
本次抓取貓眼電影Top100榜所用到的知識點: 1. python requests庫 2. 正則表達式 3. csv模塊 4. 多進程 正文 目標站點分析 通過對目標站點的分析, 來確定網頁結構, 進一步確定具體的抓取方式. 1. 瀏覽器打開貓眼電影首頁, 點擊"榜單", 點擊"Top100榜", ...
本次抓取貓眼電影Top100榜所用到的知識點:
1. python requests庫
2. 正則表達式
3. csv模塊
4. 多進程
正文
目標站點分析
通過對目標站點的分析, 來確定網頁結構, 進一步確定具體的抓取方式.
1. 瀏覽器打開貓眼電影首頁, 點擊"榜單", 點擊"Top100榜", 即可看到目標頁面.
2. 瀏覽網頁, 滾動到下方發現有分頁, 切換到第2頁, 發現: URL從 http://maoyan.com/board/4變換到http://maoyan.com/board/4?offset=10, 多次切換頁碼offset都有改變, 可以確定的是通過改變URL的offset參數來生成分頁列表.
項目流程框架:
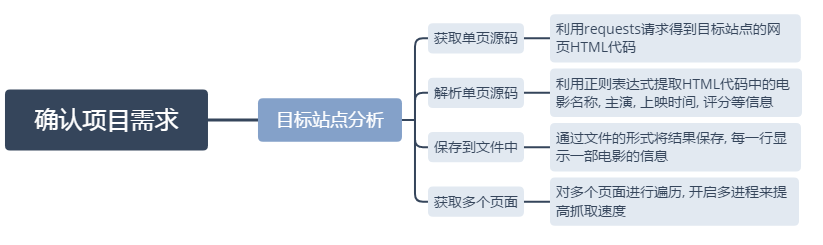
獲取單頁源碼
1 #抓取貓眼電影TOP100榜 2 import requests 3 import time 4 from requests.exceptions import RequestException 5 def get_one_page(): 6 '''獲取單頁源碼''' 7 try: 8 url = "http://maoyan.com/board/4?offset={0}".format(0) 9 headers = { 10 "User-Agent":"Mozilla/5.0(WindowsNT6.3;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/68.0.3440.106Safari/537.36" 11 } 12 res = requests.get(url, headers=headers) 13 # 判斷響應是否成功,若成功列印響應內容,否則返回None 14 if res.status_code == 200: 15 print(res.text) 16 return None 17 except RequestException: 18 return None 19 def main(): 20 get_one_page() 21 if __name__ == '__main__': 22 main() 23 time.sleep(1)
執行即可得到網頁源碼, 那麼下一步就是解析源碼了
解析單頁源碼
導入正則表達式re模塊, 對代碼進行解析, 得到想要的信息.
1 import re 2 3 def parse_one_page(html): 4 '''解析單頁源碼''' 5 pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime' 6 + '.*?>(.*?)</p>.*?score.*?integer">(.*?)</i>.*?>(.*?)</i>.*?</dd>',re.S) 7 items = re.findall(pattern,html) 8 print(items) 9 #採用遍歷的方式提取信息 10 for item in items: 11 yield { 12 'rank' :item[0], 13 'title':item[1], 14 'actor':item[2].strip()[3:] if len(item[2])>3 else '', #判斷是否大於3個字元 15 'time' :item[3].strip()[5:] if len(item[3])>5 else '', 16 'score':item[4] + item[5] 17 } 18 def main(): 19 html = get_one_page() 20 for item in parse_one_page(html): 21 print(item) 22 23 if __name__ == '__main__': 24 main() 25 time.sleep(1)
提取出信息之後, 那麼下一步就是保存到文件
保存到文件中
這裡採用兩種方式, 一種是保存到text文件, 另一種是保存到csv文件中, 根據需要選擇其一即可.
1. 保存到text文件
1 import json 2 3 def write_to_textfile(content): 4 '''寫入到text文件中''' 5 with open("MovieResult.text",'a',encoding='utf-8') as f: 6 #利用json.dumps()方法將字典序列化,並將ensure_ascii參數設置為False,保證結果是中文而不是Unicode碼. 7 f.write(json.dumps(content,ensure_ascii=False) + "\n") 8 f.close() 9 def main(): 10 html = get_one_page() 11 for item in parse_one_page(html): 12 write_to_textfile(item) 13 14 if __name__ == '__main__': 15 main() 16 time.sleep(1)
2. 保存到CSV文件
其文件以純文本的形式存儲表格數據
1 import csv 2 def write_to_csvfile(content): 3 '''寫入到csv文件中''' 4 with open("MovieResult.csv",'a',encoding='gb18030',newline='') as f: 5 # 將欄位名傳入列表 6 fieldnames = ["rank", "title", "actor", "time", "score"] 7 #將欄位名傳給Dictwriter來初始化一個字典寫入對象 8 writer = csv.DictWriter(f,fieldnames=fieldnames) 9 #調用writeheader方法寫入欄位名 10 writer.writeheader() 11 writer.writerows(content) 12 f.close() 13 def main(): 14 html = get_one_page() 15 rows = [] 16 for item in parse_one_page(html): 17 #write_to_textfile(item) 18 rows.append(item) 19 write_to_csvfile(rows) 20 if __name__ == '__main__': 21 main() 22 time.sleep(1)
單頁的信息已經提取出, 接著就是提取多個頁面的信息
獲取多個頁面
1. 普通方法抓取
1 def main(offset): 2 url = "http://maoyan.com/board/4?offset={0}".format(offset) 3 html = get_one_page(url) 4 rows = [] 5 for item in parse_one_page(html): 6 #write_to_textfile(item) 7 rows.append(item) 8 write_to_csvfile(rows) 9 if __name__ == '__main__': 10 #通過遍歷寫入TOP100信息 11 for i in range(10): 12 main(offset=i * 10) 13 time.sleep(1)
2. 多進程抓取
1 from multiprocessing import Pool 2 3 if __name__ == '__main__': 4 # 將欄位名傳入列表 5 fieldnames = ["rank", "title", "actor", "time", "score"] 6 write_to_csvField(fieldnames) 7 pool = Pool() 8 #map方法會把每個元素當做函數的參數,創建一個個進程,在進程池中運行. 9 pool.map(main,[i*10 for i in range(10)])
完整代碼
1 #抓取貓眼電影TOP100榜 2 from multiprocessing import Pool 3 from requests.exceptions import RequestException 4 import requests 5 import json 6 import time 7 import csv 8 import re 9 def get_one_page(url): 10 '''獲取單頁源碼''' 11 try: 12 headers = { 13 "User-Agent":"Mozilla/5.0(WindowsNT6.3;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/68.0.3440.106Safari/537.36" 14 } 15 res = requests.get(url, headers=headers) 16 # 判斷響應是否成功,若成功列印響應內容,否則返回None 17 if res.status_code == 200: 18 return res.text 19 return None 20 except RequestException: 21 return None 22 def parse_one_page(html): 23 '''解析單頁源碼''' 24 pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime' 25 + '.*?>(.*?)</p>.*?score.*?integer">(.*?)</i>.*?>(.*?)</i>.*?</dd>',re.S) 26 items = re.findall(pattern,html) 27 #採用遍歷的方式提取信息 28 for item in items: 29 yield { 30 'rank' :item[0], 31 'title':item[1], 32 'actor':item[2].strip()[3:] if len(item[2])>3 else '', #判斷是否大於3個字元 33 'time' :item[3].strip()[5:] if len(item[3])>5 else '', 34 'score':item[4] + item[5] 35 } 36 37 def write_to_textfile(content): 38 '''寫入text文件''' 39 with open("MovieResult.text",'a',encoding='utf-8') as f: 40 #利用json.dumps()方法將字典序列化,並將ensure_ascii參數設置為False,保證結果是中文而不是Unicode碼. 41 f.write(json.dumps(content,ensure_ascii=False) + "\n") 42 f.close() 43 44 def write_to_csvField(fieldnames): 45 '''寫入csv文件欄位''' 46 with open("MovieResult.csv", 'a', encoding='gb18030', newline='') as f: 47 #將欄位名傳給Dictwriter來初始化一個字典寫入對象 48 writer = csv.DictWriter(f,fieldnames=fieldnames) 49 #調用writeheader方法寫入欄位名 50 writer.writeheader() 51 def write_to_csvRows(content,fieldnames): 52 '''寫入csv文件內容''' 53 with open("MovieResult.csv",'a',encoding='gb18030',newline='') as f: 54 #將欄位名傳給Dictwriter來初始化一個字典寫入對象 55 writer = csv.DictWriter(f,fieldnames=fieldnames) 56 #調用writeheader方法寫入欄位名 57 #writer.writeheader() ###這裡寫入欄位的話會造成在抓取多個時重覆. 58 writer.writerows(content) 59 f.close() 60 61 def main(offset): 62 fieldnames = ["rank", "title", "actor", "time", "score"] 63 url = "http://maoyan.com/board/4?offset={0}".format(offset) 64 html = get_one_page(url) 65 rows = [] 66 for item in parse_one_page(html): 67 #write_to_textfile(item) 68 rows.append(item) 69 write_to_csvRows(rows,fieldnames) 70 71 if __name__ == '__main__': 72 # 將欄位名傳入列表 73 fieldnames = ["rank", "title", "actor", "time", "score"] 74 write_to_csvField(fieldnames) 75 # #通過遍歷寫入TOP100信息 76 # for i in range(10): 77 # main(offset=i * 10,fieldnames=fieldnames) 78 # time.sleep(1) 79 pool = Pool() 80 #map方法會把每個元素當做函數的參數,創建一個個進程,在進程池中運行. 81 pool.map(main,[i*10 for i in range(10)])
效果展示:
最終採用寫入csv文件的方式.



