
使用SSMS資料庫管理工具修改索引 使用表設計器修改索引 表設計器可以修改任何類型的索引,修改索引的步驟相同,本示例為修改唯一非聚集索引。 1、連接資料庫,選擇資料庫,選擇數據表-》右鍵點擊表-》選擇設計。 2、在表設計器視窗-》選擇要修改的數據列-》右鍵點擊-》選擇要修改的索引類型。 3、在彈出框 ...
使用SSMS資料庫管理工具修改索引
使用表設計器修改索引
表設計器可以修改任何類型的索引,修改索引的步驟相同,本示例為修改唯一非聚集索引。
1、連接資料庫,選擇資料庫,選擇數據表-》右鍵點擊表-》選擇設計。
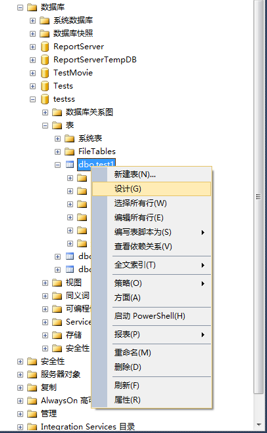
2、在表設計器視窗-》選擇要修改的數據列-》右鍵點擊-》選擇要修改的索引類型。
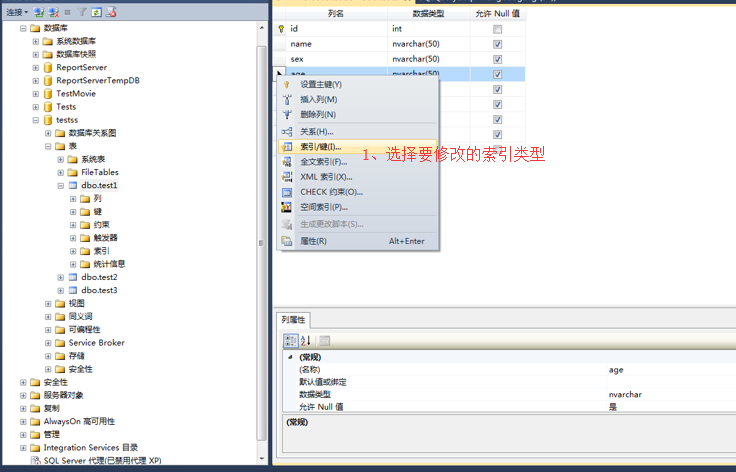
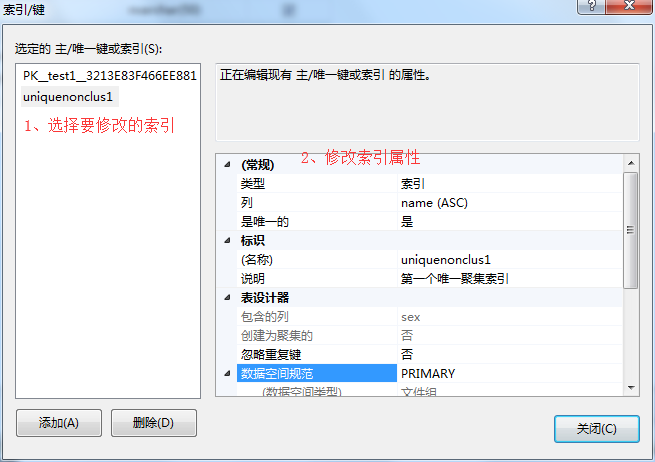
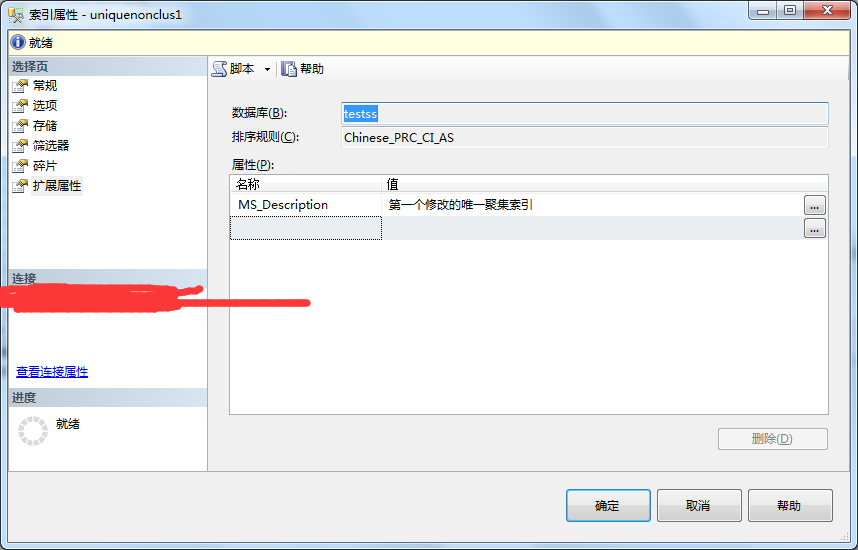
3、在彈出框中-》選擇要修改的索引-》找到要修改的索引屬性進行修改-》修改完成點擊關閉。
4、點擊保存按鈕或者ctrl+s》關閉表設計器-》刷新表-》查看結果。
使用對象資源管理器修改索引
1、連接資料庫,選擇資料庫,選擇數據表-》展開數據表-》展開索引-》選擇要修改的索引-》右鍵點擊-》選擇屬性(如果展開索引以後不能選擇屬性,刷新資料庫和數據表重新嘗試)。
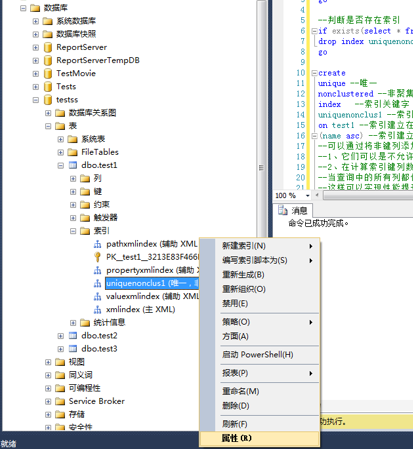
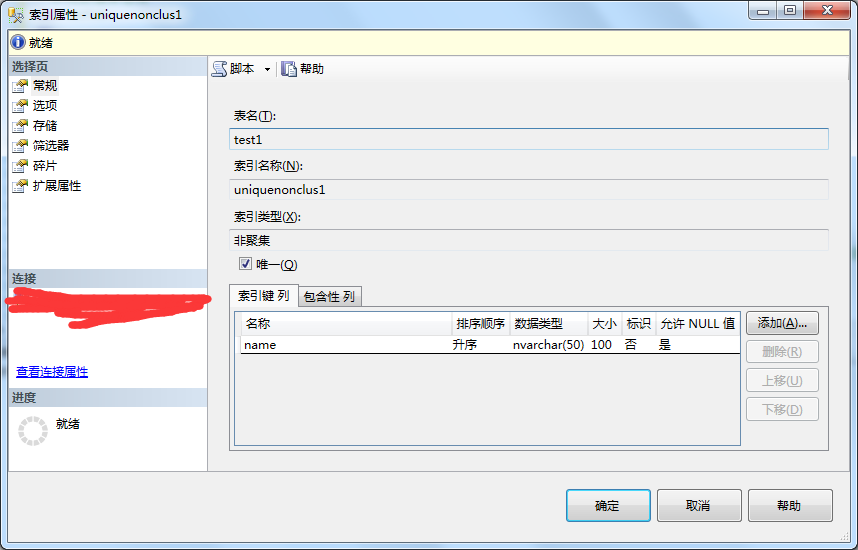
2、在索引屬性彈出框-》選擇你要修改的屬性-》修改完成點擊確定。
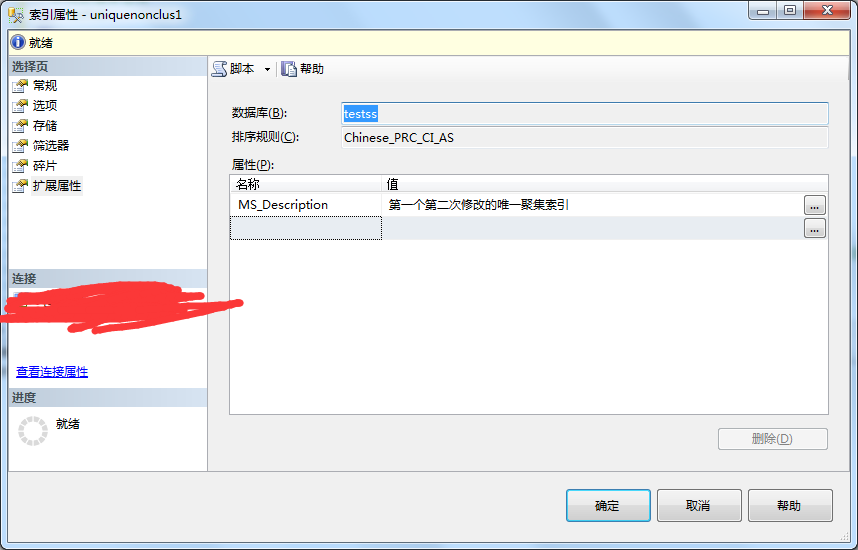
3、再次點開屬性查看修改結果。
使用T-SQL腳本修改索引
修改索引列
若要添加、刪除或更改索引列的位置,必須刪除並重新創建該索引,詳細可以參考本人之前寫的創建索引。
修改索引屬性
使用SQL腳本設置了幾個選項
語法:
/**********修改索引部分屬性**********/
--聲明資料庫引用
use 資料庫名;
go
--修改索引屬性
alter index 索引名
on 表名
set(
--statistics_norecompute:指定是否重新計算統計信息。
--statistics_norecompute=on:過時的統計信息不會自動重新計算。
--statistics_norecompute=off:啟用自動統計信息更新。
statistics_norecompute={ on | off },
--ignore_dup_key:指定在插入操作嘗試向唯一索引插入重覆鍵值時的響應類型。 IGNORE_DUP_KEY 選項僅適用於創建或重新生成索引後發生的插入操作。 當執行 CREATE INDEX、ALTER INDEX 或 UPDATE 時,該選項無效。 預設為 OFF。
--ignore_dup_key=on:打開,將重覆鍵值插入唯一索引時會出現警告消息。只有違反唯一性的行為才會失敗。
--ignore_dup_key=off:關閉,將重覆鍵值插入唯一索引時會出現錯誤消息。回滾整個INSERT操作。對於對視圖創建的索引、非唯一索引、XML 索引、空間索引以及篩選的索引,IGNORE_DUP_KEY 不能設置為 ON
ignore_dup_key={ on | off },
--allow_row_locks:指定是否允許行鎖。
--allow_row_locks=on:訪問索引時允許行鎖。資料庫引擎確定何時使用行鎖。
--allow_row_locks=off:不使用行鎖。
allow_row_locks={ on | off },
--allow_page_locks:指定是否允許使用頁鎖。
--allow_page_locks=on:訪問索引時允許頁鎖。資料庫引擎確定何時使用頁鎖。
--allow_page_locks=off:不使用頁鎖。
allow_page_locks={ on | off }
);
go
示例:
/**********修改索引屬性**********/
--聲明資料庫引用
use testss;
go
--修改索引屬性
alter index uniquenonclus2
on test1
set(
--statistics_norecompute:指定是否重新計算統計信息。
--statistics_norecompute=on:過時的統計信息不會自動重新計算。
--statistics_norecompute=off:啟用自動統計信息更新。
statistics_norecompute=on,
--ignore_dup_key:指定在插入操作嘗試向唯一索引插入重覆鍵值時的響應類型。 IGNORE_DUP_KEY 選項僅適用於創建或重新生成索引後發生的插入操作。 當執行 CREATE INDEX、ALTER INDEX 或 UPDATE 時,該選項無效。 預設為 OFF。
--ignore_dup_key=on:打開,將重覆鍵值插入唯一索引時會出現警告消息。只有違反唯一性的行為才會失敗。
--ignore_dup_key=off:關閉,將重覆鍵值插入唯一索引時會出現錯誤消息。回滾整個INSERT操作。對於對視圖創建的索引、非唯一索引、XML 索引、空間索引以及篩選的索引,IGNORE_DUP_KEY 不能設置為 ON
ignore_dup_key=off,
--allow_row_locks:指定是否允許行鎖。
--allow_row_locks=on:訪問索引時允許行鎖。資料庫引擎確定何時使用行鎖。
--allow_row_locks=off:不使用行鎖。
allow_row_locks=on,
--allow_page_locks:指定是否允許使用頁鎖。
--allow_page_locks=on:訪問索引時允許頁鎖。資料庫引擎確定何時使用頁鎖。
--allow_page_locks=off:不使用頁鎖。
allow_page_locks=on
);
go
使用SQL腳本重新生成現有索引
語法:
/**********修改索引部分屬性**********/
--聲明資料庫引用
use 資料庫名;
go
--該示例重新生成現有索引,併在重新生成操作過程中應用指定的填充因數。
alter index 索引名
on 表名
rebuild with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空間百分比應用於索引的中間級頁。
--pad_index=off或未指定 fillfactor:考慮到中間級頁上的鍵集,可以將中間級頁幾乎填滿,但至少要為最大索引行留出足夠空間。
pad_index={ on | off },
--statistics_norecompute:指定是否重新計算統計信息。
--statistics_norecompute=on:過時的統計信息不會自動重新計算。
--statistics_norecompute=off:啟用自動統計信息更新。
statistics_norecompute={ on | off },
--sort_in_tempdb:指定是否將排序結果存儲在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存儲用於生成索引的中間排序結果。如果tempdb與用戶資料庫不在同一組磁碟上,就可縮短創建索引所需的時間。但是,這會增加索引生成期間所使用的磁碟空間量。
--sort_in_tempdb=off:中間排序結果與索引存儲在同一資料庫中。
sort_in_tempdb={ on | off },
--ignore_dup_key:指定在插入操作嘗試向唯一索引插入重覆鍵值時的響應類型。 IGNORE_DUP_KEY 選項僅適用於創建或重新生成索引後發生的插入操作。 當執行 CREATE INDEX、ALTER INDEX 或 UPDATE 時,該選項無效。 預設為 OFF。
--ignore_dup_key=on:打開,將重覆鍵值插入唯一索引時會出現警告消息。只有違反唯一性的行為才會失敗。
--ignore_dup_key=off:關閉,將重覆鍵值插入唯一索引時會出現錯誤消息。回滾整個INSERT操作。對於對視圖創建的索引、非唯一索引、XML 索引、空間索引以及篩選的索引,IGNORE_DUP_KEY 不能設置為 ON
ignore_dup_key={ on | off },
--online:指定在索引操作期間基礎表和關聯的索引是否可用於查詢和數據修改操作。 預設為 OFF。 REBUILD 可作為 ONLINE 操作執行。
--online=on:在索引操作期間不持有長期表鎖。 在索引操作的主要階段,源表上只使用意向共用 (IS) 鎖。
--這使得能夠繼續對基礎表和索引進行查詢或更新。
--操作開始時,在很短的時間內對源對象持有共用 (S) 鎖。
--操作結束時,如果創建非聚集索引,將在短期內獲取對源的 S(共用)鎖;
--當聯機創建或刪除聚集索引時,以及重新生成聚集或非聚集索引時,將在短期內獲取 SCH-M(架構修改)鎖。 但聯機索引鎖是短的元數據鎖,特別是 Sch-M 鎖必須等待此表上的所有阻塞事務完成。
--在等待期間,Sch-M 鎖在訪問同一表時阻止在此鎖後等待的所有其他事務。 對本地臨時表創建索引時,ONLINE 不能設置為 ON。
--online=off:在索引操作期間應用表鎖。這樣可以防止所有用戶在操作期間訪問基礎表。
--創建、重新生成或刪除聚集索引或者重新生成或刪除非聚集索引的離線索引操作將對錶獲取架構修改 (Sch-M) 鎖。
--這樣可以防止所有用戶在操作期間訪問基礎表。 創建非聚集索引的離線索引操作將對錶獲取共用 (S) 鎖。 這樣可以防止更新基礎表,但允許讀操作(如 SELECT 語句)。
online={ on | off },
--allow_row_locks:指定是否允許行鎖。
--allow_row_locks=on:訪問索引時允許行鎖。資料庫引擎確定何時使用行鎖。
--allow_row_locks=off:不使用行鎖。
allow_row_locks={ on | off },
--allow_page_locks:指定是否允許使用頁鎖。
--allow_page_locks=on:訪問索引時允許頁鎖。資料庫引擎確定何時使用頁鎖。
--allow_page_locks=off:不使用頁鎖。
allow_page_locks={ on | off },
--fillfactor=n:指定一個百分比,指示在資料庫引擎創建或修改索引的過程中,應將每個索引頁面的葉級填充到什麼程度。 指定的值必須是 1 到 100 之間的整數。 預設值為 0。
fillfactor=n,
--maxdop=max_degree_of_parallelism:在索引操作期間替代 max degree of parallelism 配置選項。 有關詳細信息,請參閱 配置 max degree of parallelism 伺服器配置選項。 使用 MAXDOP 可以限制在執行並行計劃的過程中使用的處理器數量。 最大數量為 64 個處理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成並行計劃。
-->1 - 將並行索引操作中使用的最大處理器數量限製為指定數量。
--0(預設值)- 根據當前系統工作負荷使用實際數量的處理器或更少數量的處理器。
--有關詳細信息,請參閱 配置並行索引操作。
maxdop=1
--data_compression=row:為指定的表、分區號或分區範圍指定數據壓縮選項。 選項如下所示:
--none
--不壓縮表或指定的分區。 僅適用於行存儲表;不適用於列存儲表。
--row
--使用行壓縮來壓縮表或指定的分區。 僅適用於行存儲表;不適用於列存儲表。
--page
--使用頁壓縮來壓縮表或指定的分區。 僅適用於行存儲表;不適用於列存儲表。
--columnstore
--適用範圍: SQL Server 2014 (12.x) 到 SQL Server 2017。
--僅適用於列存儲表。 COLUMNSTORE 指定對使用 COLUMNSTORE_ARCHIVE 選項壓縮的分區進行解壓縮。 還原數據時,將繼續通過用於所有列存儲表的列存儲壓縮對 COLUMNSTORE 索引進行壓縮。
--columnstore_archive
--適用範圍: SQL Server 2014 (12.x) 到 SQL Server 2017。
--僅適用於列存儲表,這是使用聚集列存儲索引存儲的表。 COLUMNSTORE_ARCHIVE 會進一步將指定分區壓縮到更小。 這可用於存檔,或者用於要求更少存儲並且可以付出更多時間來進行存儲和檢索的其他情形
--data_compression=row --註意:只有 SQL Server Enterprise Edition 支持壓縮。
--on partitions ( { <partition_number_expression> | <range> } [ ,...n ] ) 適用範圍: SQL Server 2008 到 SQL Server 2017。
--指定對其應用 DATA_COMPRESSION 設置的分區。 如果表未分區,ON PARTITIONS 參數將生成錯誤。 如果不提供 ON PARTITIONS 子句,DATA_COMPRESSION 選項將應用於已分區表的所有分區。
--可以按以下方式指定 <partition_number_expression>:
--提供一個分區號,例如:ON PARTITIONS (2)。
--提供若幹單獨分區的分區號並用逗號將它們隔開,例如:ON PARTITIONS (1, 5)。
--同時提供範圍和單個分區,例如:ON PARTITIONS (2, 4, 6 TO 8)。
--<range> 可以指定為以單詞 TO 隔開的分區號,例如:ON PARTITIONS (6 TO 8)。
--,請多次指定 DATA_COMPRESSION 選項
--on partitions(1-2) --註意:分區之前表一定要有分區方案
);
go
示例:
/**********修改索引部分屬性**********/
--聲明資料庫引用
use testss;
go
--該示例重新生成現有索引,併在重新生成操作過程中應用指定的填充因數。
alter index uniquenonclus2
on test1
rebuild with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空間百分比應用於索引的中間級頁。
--pad_index=off或未指定 fillfactor:考慮到中間級頁上的鍵集,可以將中間級頁幾乎填滿,但至少要為最大索引行留出足夠空間。
pad_index=on,
--statistics_norecompute:指定是否重新計算統計信息。
--statistics_norecompute=on:過時的統計信息不會自動重新計算。
--statistics_norecompute=off:啟用自動統計信息更新。
statistics_norecompute=off,
--sort_in_tempdb:指定是否將排序結果存儲在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存儲用於生成索引的中間排序結果。如果tempdb與用戶資料庫不在同一組磁碟上,就可縮短創建索引所需的時間。但是,這會增加索引生成期間所使用的磁碟空間量。
--sort_in_tempdb=off:中間排序結果與索引存儲在同一資料庫中。
sort_in_tempdb=off,
--ignore_dup_key:指定在插入操作嘗試向唯一索引插入重覆鍵值時的響應類型。 IGNORE_DUP_KEY 選項僅適用於創建或重新生成索引後發生的插入操作。 當執行 CREATE INDEX、ALTER INDEX 或 UPDATE 時,該選項無效。 預設為 OFF。
--ignore_dup_key=on:打開,將重覆鍵值插入唯一索引時會出現警告消息。只有違反唯一性的行為才會失敗。
--ignore_dup_key=off:關閉,將重覆鍵值插入唯一索引時會出現錯誤消息。回滾整個INSERT操作。對於對視圖創建的索引、非唯一索引、XML 索引、空間索引以及篩選的索引,IGNORE_DUP_KEY 不能設置為 ON
ignore_dup_key=off,
--online:指定在索引操作期間基礎表和關聯的索引是否可用於查詢和數據修改操作。 預設為 OFF。 REBUILD 可作為 ONLINE 操作執行。
--online=on:在索引操作期間不持有長期表鎖。 在索引操作的主要階段,源表上只使用意向共用 (IS) 鎖。
--這使得能夠繼續對基礎表和索引進行查詢或更新。
--操作開始時,在很短的時間內對源對象持有共用 (S) 鎖。
--操作結束時,如果創建非聚集索引,將在短期內獲取對源的 S(共用)鎖;
--當聯機創建或刪除聚集索引時,以及重新生成聚集或非聚集索引時,將在短期內獲取 SCH-M(架構修改)鎖。 但聯機索引鎖是短的元數據鎖,特別是 Sch-M 鎖必須等待此表上的所有阻塞事務完成。
--在等待期間,Sch-M 鎖在訪問同一表時阻止在此鎖後等待的所有其他事務。 對本地臨時表創建索引時,ONLINE 不能設置為 ON。
--online=off:在索引操作期間應用表鎖。這樣可以防止所有用戶在操作期間訪問基礎表。
--創建、重新生成或刪除聚集索引或者重新生成或刪除非聚集索引的離線索引操作將對錶獲取架構修改 (Sch-M) 鎖。
--這樣可以防止所有用戶在操作期間訪問基礎表。 創建非聚集索引的離線索引操作將對錶獲取共用 (S) 鎖。 這樣可以防止更新基礎表,但允許讀操作(如 SELECT 語句)。
online=off,
--allow_row_locks:指定是否允許行鎖。
--allow_row_locks=on:訪問索引時允許行鎖。資料庫引擎確定何時使用行鎖。
--allow_row_locks=off:不使用行鎖。
allow_row_locks=on,
--allow_page_locks:指定是否允許使用頁鎖。
--allow_page_locks=on:訪問索引時允許頁鎖。資料庫引擎確定何時使用頁鎖。
--allow_page_locks=off:不使用頁鎖。
allow_page_locks=on,
--fillfactor=n:指定一個百分比,指示在資料庫引擎創建或修改索引的過程中,應將每個索引頁面的葉級填充到什麼程度。 指定的值必須是 1 到 100 之間的整數。 預設值為 0。
fillfactor=1,
--maxdop=max_degree_of_parallelism:在索引操作期間替代 max degree of parallelism 配置選項。 有關詳細信息,請參閱 配置 max degree of parallelism 伺服器配置選項。 使用 MAXDOP 可以限制在執行並行計劃的過程中使用的處理器數量。 最大數量為 64 個處理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成並行計劃。
-->1 - 將並行索引操作中使用的最大處理器數量限製為指定數量。
--0(預設值)- 根據當前系統工作負荷使用實際數量的處理器或更少數量的處理器。
--有關詳細信息,請參閱 配置並行索引操作。
maxdop=1
--data_compression=row:為指定的表、分區號或分區範圍指定數據壓縮選項。 選項如下所示:
--none
--不壓縮表或指定的分區。 僅適用於行存儲表;不適用於列存儲表。
--row
--使用行壓縮來壓縮表或指定的分區。 僅適用於行存儲表;不適用於列存儲表。
--page
--使用頁壓縮來壓縮表或指定的分區。 僅適用於行存儲表;不適用於列存儲表。
--columnstore
--適用範圍: SQL Server 2014 (12.x) 到 SQL Server 2017。
--僅適用於列存儲表。 COLUMNSTORE 指定對使用 COLUMNSTORE_ARCHIVE 選項壓縮的分區進行解壓縮。 還原數據時,將繼續通過用於所有列存儲表的列存儲壓縮對 COLUMNSTORE 索引進行壓縮。
--columnstore_archive
--適用範圍: SQL Server 2014 (12.x) 到 SQL Server 2017。
--僅適用於列存儲表,這是使用聚集列存儲索引存儲的表。 COLUMNSTORE_ARCHIVE 會進一步將指定分區壓縮到更小。 這可用於存檔,或者用於要求更少存儲並且可以付出更多時間來進行存儲和檢索的其他情形
--data_compression=row --註意:只有 SQL Server Enterprise Edition 支持壓縮。
--on partitions ( { <partition_number_expression> | <range> } [ ,...n ] ) 適用範圍: SQL Server 2008 到 SQL Server 2017。
--指定對其應用 DATA_COMPRESSION 設置的分區。 如果表未分區,ON PARTITIONS 參數將生成錯誤。 如果不提供 ON PARTITIONS 子句,DATA_COMPRESSION 選項將應用於已分區表的所有分區。
--可以按以下方式指定 <partition_number_expression>:
--提供一個分區號,例如:ON PARTITIONS (2)。
--提供若幹單獨分區的分區號並用逗號將它們隔開,例如:ON PARTITIONS (1, 5)。
--同時提供範圍和單個分區,例如:ON PARTITIONS (2, 4, 6 TO 8)。
--<range> 可以指定為以單詞 TO 隔開的分區號,例如:ON PARTITIONS (6 TO 8)。
--,請多次指定 DATA_COMPRESSION 選項
--on partitions(1-2) --註意:分區之前表一定要有分區方案
);
go
修改索引名稱
語法:
/**********修改索引名稱**********/
--聲明資料庫引用
use 資料庫名;
go
--修改索引名稱
exec sp_rename N'表名.索引名',N'索引名',N'index';
go
示例:
/**********修改索引名稱**********/
--聲明資料庫引用
use testss;
go
--修改索引名稱
exec sp_rename N'test1.uniquenonclus1',N'uniquenonclus2',N'index';
go

