
30行代碼奉上!(MNIST手寫數字的識別,識別率大約在91%,簡單嘗試的一個程式,小玩具而已) 其中x作為輸入是一個1x768的向量,然後就是經過權重和偏食,就得到10個輸出,然後用softmax()進行預測值的輸出。 此外y_作為真值,要用到一個占位符。 主要用到的tensorflow的函數有 ...
30行代碼奉上!(MNIST手寫數字的識別,識別率大約在91%,簡單嘗試的一個程式,小玩具而已)
1 import tensorflow.examples.tutorials.mnist.input_data as input_data 2 import tensorflow as tf 3 mnist = input_data.read_data_sets('/temp/', one_hot=True) 4 5 #設置 6 x = tf.placeholder(tf.float32,[None,784]) 7 W = tf.Variable(tf.zeros([784,10])) 8 b = tf.Variable(tf.zeros([10])) 9 #預測值 10 y = tf.nn.softmax(tf.matmul(x,W)+b) 11 #真值 12 y_ = tf.placeholder(tf.float32,[None,10]) 13 #交叉熵 14 cross_entropy = -tf.reduce_sum(y_*tf.log(y)) 15 16 #使用優化器 17 train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) 18 #初始化變數 19 init = tf.initialize_all_variables() 20 #創建對話 21 sess = tf.Session() 22 sess.run(init) 23 24 25 for i in range(1000): 26 batch_xs,batch_ys = mnist.train.next_batch(100) 27 sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys}) 28 29 correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) 30 accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) 31 print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
1 import tensorflow.examples.tutorials.mnist.input_data as input_data 2 import tensorflow as tf 3 mnist = input_data.read_data_sets('/temp/', one_hot=True)
1~3行,主要的工作是引入tensorflow模塊,並且下載MNIST數據集,這是tensorflow自帶的下載器,可以自動下載數據集,我們主要重心不在這,所以就這樣簡單代過。
#設置 6 x = tf.placeholder(tf.float32,[None,784]) 7 W = tf.Variable(tf.zeros([784,10])) 8 b = tf.Variable(tf.zeros([10])) 9 #預測值 10 y = tf.nn.softmax(tf.matmul(x,W)+b) 11 #真值 12 y_ = tf.placeholder(tf.float32,[None,10])
6~12行
首先是設置輸入輸出,還有精確值作為學習目標,此外還有權重和偏置,就這樣構建一個計算圖,圖的樣子大概是這樣的:

其中x作為輸入是一個1x768的向量,然後就是經過權重和偏食,就得到10個輸出,然後用softmax()進行預測值的輸出。
此外y_作為真值,要用到一個占位符。
主要用到的tensorflow的函數有
tf.placeholder 設置一個占位符,用於設置輸入
tf.Variable 設置一個變數,用於設置權重和偏置
tf.nn.softmax softmax回歸函數
tf.matmul 實現矩陣相乘
13 #交叉熵
14 cross_entropy = -tf.reduce_sum(y_*tf.log(y))
15
16 #使用優化器
17 train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
18 #初始化變數
19 init = tf.initialize_all_variables()
20 #創建對話
21 sess = tf.Session()
22 sess.run(init)
使用交叉熵作為誤差評判標準,並以此來實現隨機梯度下降。交叉熵函數公式如下:
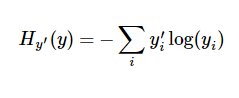
這裡使用了tensorflow的函數:
tf.reduce_sum 求和
tf.log 求對數
17行就是創建一個優化器,使用隨機梯度下降的方法並根據交叉熵進行網路權重和偏置的優化訓練。這裡使用的參數是學習率,設為0.01。
tensorflow函數:
tf.train.GradientDescentOptimizer(learnrate) 創建一個優化器對象,使用的是隨機梯度下降的方法,參數可以設置學習率
tf.train.GradientDescentOptimizer對象的minimize()方法 指定損失函數才能進行優化
19~22行是前面設置的變數的初始化工作,這裡需要創建一個Session對話,tensorflow所有運算操作都是需要Session對話來進行的,此外還需要
對所有變數初始化。
tensorflow函數:
tf.initialize_all_variables() 創建一個初始化所有變數的對象
tf.Session() 創建一個Session對話
sess.run() Session對話指定執行操作
25 for i in range(1000): 26 batch_xs,batch_ys = mnist.train.next_batch(100) 27 sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys}) 28 29 correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) 30 accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) 31 print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
25~27行就是訓練過程,一共迭代一千次,每次送入小批量一百個數據,這裡使用數據集的函數
mnist.train.next_batch 可以返回一個小批數據集
然後就是Session對話的run()函數,指定優化器的運行,還有feed_dict送入數據字典的指定,上述代碼指定輸出小批量的數據。
29~31行就是輸出識別結果,其中用到tensorflow函數:
tf.argmax 返回的是vector中的最大值的索引號
tf.equal 判斷是否相等
tf.reduce_mean 求均值
tf.cast 類型轉換
輸出:0.9187
表示識別率達到91.87%,但是沒什麼卵用,還是很糟糕的結果,模型太簡單了,不過通過這樣的學習,可以大概基礎地入門tensorflow的坑。
接下來我將繼續深入tensorflow的坑!


