
單表查詢 先創建表 1.註意: select * from t1 where 條件 group by 分組欄位 1.分組只能查詢分組欄位,要想查看其餘的利用聚合函數 2.聚合函數的分類:count,min,max,avg,group_concat,sum等。 3.模糊匹配:用like關鍵字。 sel ...
單表查詢
先創建表
#創建表 create table employee( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, #一個部門一個屋子 depart_id int ); #查看表結構 mysql> desc employee; +--------------+-----------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------------+-----------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | sex | enum('male','female') | NO | | male | | | age | int(3) unsigned | NO | | 28 | | | hire_date | date | NO | | NULL | | | post | varchar(50) | YES | | NULL | | | post_comment | varchar(100) | YES | | NULL | | | salary | double(15,2) | YES | | NULL | | | office | int(11) | YES | | NULL | | | depart_id | int(11) | YES | | NULL | | +--------------+-----------------------+------+-----+---------+----------------+ #插入記錄 #三個部門:教學,銷售,運營 insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values ('egon','male',18,'20170301','teacher',7300.33,401,1), #以下是教學部 ('alex','male',78,'20150302','teacher',1000000.31,401,1), ('wupeiqi','male',81,'20130305','teacher',8300,401,1), ('yuanhao','male',73,'20140701','teacher',3500,401,1), ('liwenzhou','male',28,'20121101','teacher',2100,401,1), ('jingliyang','female',18,'20110211','teacher',9000,401,1), ('jinxin','male',18,'19000301','teacher',30000,401,1), ('成龍','male',48,'20101111','teacher',10000,401,1), ('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是銷售部門 ('丫丫','female',38,'20101101','sale',2000.35,402,2), ('丁丁','female',18,'20110312','sale',1000.37,402,2), ('星星','female',18,'20160513','sale',3000.29,402,2), ('格格','female',28,'20170127','sale',4000.33,402,2), ('張野','male',28,'20160311','operation',10000.13,403,3), #以下是運營部門 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬銀','female',18,'20130311','operation',19000,403,3), ('程咬銅','male',18,'20150411','operation',18000,403,3), ('程咬鐵','female',18,'20140512','operation',17000,403,3) ;


1.註意: select * from t1 where 條件 group by 分組欄位 1.分組只能查詢分組欄位,要想查看其餘的利用聚合函數 2.聚合函數的分類:count,min,max,avg,group_concat,sum等。 3.模糊匹配:用like關鍵字。 select * from t1 where name like '%eg%'; #%表示任意字元 select * from t1 where name like 'd__l'; #一個下劃線表示一個字元,兩個下劃線就表示兩個字元 4.拷貝表 :create table t2 select * from t1; create table t2 select * from t1 where 1=2 ;小知識
一.查詢語法
SELECT 欄位1,欄位2... FROM 表名
WHERE 條件
GROUP BY field
HAVING 篩選
ORDER BY field
LIMIT 限制條數
二.簡單查詢
#簡單查詢 SELECT id,name,sex,age,hire_date,post,post_comment,salary,office,depart_id FROM employee; SELECT * FROM employee; SELECT name,salary FROM employee; #避免重覆DISTINCT SELECT DISTINCT post FROM employee; #通過四則運算查詢 SELECT name, salary*12 FROM employee; SELECT name, salary*12 AS Annual_salary FROM employee; SELECT name, salary*12 Annual_salary FROM employee; #定義顯示格式 CONCAT() 函數用於連接字元串 SELECT CONCAT('姓名: ',name,' 年薪: ', salary*12) AS Annual_salary FROM employee; CONCAT_WS() 第一個參數為分隔符 SELECT CONCAT_WS(':',name,salary*12) AS Annual_salary FROM employee;
小練習:
1 查出所有員工的名字,薪資,格式為 <名字:egon> <薪資:3000> select concat('<名字:',name,'> ' ,'<薪資:',salary,'>' ) from employee; 2 查出所有的崗位(去掉重覆) select distinct depart_id from employee; 3 查出所有員工名字,以及他們的年薪,年薪的欄位名為年薪 select name,salary*12 年薪 from employee;
三.where約束
where字句中可以使用:
1. 比較運算符:> < >= <= <> !=
2. between 80 and 100 值在10到20之間
3. in(80,90,100) 值是80或90或100
4. like 'eg%'
可以是%或_,
%表示任意多字元
_表示一個字元
like 'e__n' :
5. 邏輯運算符:在多個條件直接可以使用邏輯運算符 and or not
#1:單條件查詢 SELECT name FROM employee WHERE post='sale'; #2:多條件查詢 SELECT name,salary FROM employee WHERE post='teacher' AND salary>10000; #3:關鍵字BETWEEN AND SELECT name,salary FROM employee WHERE salary BETWEEN 10000 AND 20000; SELECT name,salary FROM employee WHERE salary NOT BETWEEN 10000 AND 20000; #4:關鍵字IS NULL(判斷某個欄位是否為NULL不能用等號,需要用IS) SELECT name,post_comment FROM employee WHERE post_comment IS NULL; SELECT name,post_comment FROM employee WHERE post_comment IS NOT NULL; SELECT name,post_comment FROM employee WHERE post_comment=''; 註意''是空字元串,不是null ps: 執行 update employee set post_comment='' where id=2; 再用上條查看,就會有結果了 #5:關鍵字IN集合查詢 SELECT name,salary FROM employee WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ; SELECT name,salary FROM employee WHERE salary IN (3000,3500,4000,9000) ; SELECT name,salary FROM employee WHERE salary NOT IN (3000,3500,4000,9000) ; #6:關鍵字LIKE模糊查詢 通配符’%’ SELECT * FROM employee WHERE name LIKE 'eg%'; 通配符’_’ SELECT * FROM employee WHERE name LIKE 'al__';
四.having過濾
having和where語法上是一樣的。
select * from employee where id>15; select * from employee having id>15;
不同點:
#!!!執行優先順序從高到低:where > group by > 聚合函數 > having >order by 1.where和having的區別 1. Where 是一個約束聲明,使用Where約束來自資料庫的數據,Where是在結果返回之前起作用的 (先找到表,按照where的約束條件,從表(文件)中取出數據),Where中不能使用聚合函數 2.Having是一個過濾聲明,是在查詢返回結果集以後對查詢結果進行的過濾操作 (先找到表,按照where的約束條件,從表(文件)中取出數據,然後group by分組, 如果沒有group by則所有記錄整體為一組,然後執行聚合函數,然後使用having對聚合的結果進行過濾), 在Having中可以使用聚合函數。 3.where的優先順序比having的優先順序高 4.having可以放到group by之後,而where只能放到group by 之前。
驗證:
1.查看員工的id>15的有多少個 select count(id) from employee where id>15;#正確,分析:where先執行,後執行聚合count(id), 然後select出結果 select count(id) from employee having id>15; #報錯,分析:先執行聚合count(id),後執行having過濾, #無法對id進行id>15的過濾 #以上兩條sql的順序是 1:找到表employee--->用where過濾---->沒有分組則預設一組執行聚合count(id)--->select執行查看組內id數目 2:找到表employee--->沒有分組則預設一組執行聚合count(id)---->having 基於上一步聚合的結果(此時只有count(id)欄位了) 進行id>15的過濾,很明顯,根本無法獲取到id欄位
小練習
1. 查詢各崗位內包含的員工個數小於2的崗位名、崗位內包含員工名字、個數 select post,group_concat(name) 員工姓名,count(id) 個數 from employee group by post having count(id)<2; 2. 查詢各崗位平均薪資大於10000的崗位名、平均工資 select post,avg(salary) from employee group by post having avg(salary)>10000; 3. 查詢各崗位平均薪資大於10000且小於20000的崗位名、平均工資 select post,avg(salary) from employee group by post having avg(salary) between 10000 and 20000;
五、分組查詢 group by
大前提:可以按照任意欄位分組,但分完組後,只能查看分組的那個欄位,要想取的組內的其他欄位信息,需要藉助函數
單獨使用GROUP BY關鍵字分組 select post from employee group by post; 註意:我們按照post欄位分組,那麼select查詢的欄位只能是post,想要獲取組內的其他相關信息,需要藉助函數 GROUP BY關鍵字和group_concat()函數一起使用 select post,group_concat(name) from employee group by post;#按照崗位分組,並查看組內成員名 select post,group_concat(name) as emp_members FROM employee group by post; GROUP BY與聚合函數一起使用 select post,count(id) as count from employee group by post;#按照崗位分組,並查看每個組有多少人
強調:
分組:一般相同的多的話就可以分成一組(一定是有重覆的欄位)
小練習:
1. 查詢崗位名以及崗位包含的所有員工名字 select post,group_concat(name) from employee group by post; 2. 查詢崗位名以及各崗位內包含的員工個數 select post,count(id) from employee group by post; 3. 查詢公司內男員工和女員工的個數 select sex,count(id) from employee group by sex; 4. 查詢崗位名以及各崗位的平均薪資 select post,max(salary) from employee group by post; 5. 查詢崗位名以及各崗位的最高薪資 select post,max(salary) from employee group by post; 6. 查詢崗位名以及各崗位的最低薪資 select post,min(salary) from employee group by post; 7. 查詢男員工與男員工的平均薪資,女員工與女員工的平均薪資 select sex,avg(salary) from employee group by sex;
六、關鍵字的執行優先順序(重點)
重點中的重點:關鍵字的執行優先順序 from where group by having select distinct order by limit
1.找到表:from
2.拿著where指定的約束條件,去文件/表中取出一條條記錄
3.將取出的一條條記錄進行分組group by,如果沒有group by,則整體作為一組
4.如果有聚合函數,則將組進行聚合
5.將4的結果過濾:having
6.查出結果:select
7.去重
8.將6的結果按條件排序:order by
9.將7的結果限制顯示條數
七、查詢排序order by
按單列排序 SELECT * FROM employee ORDER BY salary; SELECT * FROM employee ORDER BY salary ASC; SELECT * FROM employee ORDER BY salary DESC; 按多列排序:先按照age排序,如果年紀相同,則按照薪資排序 SELECT * from employee ORDER BY age, salary DESC; ===========order by========== 1.select * from employee order by salary;#如果不指定,預設就是升序 2.select * from employee order by salary asc; 3.select * from employee order by salary desc; #先按照年齡升序,當年齡相同的太多,分不清大小時,在按照工資降序 4.select * from employee order by age asc, salary desc;
多表查詢
一.介紹
首先先準備表
員工表和部門表
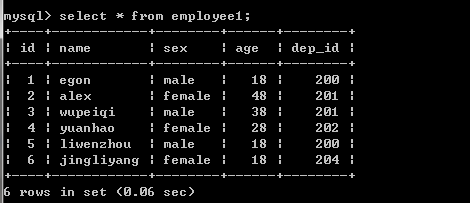
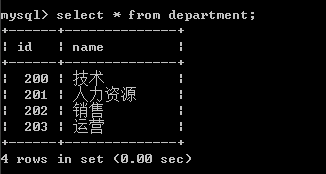
#建表 create table department( id int, name varchar(20) ); create table employee1( id int primary key auto_increment, name varchar(20), sex enum('male','female') not null default 'male', age int, dep_id int ); #插入數據 insert into department values (200,'技術'), (201,'人力資源'), (202,'銷售'), (203,'運營'); insert into employee1(name,sex,age,dep_id) values ('egon','male',18,200), ('alex','female',48,201), ('wupeiqi','male',38,201), ('yuanhao','female',28,202), ('liwenzhou','male',18,200), ('jingliyang','female',18,204) ;
查看
二、多表連接查詢
1.交叉連接:不適用任何匹配條件。生成笛卡爾積、
select * from employee1 ,department;
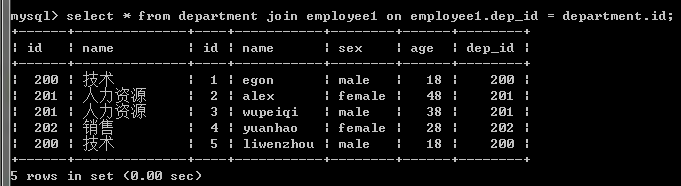
2.內連接:找兩張表共有的部分,相當於利用條件從笛卡爾積結果中篩選出了正確的結果。(只連接匹配的行)
#找兩張表共有的部分,相當於利用條件從笛卡爾積結果中篩選出了正確的結果 #department沒有204這個部門,因而employee表中關於204這條員工信息沒有匹配出來 select * from employee1,department where employee1.dep_id=department.id; #上面用where表示的可以用下麵的內連接表示,建議使用下麵的那種方法 select * from employee1 inner join department on employee1.dep_id=department.id; #也可以這樣表示哈 select employee1.id,employee1.name,employee1.age,employee1.sex,department.name from employee1,department where employee1.dep_id=department.id;
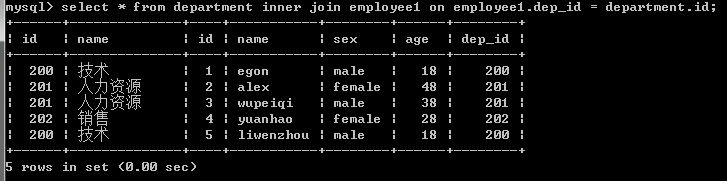
註意:內連接的join可以忽略不寫,但是還是加上看起來清楚點
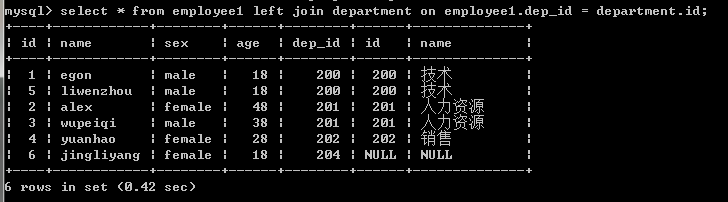
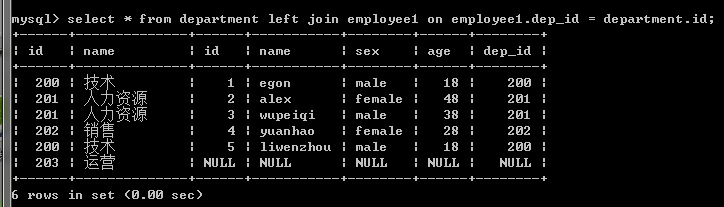
3.左連接:優先顯示左表全部記錄。
#左鏈接:在按照on的條件取到兩張表共同部分的基礎上,保留左表的記錄 select * from employee1 left join department on department.id=employee1.dep_id; select * from department left join employee1 on department.id=employee1.dep_id;
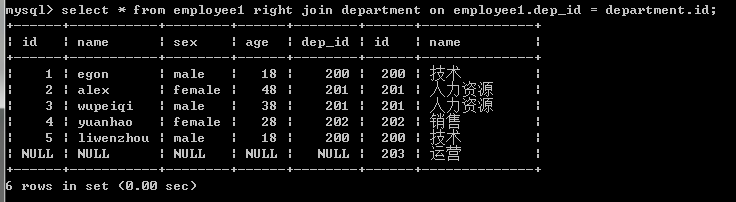
4.右鏈接:優先顯示右表全部記錄。
#右鏈接:在按照on的條件取到兩張表共同部分的基礎上,保留右表的記錄 select * from employee1 right join department on department.id=employee1.dep_id; select * from department right join employee1 on department.id=employee1.dep_id;

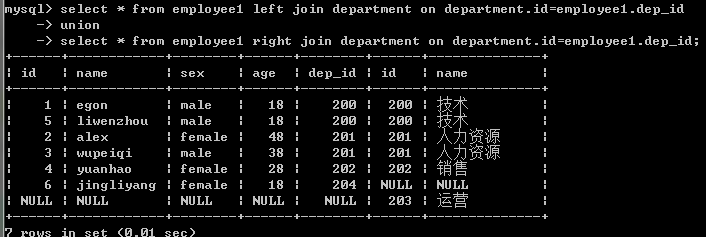
5.全外連接:顯示左右兩個表的全部記錄。
註意:mysql不支持全外連接 full join
強調:mysql可以使用union間接實現全外連接
select * from employee1 left join department on department.id=employee1.dep_id union select * from employee1 right join department on department.id=employee1.dep_id;
三、符合條件連接查詢
示例1:以內連接的方式查詢employee和department表,並且employee表中的age欄位值必須大於25,
即找出公司所有部門中年齡大於25歲的員工
select * from employee1 inner join department on employee1.dep_id=department.id and age>25;
示例2:以內連接的方式查詢employee和department表,並且以age欄位的升序方式顯示
select * from employee1 inner join department on employee1.dep_id=department.id = and age>25 and age>25 order by age asc;
四、子查詢
#1:子查詢是將一個查詢語句嵌套在另一個查詢語句中。 #2:內層查詢語句的查詢結果,可以為外層查詢語句提供查詢條件。 #3:子查詢中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等關鍵字 #4:還可以包含比較運算符:= 、 !=、> 、<等

