的指針,激活新的頁表,使用__flush_all_tlb刷出於TLB緩存項仍然包含了啟動時分配的一些記憶體地址數據,將kmap_init初始化全局變數kmap_pte(用於從高端記憶體域將頁映射到內核地址空間)。
對於冷熱(per-CPU)緩存,zone_pcp_init負責初始化該緩存。
1 static __devinit void zone_pcp_init(struct zone *zone) 2 { 3 int cpu; 4 unsigned long batch = zone_batchsize(zone); 5 for (cpu = 0; cpu < NR_CPUS; cpu++) { 6 setup_pageset(zone_pcp(zone,cpu), batch); 7 } 8 if (zone->present_pages) 9 printk(KERN_DEBUG " %s zone: %lu pages, LIFO batch:%lu\n", 10 zone->name, zone->present_pages, batch); 11 }__devinit void zone_pcp_init
在用zone_batchsize算出批量大小(用於計算最小和最大填充水平的基礎)後,代碼將遍歷系統中的所有CPU,同時調用setup_pageset填充每個per_cpu_pageset實例的常量。在調用該函數時,使用了zone_pcp巨集來選擇與當前CPU相關的記憶體域的pageset實例。
對於冷熱頁的水印計算,內核首先會計算出batch,batch = zone->present_pages / 1024,大約相當於記憶體域中的頁數的0.25‰。對熱頁來說,下限為0,上限為6*batch,緩存中頁的平均數量大約是4*batch,因為內核不會讓緩存水平降到太低。batch*4相當於記憶體域中頁數的千分之一。冷頁列表的水印稍低一些,因為冷頁並不放置到緩存中,只用於一些不太關註性能的操作,其上限是batch值的兩倍。
(4)註冊活動記憶體區
活動記憶體區就是不包含空洞的記憶體區。必須使用add_active_range在全局變數early_node_map中註冊記憶體區。當前註冊的記憶體區數目記載在


