
歡迎大家前往 "騰訊雲+社區" ,獲取更多騰訊海量技術實踐乾貨哦~ 本文由 "李躍森" 發表於 "雲+社區專欄" 李躍森, "騰訊雲PostgreSQL" 首席架構師,騰訊資料庫團隊架構師,負責微信支付商戶系統核心資料庫的架構設計和研發,PostgreSQL x2社區核心成員,獲多項國家發明專利。從 ...
歡迎大家前往騰訊雲+社區,獲取更多騰訊海量技術實踐乾貨哦~
李躍森,騰訊雲PostgreSQL首席架構師,騰訊資料庫團隊架構師,負責微信支付商戶系統核心資料庫的架構設計和研發,PostgreSQL-x2社區核心成員,獲多項國家發明專利。從事PG內核開發和架構設計超過10年。
2015年之前,微信支付業務快速發展,需要一款資料庫能夠安全高效的支撐微信支付商戶系統核心業務,這個重任落在了騰訊資料庫團隊自研PostgreSQL上。
2016年7月,騰訊雲對外發佈雲資料庫PostgreSQL,提供騰訊自研的內核優化版和社區版兩個版本,以及提供分散式集群架構(分散式集群內部代號PostgreSQL-XZ)兩種方案。目前雲資料庫PostgreSQL在騰訊大數據平臺、廣點通、騰訊視頻等騰訊多個核心業務中穩定運行。
騰訊自研PostgreSQL分散式集群 PostgreSQL-XZ
騰訊PostgreSQL-XZ是由PostgreSQL-XC社區版本地化而來,能支撐水平擴展資料庫集群。雖然PostgreSQL-XC很強大,但在性能、擴展性、安全、運維方面還是有明顯的瓶頸,而騰訊PostgreSQL經過多年的積累,在這些方面都有較大提升和強化。由於是用於微信支付的核心資料庫,騰訊PostgreSQL被定位為安全、高效,穩定,可靠的資料庫集群。下麵將以騰訊PostgreSQL-XZ為代表介紹騰訊自研PostgreSQL所做的優化和改進。
一.事務管理系統的優化
PostgreSQL-XC在事務管理系統方案本身有一個明顯的缺點,那就是事務管理機制會成為系統的瓶頸,GTM(Global Transaction Manager全局事務管理器)會限制系統的擴展規模。如圖1所示,是每個請求過來CN(Coordinator 協調節點)都會向GTM申請必需的gxid(全局事務ID)和gsnapshot(全局快照)信息,並把這些信息隨著SQL語句本身一起發往DN(Datanode資料庫節點)進行執行。另外,PostgreSQL-XC的管理機制,只有主DN才會獲取的gxid,而備DN沒有自己的gxid,因此無法提供只讀服務,對系統也是不小的浪費。
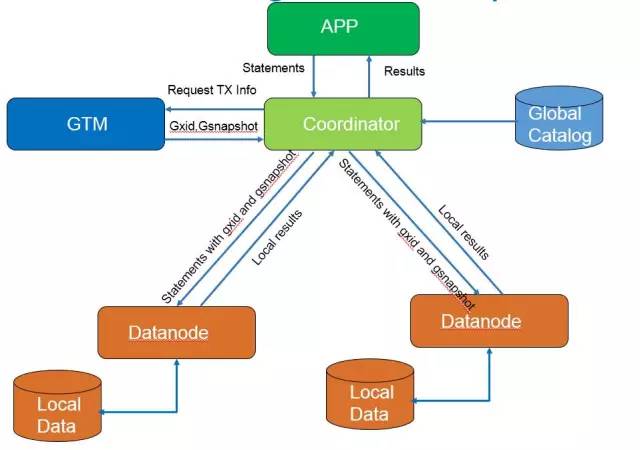
圖1
而騰訊PostgreSQL-XZ改進了事務管理機制,改進後,CN不再從GTM獲取gxid和gsnapshot,每個節點使用自己的本地xid(事務ID)和gsnapshot(快照),如此GTM便不會成為系統的瓶頸;並且,DN備機就還可以提供只讀服務,充分利用系統閑置資源。如圖2,優化後的事務管理系統架構如下:
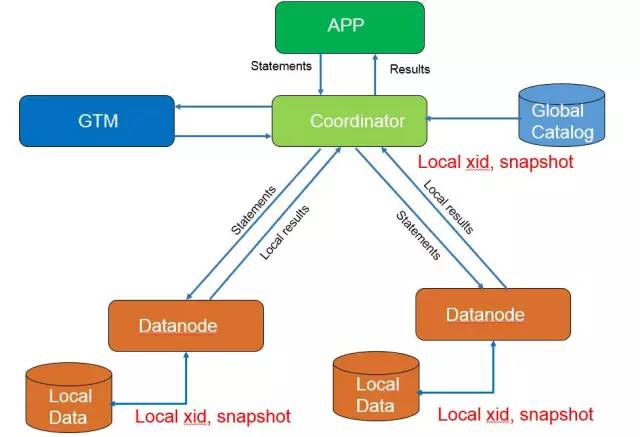
圖2
二.備機只讀實現與優化
當然,事務管理系統的優化為進行備DN只讀提供了基礎,然而原始集群並沒有負載、調度等能力。在這方面,我們也做了大量的創新,總結起來包括:
- 正常CN和只讀CN進行分離。
- 正常CN存儲主用DN的元數據信息
- 只讀CN存儲備用DN的元數據信息
- DN之間使用hot standby(熱備份保護)模式進行日誌同步
通過這些方式,集群可以提供帶有智能負載能力的備DN只讀功能,充分利用系統資源。
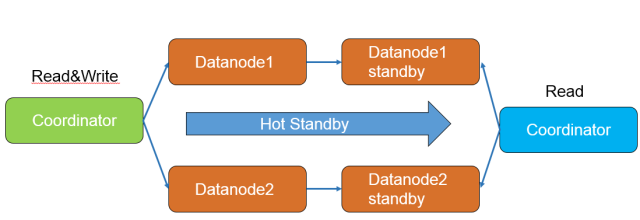
圖3
三.業務最小中斷的擴容方案
業務的快速增長不可避免的需要對資源進行擴容,社區版本的實現使得擴容成本高昂,需要對業務進行長時間的中斷。因為,在社區版本PostgreSQL-XC中,通過 DN=Hash(row) % nofdn的方式決定一條記錄的存儲節點:
也就是說,先對分佈列計算hash值,然後使用這個值對集群中的節點個數取模來決定記錄去哪個節點(如圖4)。
這種方案簡單,但實際應用中需要長時間停機擴容。這是因為,擴容後節點數會變多,數據無法按照原有的分佈邏輯進行讀寫,需要重新分佈節點數據。而再均衡數據需要停機並手工遷移再均衡到各個節點。對於規模較大的交易系統來說,由於原有節點存儲的是海量數據,再均衡過程可能會持續好幾天。相信這是業務完全無法忍受的。
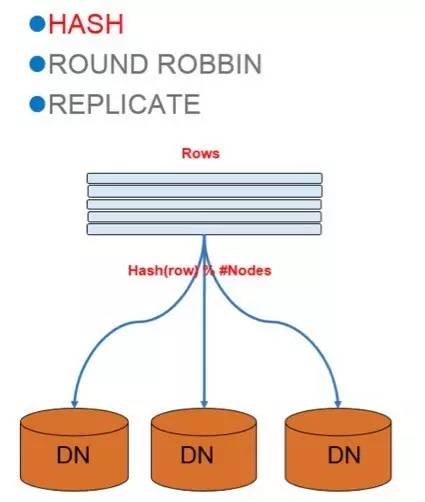
圖4
因此我們引入了一種新的分表方法—sharded table。Shardedtable的數據分佈採用如下(圖5)的方式:
- 引入一個抽象的中間層--shard map。Shard map中每一項存儲shardid和DN的映射關係。
- Sharded table中的每條記錄通過
Hash(row) % #shardmap entry來決定記錄存儲到哪個shardid,通過查詢shardmap的存儲的DN。 - 每個DN上存儲分配到本節點shardid信息,進而進行可見性的判斷。
通過上面的方案,在擴容新加節點時,就只需要把一些shardmap中的shardid映射到新加的節點,並把對應的數據搬遷過去就可以了。擴容也僅僅需要切換shardmap中映射關係的,時間從幾天縮短到幾秒。
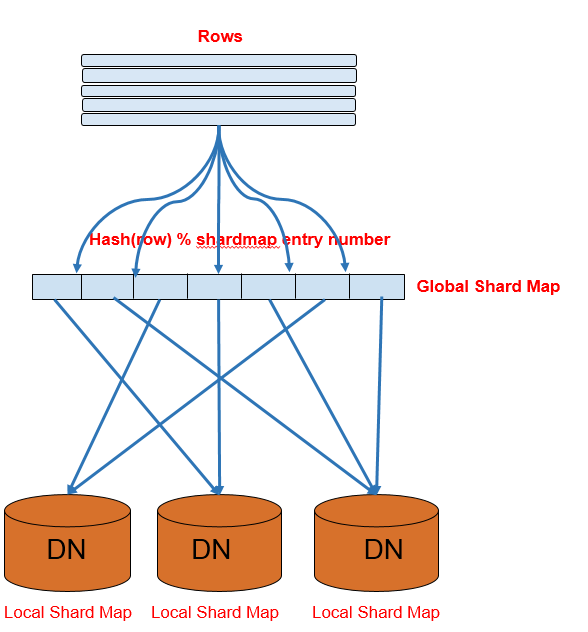
圖5
四.數據傾斜解決方案
數據傾斜是指,在分散式資料庫系統中會因為物理節點、hash或shard分佈原因,導致某些DN物理空間不足,而另外的物理空間剩餘較大。例如,如果以商戶作為分佈key,京東每天的數據量和一個普通電商的數據量肯定是天地差別。可能某個大商戶一個月的數據就會把一個DN的物理空間塞滿,這時系統只有停機擴容一條路。因此我們必須要有一個有效的手段來解決數據傾斜,保證在表數據分佈不均勻時系統仍然能夠高效穩定的運行。
首先我們把系統的DN分為group(如下圖6),每個group裡面:
- 包含一個或者多個DN
- 每個group有一個shardmap
- 在建sharded表時,可以指定存儲的group,也就是要麼存儲在group1,要麼group2
- CN可以訪問所有的group,而且CN上也存儲所有表的訪問方式信息
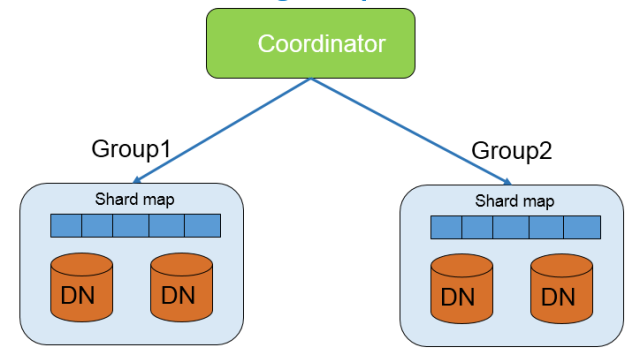
圖6
對於系統中數據量較大用戶進行特別的識別,併為他們創建白名單,使用不同的數據分佈邏輯(如下圖7):普通用戶使用預設的數據分佈邏輯,也就是:
Shardid = Hash(merchantid) % #shardmap
大商戶使用定製的數據分佈邏輯,也就是:
Shardid = Hash(merchantid) % #shardmap + fcreate_timedayoffset from 1970-01-01
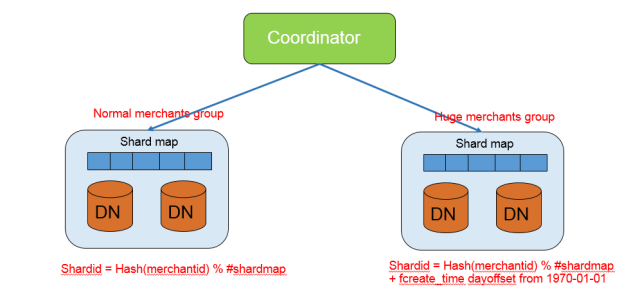
圖7
通過在大商戶group分佈邏輯中加入日期偏移,來實現同一個用戶的數據在group內部多個節點間均勻分佈。從而有效的解決數據分佈不均勻問題。
下麵是一個例子(如下圖8):
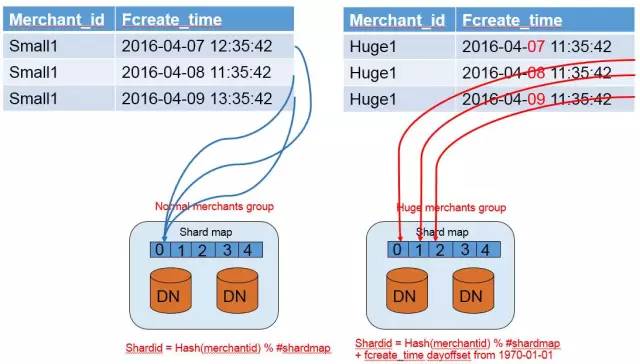
圖8
五.9000W記錄高效排序解決方案
業務在列表查詢場景下會收到如下的查詢SQL:

在微信支付的場景中,某個商戶每天的數據有300W,一個月數據超過9000W條,也就是說PostgreSQL需要面向一個9000W數據級數據進行快速排序,而且業務邏輯要求需要秒級輸出,快速獲取排序結果。
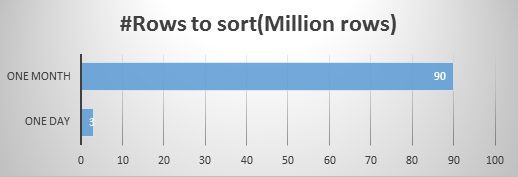
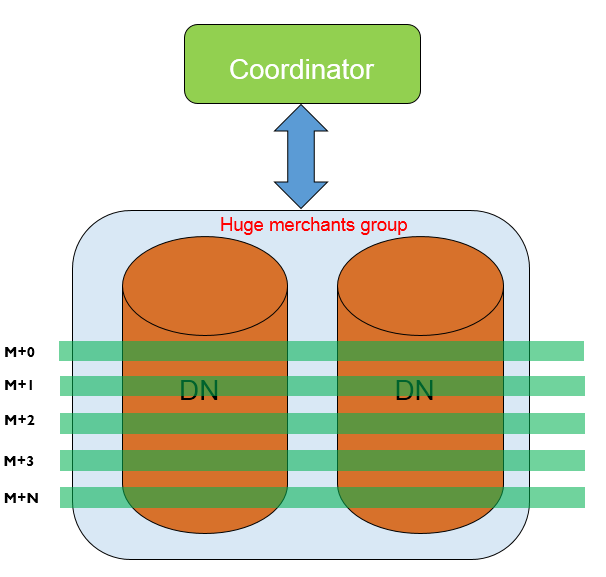
為此,我們提供表定義方案,即建立集群分區表。根據上述需求,可以採用按月分表,即每個月一張表,並對排序欄位ffinish_time建立索引,這樣每個分區進行掃描是可以使用索引。
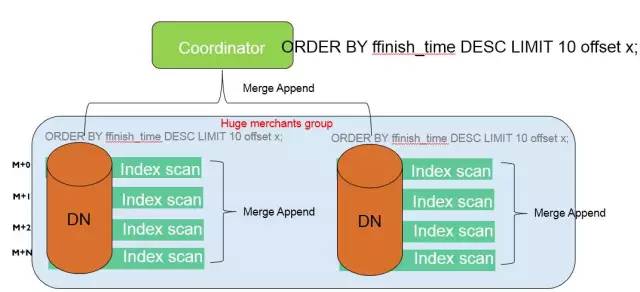
我們再通過一系列執行計劃的優化,CN下推order by和limit offset子句到DN;DN上在執行對應的sql使用使用Merge Append運算元對各個子表執行的結果進行彙總輸出,這個運算元本身會保證輸出是有序的,也就是說對子表進行索引掃描,同時Merge Append又對各個子表的結果進行歸併,進而保證節點本身的結果是排序的。CN對多個DN的結果同樣使用Merge Append進行歸併,保證整個輸出結果是有序的,從而完成整個排序過程。
下麵是我們對排序進行的性能測試結果:
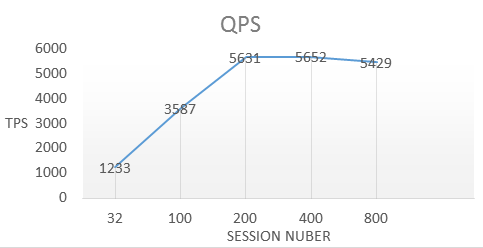
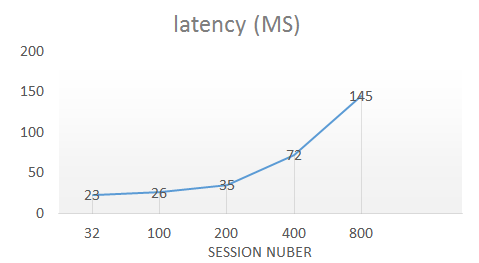
通過在24核CPU,64G記憶體的機型上進行測試,9000W數據的排序在最短可以在25 ms內完成,QPS最高可達5400。
六.並行優化
隨著當前硬體的發展,系統資源越來越豐富,多CPU大記憶體成了系統標配,充分利用這些資源可以有效的提升的處理效率優化性能。騰訊在2014年底開始進行PostgreSQL多核執行優化。
目前PostgreSQL9.6社區版也會包含部分並行化特性,但是沒有我們這邊這麼豐富,下麵介紹下騰訊PostgreSQL並行化的原理和效果:
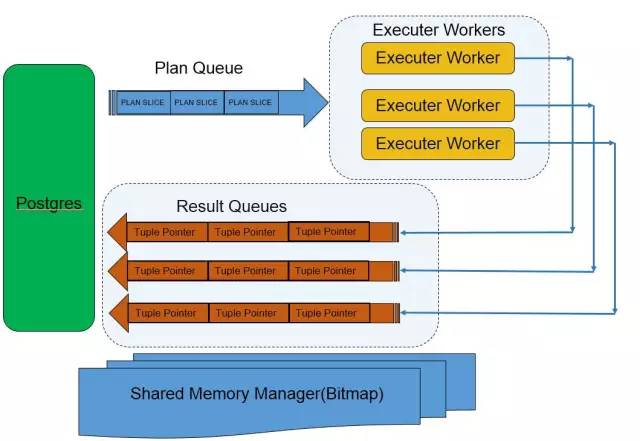
- 系統創建一個全局的共用記憶體管理器,使用bitmap管理演算法進行管理
- 系統啟動時創建一定數據的Executor,這些Executor用來執行執行計劃的碎片
- 系統會創建一個計劃隊列,所有的Executor都會在任務隊列上等待計劃
- 每個Executor對應一個任務結果隊列,Executor在輸出結果時就把結果的指針掛到結果隊列中去
- 計劃隊列,結果隊列,計劃分片執行結果都存放在共用記憶體管理器中,這樣所有的進程都可以訪問到這些結構
- Postgres會話進程在收到sql時,判斷是否可以並行化,併進行任務的分發;在結果隊列中有結果時就讀出返回
我們完成優化的運算元:
- Seqscan
- Hash join
- Nestloop join
- Remote query
- Hash Agg
- Sort Agg
- Append
通過在24核CPU,64G記憶體的機型下測試,各個運算元的優化結果:
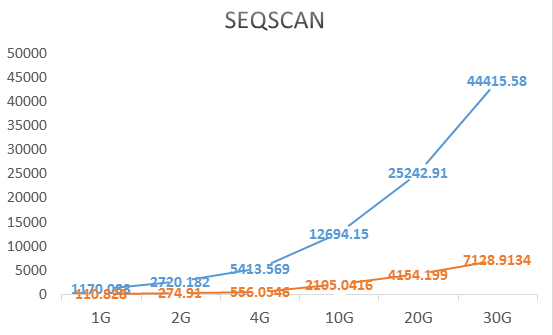
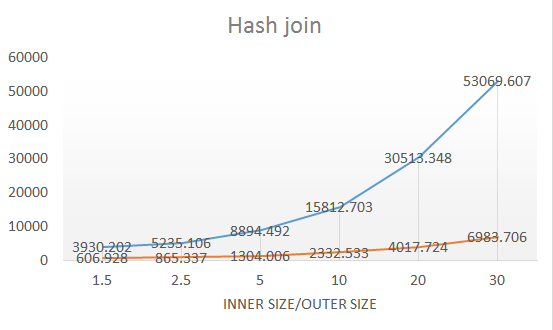
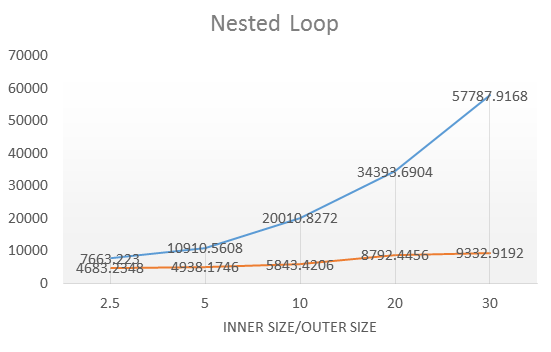
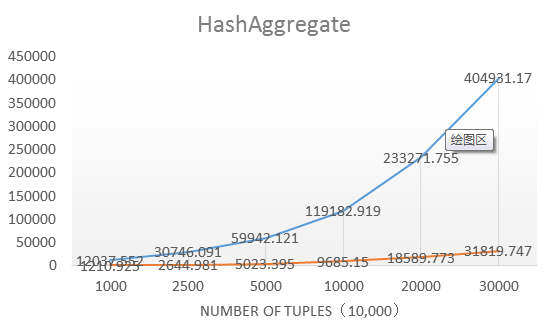
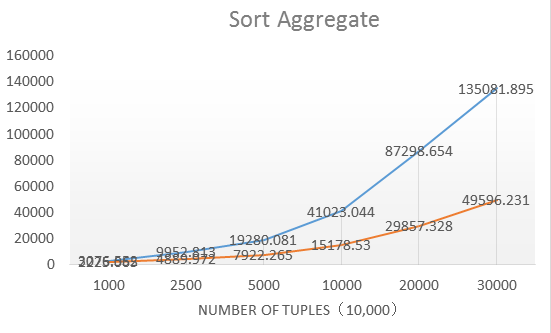
整體來說性能普遍是優化前的10-12倍,優化的效果比較明顯。
七.騰訊PostgreSQL-XZ的兩地三中心容災
兩地三中心容災是金融級資料庫的必備能力,對於金融類業務數據安全是最基本也是最重要訴求,因此我們為了保障高效穩定的數據容災能力,也為PostgreSQL-XZ建設了完善的兩地三中心自動容災能力。具體的兩地三中心部署結構如下:
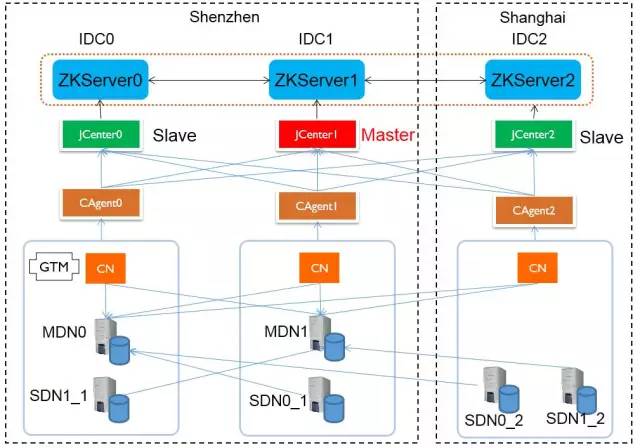
同城節點間採用強同步方式,保障數據強一致;異地採用專網非同步同步。
節點內,每台物理機上部署CAgent,agent收集機器狀態併進行上報,併進行相應的告警和倒換執行功能。
每個IDC至少部署一個JCenter,JCenter負責收集上報每個agent上報的狀態到ZK集群。這麼多個JCenter中只有一個是主用,主用的JCenter除了進行狀態上報還進行故障裁決和倒換。在主用的JCenter異常後,系統通過ZK自動裁決挑選一個備用的JCenter升主。
JCenter和CAgent是兩地三中心的控制和裁決節點。
對於資料庫節點,CN在每個IDC至少部署一個。DN在每個中心部署一個,一個為主,另外兩個並聯作為備機放在主機上,一個為同步備機,另外一個為非同步備機。
在主機故障宕機時,JCenter優先選擇同城的備機升主。
目前,騰訊雲已經提供雲資料庫PostgreSQL的內測使用,並將提供內核優化版和社區版兩個版本來滿足更多客戶的要求。
問答
如何記錄PostgreSQL查詢?
相關閱讀
PostgreSQL新手入門
PostgreSQL配置優化
PostgreSQL主備環境搭建
【每日課程推薦】機器學習實戰!快速入門線上廣告業務及CTR相應知識
此文已由作者授權騰訊雲+社區發佈,更多原文請點擊
搜索關註公眾號「雲加社區」,第一時間獲取技術乾貨,關註後回覆1024 送你一份技術課程大禮包!
海量技術實踐經驗,盡在雲加社區!


