
絕大部分寫業務的程式員,在實際開發中使用 Redis 的時候,只會 Set Value 和 Get Value 兩個操作,對 Redis 整體缺乏一個認知。這裡對 Redis 常見問題做一個總結,解決大家的知識盲點。 1、為什麼使用 Redis 在項目中使用 Redis,主要考慮兩個角度:性能和併發 ...
絕大部分寫業務的程式員,在實際開發中使用 Redis 的時候,只會 Set Value 和 Get Value 兩個操作,對 Redis 整體缺乏一個認知。這裡對 Redis 常見問題做一個總結,解決大家的知識盲點。
1、為什麼使用 Redis
在項目中使用 Redis,主要考慮兩個角度:性能和併發。如果只是為了分散式鎖這些其他功能,還有其他中間件 Zookpeer 等代替,並非一定要使用 Redis。
性能:
如下圖所示,我們在碰到需要執行耗時特別久,且結果不頻繁變動的 SQL,就特別適合將運行結果放入緩存。這樣,後面的請求就去緩存中讀取,使得請求能夠迅速響應。
特別是在秒殺系統,在同一時間,幾乎所有人都在點,都在下單。。。執行的是同一操作———向資料庫查數據。
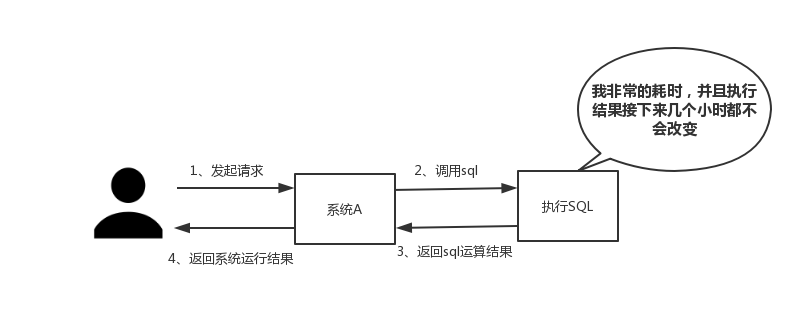
根據交互效果的不同,響應時間沒有固定標準。在理想狀態下,我們的頁面跳轉需要在瞬間解決,對於頁內操作則需要在剎那間解決。
併發:
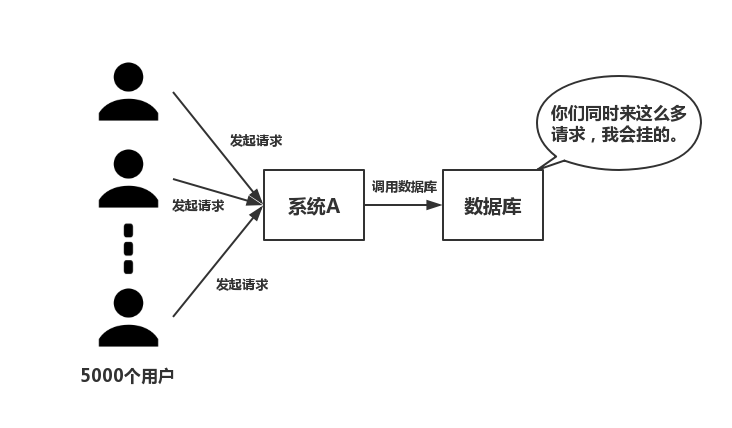
如下圖所示,在大併發的情況下,所有的請求直接訪問資料庫,資料庫會出現連接異常。這個時候,就需要使用 Redis 做一個緩衝操作,讓請求先訪問到 Redis,而不是直接訪問資料庫。
使用 Redis 的常見問題
-
緩存和資料庫雙寫一致性問題
-
緩存雪崩問題
-
緩存擊穿問題
-
緩存的併發競爭問題
2、單線程的 Redis 為什麼這麼快
這個問題是對 Redis 內部機制的一個考察。很多人都不知道 Redis 是單線程工作模型。
原因主要是以下三點:
-
純記憶體操作
-
單線程操作,避免了頻繁的上下文切換
-
採用了非阻塞 I/O 多路復用機制
仔細說一說 I/O 多路復用機制,打一個比方:小名在 A 城開了一家快餐店店,負責同城快餐服務。小明因為資金限制,雇佣了一批配送員,然後小曲發現資金不夠了,只夠買一輛車送快遞。
經營方式一
客戶每下一份訂單,小明就讓一個配送員盯著,然後讓人開車去送。慢慢的小曲就發現了這種經營方式存在下述問題:
-
時間都花在了搶車上了,大部分配送員都處在閑置狀態,搶到車才能去送。
-
隨著下單的增多,配送員也越來越多,小明發現快遞店裡越來越擠,沒辦法雇佣新的配送員了。
-
配送員之間的協調很花時間。
綜合上述缺點,小明痛定思痛,提出了經營方式二。
經營方式二
小明只雇佣一個配送員。當客戶下單,小明按送達地點標註好,依次放在一個地方。最後,讓配送員依次開著車去送,送好了就回來拿下一個。上述兩種經營方式對比,很明顯第二種效率更高。
在上述比喻中:
-
每個配送員→每個線程
-
每個訂單→每個 Socket(I/O 流)
-
訂單的送達地點→Socket 的不同狀態
-
客戶送餐請求→來自客戶端的請求
-
明曲的經營方式→服務端運行的代碼
-
一輛車→CPU 的核數
於是有瞭如下結論:
-
經營方式一就是傳統的併發模型,每個 I/O 流(訂單)都有一個新的線程(配送員)管理。
-
經營方式二就是 I/O 多路復用。只有單個線程(一個配送員),通過跟蹤每個 I/O 流的狀態(每個配送員的送達地點),來管理多個 I/O 流。
下麵類比到真實的 Redis 線程模型,如圖所示:
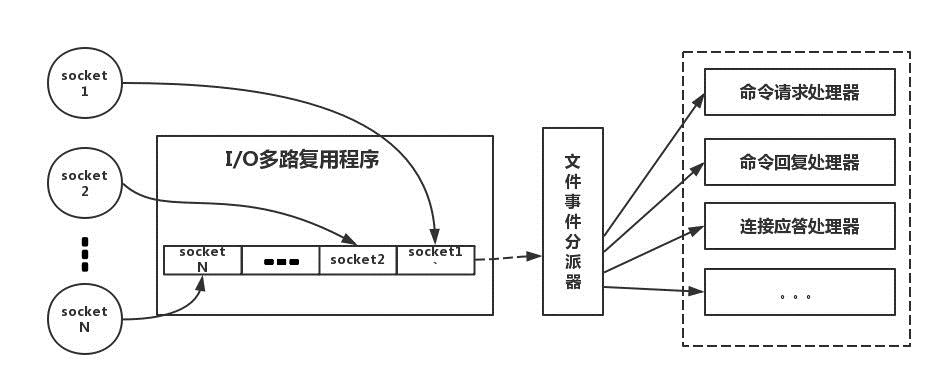
Redis-client 在操作的時候,會產生具有不同事件類型的 Socket。在服務端,有一段 I/O 多路復用程式,將其置入隊列之中。然後,文件事件分派器,依次去隊列中取,轉發到不同的事件處理器中。
3、Redis 的數據類型及使用場景
一個合格的程式員,這五種類型都會用到。
String
最常規的 set/get 操作,Value 可以是 String 也可以是數字。一般做一些複雜的計數功能的緩存。
Hash
這裡 Value 存放的是結構化的對象,比較方便的就是操作其中的某個欄位。我在做單點登錄的時候,就是用這種數據結構存儲用戶信息,以 CookieId 作為 Key,設置 30 分鐘為緩存過期時間,能很好的模擬出類似 Session 的效果。
List
使用 List 的數據結構,可以做簡單的消息隊列的功能。另外,可以利用 lrange 命令,做基於 Redis 的分頁功能,性能極佳,用戶體驗好。
Set
因為 Set 堆放的是一堆不重覆值的集合。所以可以做全局去重的功能。我們的系統一般都是集群部署,使用 JVM 自帶的 Set 比較麻煩。另外,就是利用交集、並集、差集等操作,可以計算共同喜好,全部的喜好,自己獨有的喜好等功能。
Sorted Set
Sorted Set 多了一個權重參數 Score,集合中的元素能夠按 Score 進行排列。可以做排行榜應用,取 TOP N 操作。Sorted Set 可以用來做延時任務。
4、Redis 的過期策略和記憶體淘汰機制
Redis 是否用到家,從這就能看出來。比如你 Redis 只能存 5G 數據,可是你寫了 10G,那會刪 5G 的數據。怎麼刪的,這個問題思考過麽?
正解:Redis 採用的是定期刪除+惰性刪除策略。
為什麼不用定時刪除策略
定時刪除,用一個定時器來負責監視 Key,過期則自動刪除。雖然記憶體及時釋放,但是十分消耗 CPU 資源。在大併發請求下,CPU 要將時間應用在處理請求,而不是刪除 Key,因此沒有採用這一策略。
定期刪除+惰性刪除如何工作
定期刪除,Redis 預設每個 100ms 檢查,有過期 Key 則刪除。需要說明的是,Redis 不是每個 100ms 將所有的 Key 檢查一次,而是隨機抽取進行檢查。如果只採用定期刪除策略,會導致很多 Key 到時間沒有刪除。於是,惰性刪除派上用場。
採用定期刪除+惰性刪除就沒其他問題了麽
不是的,如果定期刪除沒刪除掉 Key。並且你也沒及時去請求 Key,也就是說惰性刪除也沒生效。這樣,Redis 的記憶體會越來越高。那麼就應該採用記憶體淘汰機制。
在 redis.conf 中有一行配置:
# maxmemory-policy volatile-lru
該配置就是配記憶體淘汰策略的:
-
noeviction:當記憶體不足以容納新寫入數據時,新寫入操作會報錯。
-
allkeys-lru:當記憶體不足以容納新寫入數據時,在鍵空間中,移除最近最少使用的 Key。(推薦使用,目前項目在用這種)(最近最久使用演算法)
-
allkeys-random:當記憶體不足以容納新寫入數據時,在鍵空間中,隨機移除某個 Key。(應該也沒人用吧,你不刪最少使用 Key,去隨機刪)
-
volatile-lru:當記憶體不足以容納新寫入數據時,在設置了過期時間的鍵空間中,移除最近最少使用的 Key。這種情況一般是把 Redis 既當緩存,又做持久化存儲的時候才用。(不推薦)
-
volatile-random:當記憶體不足以容納新寫入數據時,在設置了過期時間的鍵空間中,隨機移除某個 Key。(依然不推薦)
-
volatile-ttl:當記憶體不足以容納新寫入數據時,在設置了過期時間的鍵空間中,有更早過期時間的 Key 優先移除。(不推薦)
5、Redis 和資料庫雙寫一致性問題
一致性問題還可以再分為最終一致性和強一致性。資料庫和緩存雙寫,就必然會存在不一致的問題。前提是如果對數據有強一致性要求,不能放緩存。我們所做的一切,只能保證最終一致性。
另外,我們所做的方案從根本上來說,只能降低不一致發生的概率。因此,有強一致性要求的數據,不能放緩存。首先,採取正確更新策略,先更新資料庫,再刪緩存。其次,因為可能存在刪除緩存失敗的問題,提供一個補償措施即可,例如利用消息隊列。
6、如何應對緩存穿透和緩存雪崩問題
這兩個問題,一般中小型傳統軟體企業很難碰到。如果有大併發的項目,流量有幾百萬左右,這兩個問題一定要深刻考慮。緩存穿透,即黑客故意去請求緩存中不存在的數據,導致所有的請求都懟到資料庫上,從而資料庫連接異常。
緩存穿透解決方案:
-
利用互斥鎖,緩存失效的時候,先去獲得鎖,得到鎖了,再去請求資料庫。沒得到鎖,則休眠一段時間重試。
-
採用非同步更新策略,無論 Key 是否取到值,都直接返回。Value 值中維護一個緩存失效時間,緩存如果過期,非同步起一個線程去讀資料庫,更新緩存。需要做緩存預熱(項目啟動前,先載入緩存)操作。
-
提供一個能迅速判斷請求是否有效的攔截機制,比如,利用布隆過濾器,內部維護一系列合法有效的 Key。迅速判斷出,請求所攜帶的 Key 是否合法有效。如果不合法,則直接返回。
緩存雪崩,即緩存同一時間大面積的失效,這個時候又來了一波請求,結果請求都懟到資料庫上,從而導致資料庫連接異常。
緩存雪崩解決方案:
-
給緩存的失效時間,加上一個隨機值,避免集體失效。
-
使用互斥鎖,但是該方案吞吐量明顯下降了。
-
雙緩存。我們有兩個緩存,緩存 A 和緩存 B。緩存 A 的失效時間為 20 分鐘,緩存 B 不設失效時間。自己做緩存預熱操作。
然後細分以下幾個小點:從緩存 A 讀資料庫,有則直接返回;A 沒有數據,直接從 B 讀數據,直接返回,並且非同步啟動一個更新線程,更新線程同時更新緩存 A 和緩存 B。
7、如何解決 Redis 的併發競爭 Key 問題
這個問題大致就是,同時有多個子系統去 Set 一個 Key。這個時候要註意什麼呢?大家基本都是推薦用 Redis 事務機制。
但是我並不推薦使用 Redis 的事務機制。因為我們的生產環境,基本都是 Redis 集群環境,做了數據分片操作。你一個事務中有涉及到多個 Key 操作的時候,這多個 Key 不一定都存儲在同一個 redis-server 上。因此,Redis 的事務機制,十分雞肋。
如果對這個 Key 操作,不要求順序
這種情況下,準備一個分散式鎖,大家去搶鎖,搶到鎖就做 set 操作即可,比較簡單。
如果對這個 Key 操作,要求順序
假設有一個 key1,系統 A 需要將 key1 設置為 valueA,系統 B 需要將 key1 設置為 valueB,系統 C 需要將 key1 設置為 valueC。
期望按照 key1 的 value 值按照 valueA > valueB > valueC 的順序變化。這種時候我們在數據寫入資料庫的時候,需要保存一個時間戳。
假設時間戳如下:
系統 A key 1 {valueA 3:00}
系統 B key 1 {valueB 3:05}
系統 C key 1 {valueC 3:10}
那麼,假設系統 B 先搶到鎖,將 key1 設置為{valueB 3:05}。接下來系統 A 搶到鎖,發現自己的 valueA 的時間戳早於緩存中的時間戳,那就不做 set 操作了,以此類推。其他方法,比如利用隊列,將 set 方法變成串列訪問也可以。
8、總結
Redis 在國內各大公司都能看到其身影,比如我們熟悉的新浪,阿裡,騰訊,百度,美團,小米等。學習 Redis,這幾方面尤其重要:Redis 客戶端、Redis 高級功能、Redis 持久化和開發運維常用問題探討、Redis 複製的原理和優化策略、Redis 分散式解決方案等。


