
最近看到OVS用戶態的代碼,在接收內核態信息的時候,使用了Epoll多路復用機制,對其十分不解,於是從網上找了一些資料,學習了一下《UNIX網路變成捲1:套接字聯網API》這本書對應的章節,網上雖然關於該主題的博文很多,並且講解的很詳細,但是在這裡還是做一個學習筆記,記錄一下自己的想法。 IO模型 ...
最近看到OVS用戶態的代碼,在接收內核態信息的時候,使用了Epoll多路復用機制,對其十分不解,於是從網上找了一些資料,學習了一下《UNIX網路變成捲1:套接字聯網API》這本書對應的章節,網上雖然關於該主題的博文很多,並且講解的很詳細,但是在這裡還是做一個學習筆記,記錄一下自己的想法。
IO模型
在《UNIX網路變成捲1:套接字聯網API》這本書中,提到了五種I/O模型,分別為:阻塞式I/O、非阻塞式I/O、I/O復用(Epoll、select都是一種I/O復用機制),信息驅動式I/O、非同步I/O,下麵具體的一一介紹。
阻塞式I/O模型
阻塞,顧名思義,當進程在等待數據時,若該數據一直沒有產生,則該進程將一直等待,直到等待的數據產生為止,這個過程中進程的狀態是阻塞的。
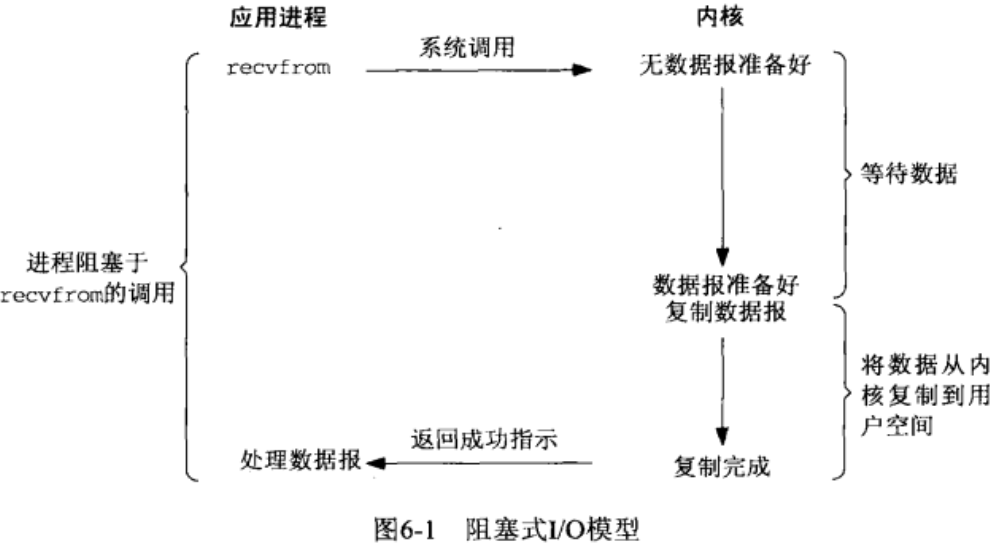
如上圖所示,在linux中,用戶態進程調用recvfrom系統調用接收數據,當前內核中並沒有準備好數據,該用戶態進程將一直在此等待,不會進行其他的操作,待內核態準備好數據,將數據從內核態拷貝到用戶空間記憶體,然後recvfrom返回成功的指示,此時用戶態進行才解除阻塞的狀態,處理收到的數據。
從上述過程可以看出,用戶態接收內核態數據的時候,主要有兩個過程:內核態獲得數據-->將數據從內核態的記憶體空間中複製到用戶態進程的緩衝區中
非阻塞式I/O模型
在非阻塞式I/O模型中,當進程等待內核的數據,而當該數據未到達的時候,進程會不斷詢問內核,直到內核准備好數據。

如上圖,用戶態進程調用recvfrom接收數據,當前並沒有數據報文產生,此時recvfrom返回EWOULDBLOCK,用戶態進程會一直調用recvfrom詢問內核,待內核准備好數據的時候,之後用戶態進程不再詢問內核,待數據從內核覆制到用戶空間,recvfrom成功返回,用戶態進程開始處理數據。
需要註意的是,當數據從內核覆制到用戶空間中的這一段時間中,用戶態進程是處於阻塞的狀態的。
非阻塞式I/O模型,個人覺得這個名字可能有點混淆,並不是和阻塞式模型是完全對立的,不是說進程等不到數據,就去做別的事情,恰恰進程這個時候一直在原地等待數據的到來,與阻塞式模型不同的是,非阻塞相當於進程一直在敲門問“數據好了麽,快給我”,然後房門後的人說“沒有準備好,請稍後!”,這個過程是一種輪詢的狀態,而阻塞式是佛系的態度,敲了一次門,房門後的人沒有給任何回應,於是就去睡覺,啥都不做,直到房門後的人做出響應叫醒他,進程才去做下一步動作。
I/O復用模型
在ovs的用戶態源碼里,就用到了I/O復用模型,在電腦網路裡面,有很多關於“復用”的用法,比如多路復用,意思就是本來一條鏈路上一次只能傳輸一個數據流,如果要實現兩個源之間多條數據流同時傳輸,那就得需要多條鏈路了,但是復用技術可以通過將一條鏈路劃分頻率,或者劃分傳輸的時間,使得一條鏈路上可以同時傳輸多條數據流。

套用到I/O復用模型上,可以對應到如下應用場景:如果一個進程需要等到多種不同的消息,那麼一般的做法就是開啟多條線程,每個線程接收一類消息,如果每個線程都是採用阻塞式I/O模型,那麼每個線程在消息未產生的時候就會阻塞,也就是說在多線程中使用阻塞式I/O。I/O復用就是基於上述的場景中,無需採用多線程監聽消息的方式,進程直接監聽所有的消息類型,這其中就涉及到select、poll、epoll等不同的方法。
如上圖所示,用戶態進程採用select的方法,通過select可以等待多個不同類型的消息,如果其中有一個類型的消息準備好,則select會返回信息,然後用戶態進程調用recvfrom接收數據。
可以將select復用機制看作是一個描述符集合的管理,進程通過向這個集合中放入不同的描述符,用來等待不同的消息產生,然後通過select統一的進行管理,讓其可以同時等待這個集合中任意一個事件的產生。
I/O復用和阻塞式I/O很相似,不同的是,I/O復用等待多類事件,阻塞式I/O只等待一類事件,另外,在I/O復用中,會產生兩個系統調用(如上圖,select和recvfrom),而阻塞式I/O只產生一個系統調用。那麼這就涉及到具體的性能問題,當只存在一類事件的時候,使用阻塞式I/O模型的性能會更好,當存在多種不同類型的事件時,I/O復用的性能要好的多,因為阻塞式I/O模型只能監聽一類事件,所以這個時候需要使用多線程進行處理。
信號驅動式I/O模型
在信號驅動式I/O模型中,與阻塞式和非阻塞式有了一個本質的區別,那就是用戶態進程不再等待內核態的數據準備好,直接可以去做別的事情。

如上圖所示,當需要等待數據的時候,首先用戶態會向內核發送一個信號,告訴內核我要什麼數據,然後用戶態就不管了,做別的事情去了,而當內核態中的數據準備好之後,內核立馬發給用戶態一個信號,說”數據準備好了,快來查收“,用戶態進程收到之後,立馬調用recvfrom,等待數據從內核空間複製到用戶空間,待完成之後recvfrom返回成功指示,用戶態進程才處理別的事情。
通過上面的圖,可以看出信號驅動式I/O模型有種非同步操作的趕腳,但是在將數據從內核覆制到用戶空間這段時間內用戶態進程是阻塞的
非同步I/O模型
非同步I/O模型相對於信號驅動式I/O模型就更徹底了。
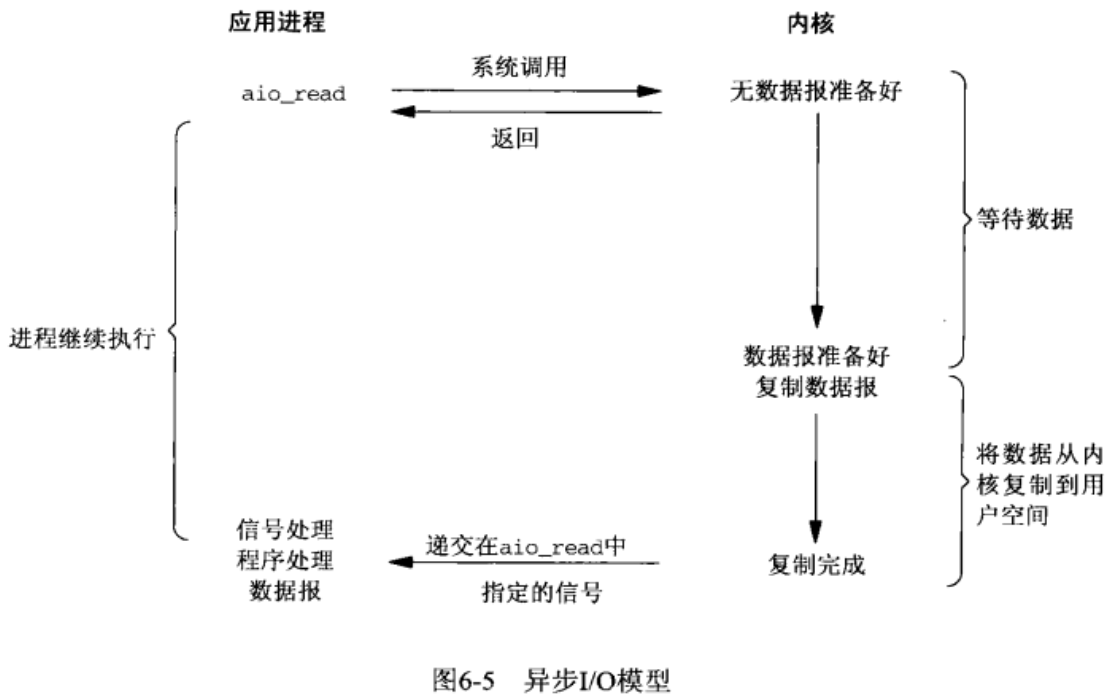
如上圖,首先用戶態進程告訴內核態需要什麼數據(上圖中通過aio_read),然後用戶態進程就不管了,做別的事情,內核等待用戶態需要的數據準備好,然後將數據複製到用戶空間,此時才告訴用戶態進程,”數據都已經準備好,請查收“,然後用戶態進程直接處理用戶空間的數據。
在複製數據到用戶空間這個時間段內,用戶態進程也是不阻塞的
同步I/O
《UNIX網路變成捲1:套接字聯網API》這本書中,並沒有把同步I/O作為一種單獨的I/O模型來說明,在沒有閱讀這些資料之前,我一直認為阻塞式I/O等同於同步I/O,非阻塞式I/O等同於非同步I/O,可見不能單純的通過字面意思就進行判斷。
通過對上述幾種I/O模型的描述中,可以得到一個結論:阻塞式I/O、非阻塞式I/O、I/O復用模型是同步I/O模型,因為在等待數據的過程中,這三種模型中的進程都沒有去做別的事情,即便是非阻塞式的輪詢,也可以看作是一種同步。
同時書中也認為信號驅動式I/O模型是同步I/O,書中說到:POSIX將同步IO操作定義為“導致請求進程阻塞,直到I/O操作完成”,而書中認為在信號驅動式I/O模型中等待數據的那段時間不算是真正的I/O操作(因為沒有調用I/O相關的系統調用),而數據從內核覆制到用戶空間才是真正的I/O操作(這個時候調用了recvfrom系統調用)。
I/O模型比較
書中的這張圖表述的非常清楚,從等待數據和數據複製這兩個時間段,指出了不同I/O模型的區別,這裡不再贅述。

總結
從網上看了很多資料,不同的博主對這五個模型總結的情況不同,無一例外,基本都採用一個生活場景來描述他們的不同,但是我個人覺得有些場景描述太過簡單,沒有將不同模型的區別描述完全,在這裡我也舉一個生活中的場景作為總結,當然這隻是我自己的想法,不妥之處評論區可以指出。
我們去餐廳吃飯,會經過以下幾個步驟:首先根據菜單點菜,然後等待廚房準備好,接著服務員上菜。在這個場景中,等待廚房準備菜餚等同於等待數據,服務員上菜等同於將數據從內核覆制到用戶空間,你就是用戶態進程了,服務員和飯店看作是內核態的進程。
阻塞式I/O模型:只點一個菜,然後在餐桌上開始等待,在這個過程中什麼事都不幹,等服務員把菜上到桌子上之後才開始大快朵頤。
非阻塞式I/O模型:只點一個菜,然後開始等待,啥事都不做,等了一會兒然後就去問服務員,“我的菜好了嗎?”,沒好接著等待,過了一會兒然後又跑去問....重覆這個過程,直到服務員說“親,你的菜好了,我現在給您送桌上去”,然後你坐在桌子上,等待服務員把飯菜送到你的餐桌上,才開始吃飯。
I/O復用模型:你點了很多菜,然後開始等待,某個時刻其中一個菜或者多個菜廚房裡同時好了,服務員跑過來說,“親,您的有些菜好了,要現在上桌麽?”, 你回答,現在就上,於是服務員上一個菜(服務員一次只能上一個菜),你就吃完一個,上一個你就吃完一個。。。
信號驅動式I/O模型:只點一個菜,然後給服務員留下手機,告訴他菜準備好了打個電話給你,先不要上菜,然後你就出去玩耍了,等到菜好了,服務員手機通知你,你立馬回到了餐廳,對服務員說“你現在可以上菜了”,於是你在餐桌上等待服務員把菜送上來,然後吃飯。
非同步I/O模型:只點一個菜,然後給服務員留下手機,告訴他菜準備好了先上菜,菜上桌了打電話給你,然後你就出去玩耍了,等到菜上桌了,服務員手機通知你,你立馬回到了餐桌,開始吃飯。
參考資料
UNIX網路變成捲1:套接字聯網API
網路IO之阻塞、非阻塞、同步、非同步總結
IO - 同步,非同步,阻塞,非阻塞 (亡羊補牢篇)
作者:yearsj
轉載請註明出處:https://www.cnblogs.com/yearsj/p/9630440.html
segmentfault對應博文:https://segmentfault.com/a/1190000016359495


