
由於在Geometry中,有相關自帶函數和SPATIAL INDEX的性能優化,可以讓某些位置計算的效率提升。以下是幾種計算方法的效果對比。 1. 數據準備 首先創建一個數據表,這是一個店鋪數據表,結構如下: 創建語句: CREATE TABLE `store_geometry` ( `id` in ...
由於在Geometry中,有相關自帶函數和SPATIAL INDEX的性能優化,可以讓某些位置計算的效率提升。以下是幾種計算方法的效果對比。
1. 數據準備
首先創建一個數據表,這是一個店鋪數據表,結構如下:
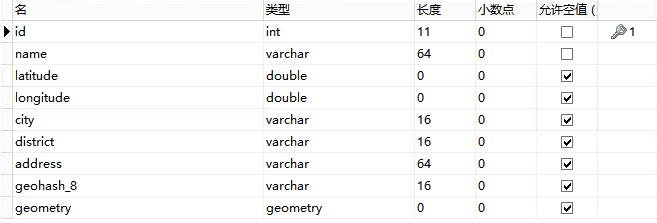
創建語句:
CREATE TABLE `store_geometry` (
`id` int(11) NOT NULL,
`name` varchar(64) NOT NULL,
`latitude` double DEFAULT NULL,
`longitude` double DEFAULT NULL,
`city` varchar(16) DEFAULT NULL,
`district` varchar(16) DEFAULT NULL,
`address` varchar(64) DEFAULT NULL,
`geohash_8` varchar(16) DEFAULT NULL,
`geometry` geometry DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC
然後插入數據,包含id,name,latitude,longitude,city,district,address這些欄位的數值。
原始欄位數值插入後,通過geometry函數計算出geometry欄位的數值,並更新:
UPDATE `store_geometry` SET geometry=geomFromText(CONCAT('POINT(',longitude,' ',latitude,')'))
到此,數據準備工作完成。
2. 對比實例:篩選出在一定矩形範圍內的店鋪
對比時,表內共有100,000條左右的店鋪數據。
矩形範圍:
max_x=121.474243
min_x=121.470724
max_y=31.234504
min_y=31.230229
2.1 方法一:使用經度和緯度欄位判斷是否在此區間內
我們看看對latitude,longitude2個欄位做索引前後的性能對比
先在索引前查詢:
SET @max_x=121.474243;
SET @min_x=121.470724;
SET @max_y=31.234504;
SET @min_y=31.230229;
SELECT * FROM `store_geometry` WHERE longitude BETWEEN @min_x AND @max_x and latitude BETWEEN @min_y AND @max_y;
查詢結果有70條,耗時0.473秒


然後索引後使用相同語句查詢,速度有明顯加快:

2.2 方法二:使用geometry欄位數據和相關幾何計算函數判斷是否在此區間內
同樣的我們先不對geometry欄位創建索引
SET @mbr=geomFromText(CONCAT('POLYGON','((',@min_x,' ',@min_y,',',@max_x,' ',@min_y,',',@max_x,' ',@max_y,',',@min_x,' ',@max_y,',',@min_x,' ',@min_y,'))'));
SELECT * FROM `store_geometry` WHERE st_contains(@mbr, geometry);
查詢結果相同,耗時如下:

然後對geometry創建索引,這裡註意不要用mysql客戶端工具在界面上創建,因為只能創建普通索引,沒有效果。
CREATE SPATIAL INDEX i_geometry ON `store_geometry`(geometry);

然後用相同語句查詢,結果如下:

3.結論
實驗結果很明顯,geometry擴展在進行位置計算時具有性能上的明顯優勢。
| 方法 | 索引 | 查詢耗時(秒) |
| 使用經度和緯度欄位 | no index | 0.473 |
| index | 0.015 | |
| 使用geometry欄位 | no index | 0.092 |
| index | 0.008 |


