
前言 requests模塊,也就是老污龜,為啥叫它老污龜呢,因為這個官網上的logo就是這隻污龜,接下來就是學習它了。 一、環境安裝 1.用pip安裝requests模塊 >>pip install requests 二、get請求 1.導入requests後 ...
前言
requests模塊,也就是老污龜,為啥叫它老污龜呢,因為這個官網上的logo就是這隻污龜,接下來就是學習它了。
一、環境安裝
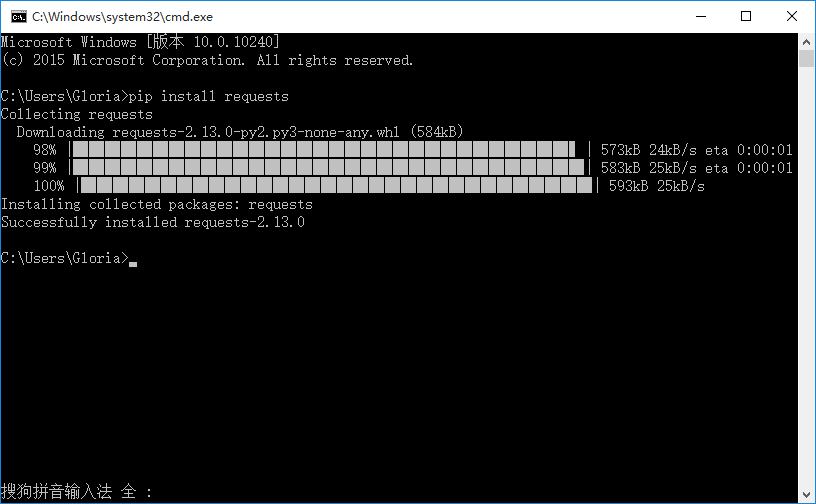
1.用pip安裝requests模塊
>>pip install requests
二、get請求
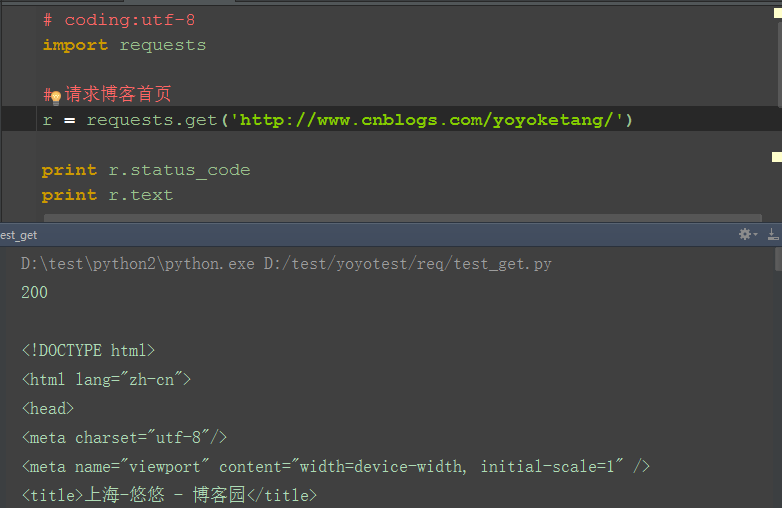
1.導入requests後,用get方法就能直接訪問url地址,如:http://www.cnblogs.com/yoyoketang/,看起來是不是很酷
2.這裡的r也就是response,請求後的返回值,可以調用response里的status_code方法查看狀態碼
3.狀態碼200只能說明這個介面訪問的伺服器地址是對的,並不能說明功能OK,一般要查看響應的內容,r.text是返迴文本信息
三、params
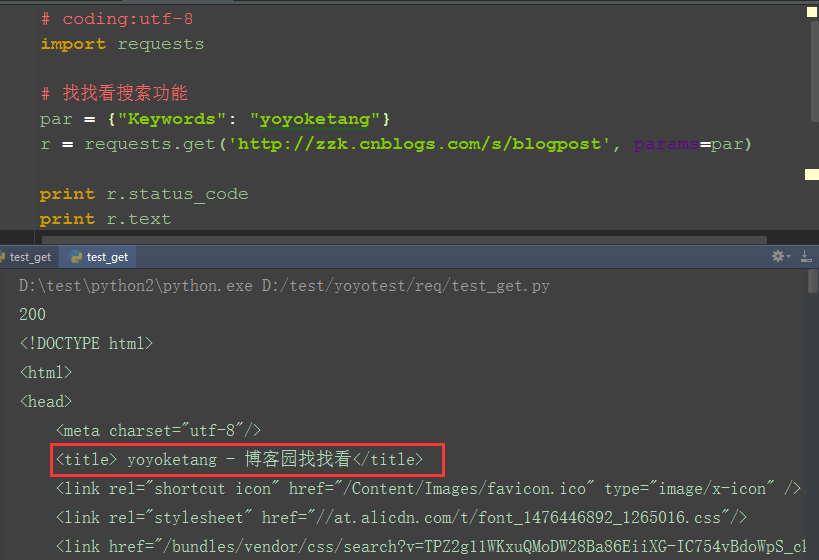
1.再發一個帶參數的get請求,如在博客園搜索:yoyoketang,url地址為:http://zzk.cnblogs.com/s/blogpost?Keywords=yoyoketang
2.請求參數:Keywords=yoyoketang,可以以字典的形式傳參:{"Keywords": "yoyoketang"}
3.多個參數格式:{"key1": "value1", "key2": "value2", "key3": "value3"}
四、content
1.百度首頁如果用r.text會發現獲取到的內容有亂碼,因為百度首頁響應內容是gzip壓縮的(非text文本)
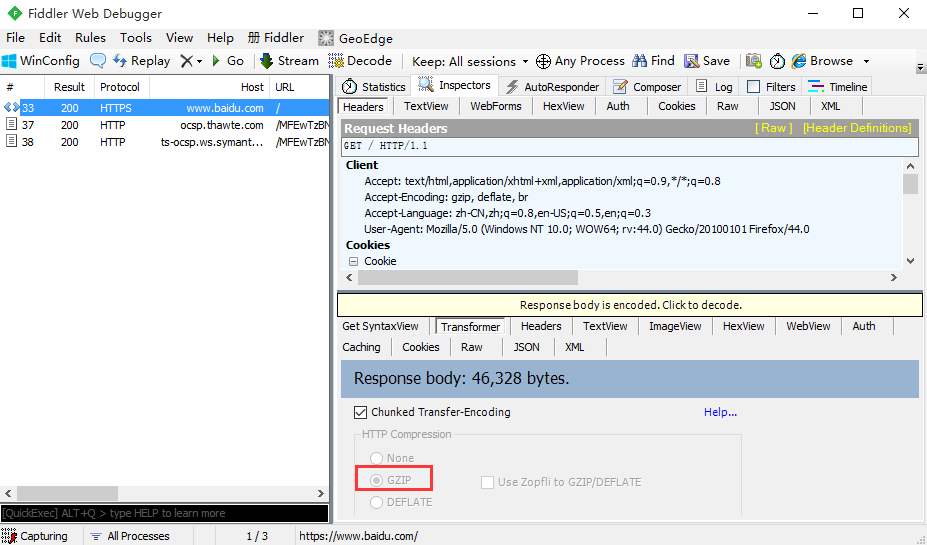
2.如果是在fiddler工具亂碼,是可以點擊後解碼的,在代碼裡面可以用r.content這個方法,content會自動解碼 gzip 和deflate壓縮
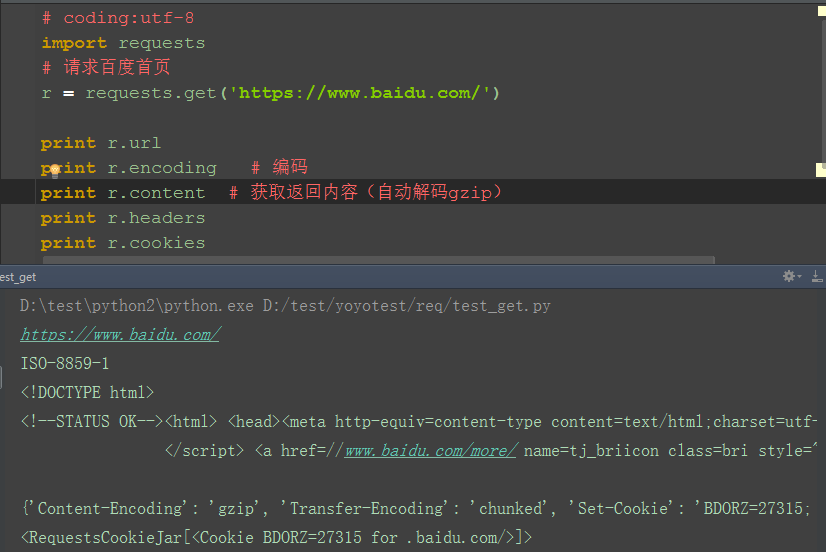
五、response
1.response的返回內容還有其它更多信息
-- r.status_code #響應狀態碼
-- r.content #位元組方式的響應體,會自動為你解碼 gzip 和 deflate 壓縮
-- r.headers #以字典對象存儲伺服器響應頭,但是這個字典比較特殊,字典鍵不區分大小寫,若鍵不存在則返回None
-- r.json() #Requests中內置的JSON解碼器
-- r.url # 獲取url
-- r.encoding # 編碼格式
-- r.cookies # 獲取cookie
-- r.raw #返回原始響應體
-- r.text #字元串方式的響應體,會自動根據響應頭部的字元編碼進行解碼
-- r.raise_for_status() #失敗請求(非200響應)拋出異常


