
一:個人看法 Mysql Group Replication 隨著5.7發佈3年了。作為技術愛好者。mgr 是繼 oracle database rac 之後。 又一個“真正” 的群集,怎麼做到“真正” ? 怎麼做到解決複製的延遲,怎麼做到強數據一致性?基於全局的GTID就能解決? 圍繞這些問題進行 ...
一:個人看法
Mysql Group Replication 隨著5.7發佈3年了。作為技術愛好者。mgr 是繼 oracle database rac 之後。
又一個“真正” 的群集,怎麼做到“真正” ? 怎麼做到解決複製的延遲,怎麼做到強數據一致性?基於全局的GTID就能解決? 圍繞這些問題進行了一些mgr 的實踐,
為未來的資料庫高可用設計多條選擇。
mysql5.7手冊17章可以看到其原理,網路上也很多同志寫了關於其技術原理,這裡自己對比rac理解下:
作為shared nothing (mgr)架構,其數據一致性實現較 shared everything(RAC) 架構要難,
MGR通過一致性(Paxos)協議,保證數據在複製組內的存活節點里是一致的,複製組內的各成員都可以進行讀寫,
其實現機制是,當某個實例發起事務提交時,會向組內發出廣播,由組內成員決議事務是否可以正常提交,
MGR在遇到事務衝突時(多節點同時修改同一行數據),會自動識別衝突,並根據提交時間讓先提交的事務成功執行,後提交的事務回滾,其原理示意圖如下:
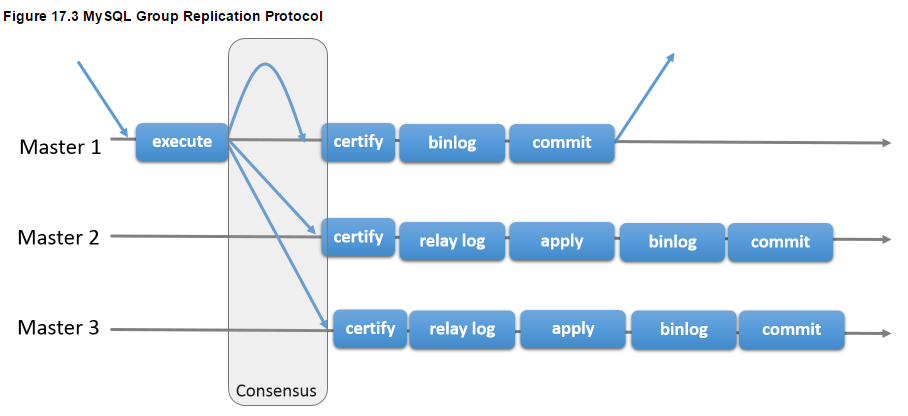
對於 sharad nothing 架構,必須要瞭解分散式協議PAXOS,分散式狀態機 理論,而在這塊我翻閱了很多資料,發現其實並不是很成熟的。從上圖可以看出來MGR 的衝突檢測機制
類似於 rac 的gird 群集組件 也具備通告廣播的群集服務。但本質架構上有所不同。一切依賴於 複製組的軟體實現。如果這裡出了問題,那麼整個群集一致性難以得到保證。
二:搭建過程
這個過程比較粗糙,網路上有不少寫的比較細的可以參考
1:MGR 必須3節點以上,這個道理不在解釋,先配置my.cnf 我這裡用一臺機器模擬3個mysql 節點進行搭建,著重理解紅色參數,對於性能優化和理解mgr 有很大幫助 port=3306 basedir=/home/mysql datadir=/home/mysql/data3 socket = /home/mysql/data3/mysql3.sock log_error=/home/mysql/data3/mysql3.error slow_query_log=on slow_query_log_file=/home/mysql/data3/slow3.log long_query_time=3 character_set_server=utf8 lower_case_table_names=1 max_connections=1000 max_connect_errors=1000 explicit_defaults_for_timestamp=1 explicit_defaults_for_timestamp log-slow-admin-statements=1 log-queries-not-using-indexes=1 expire-logs-days = 15 open_files_limit=65535 innodb_log_file_size = 100m innodb_log_files_in_group = 3 innodb_file_per_table = 1 innodb_buffer_pool_size=10240M #mgr server-id=333 gtid_mode = on enforce_gtid_consistency = 1 log_slave_updates = 1 master_info_repository=table relay_log_info_repository=table binlog_checksum=none log-bin=/home/mysql/data3/mysql-bin binlog_format=row ###指示伺服器對於每個事務,它必須收集寫集並使用XXHASH64散列演算法將其編碼為散列。 transaction_write_set_extraction=XXHASH64 ###創建的組名稱 loose-group_replication_group_name="335e89d8-2f49-4425-9add-1eeb8134f8fc" ###指示插件在伺服器啟動時不自動啟動操作,add my 美團點評,是開啟的 ###配置成員後,您可以設置 group_replication_start_on_boot 為on,以便在伺服器引導時自動啟動Group Replication。 loose-group_replication_start_on_boot=on #loose-group_replication_member_weight = 40 loose-group_replication_local_address="172.31.50.160:20003" #設置組成員的主機名和埠,新成員使用它們建立與組的連接。這些成員稱為種子成員。建立連接後,將列出組成員身份信息 #可以查詢 performance_schema.replication_group_members loose-group_replication_group_seeds="172.31.50.160:20001,172.31.50.160:20002,172.31.50.160:20003,172.31.50.160:20004" # singe or multi mode 這裡2個參數不開啟則為單主模式 #loose-group_replication_single_primary_mode = off #loose-group_replication_enforce_update_everywhere_checks = on #當成員在發生故障轉移時被選為主要成員的可能性的權重百分比,和server_uuid 配合進行選舉 #如果主要成員離開單主要組,則執行選舉,並從組中的其餘伺服器中選擇新的主要成員。 #這次選舉是通過查看新視圖,並根據值來訂購潛在的新原選 group_replication_member_weight。 #假設該組正在運行所有運行相同MySQL版本的成員,則具有最高值的成員將 group_replication_member_weight 被選為新的主要成員。 #如果多個伺服器具有相同 group_replication_member_weight的伺服器, #則根據伺服器的優先順序對伺服器進行優先順序排序 server_uuid按字典順序和選擇第一個。 #選擇新主節點後,它將自動設置為讀寫,其他副節點仍為輔助節點,因此為只讀節點。 group_replication_member_weight=80 #少數組成員由於網路中斷且無法連接到多數成員的成員在離開組之前等待多長時間參數 #少數組將永遠等待網路重新連接。在使用停止組複製之前,將阻止少數組處理的任何事務 loose-group_replication_unreachable_majority_timeout=5 #壓縮發生在組通信引擎級別,之前數據被交給組通信線程,所以它發生在mysql用戶會話線程的上下文中。事務有效網路負載可以在被髮送到組之前被壓縮, #並且在被接收時被解壓縮。壓縮是有條件的,並且取決於配置的閾值。預設情況下啟用壓縮,此外,它並不要求組中的所有伺服器節點都啟用壓縮機制, #在接收到消息時,成員檢查消息信封以驗證它是否被壓縮,如果需要,則成員解壓縮該事務,然後將其傳遞到上層 #預設情況下啟用壓縮,閾值為1000000位元組(1MB)。壓縮閾值以位元組為單位。 #美團這裡設置為128k。 group_replication_compression_theeshold=131072 #配置組接受的最大事務大小(以位元組為單位)。 #回滾大於此大小的事務。使用此選項可避免導致組失敗的大型事務。 #大型事務可能導致組的問題,無論是在記憶體分配還是網路帶寬消耗方面, #這可能導致故障檢測器觸發,因為給定成員在忙於處理大事務時無法訪問。 #設置為0時,組接受的事務大小沒有限制,並且可能存在導致組失敗的大型事務的風險。根據組中所需的工作負載大小調整此變數的值。 group_replication_transaction_size_limit=20971520 2:主節點建立複製賬戶,安裝組複製插件,開啟組複製,這裡插入測試數據,為了體現mgr的一些限制和特性 比如不支持MYISAM引擎。綠色字體插入數據報錯。
create user repl@'%' identified by 'repl123';
grant replication slave on *.* to repl@'%';
change master to
master_user='repl',
master_password='repl123'
for channel 'group_replication_recovery';
select * from mysql.slave_relay_log_info\G
install plugin group_replication soname 'group_replication.so';
set @@global.group_replication_bootstrap_group=on;
start group_replication;
set @@global.group_replication_bootstrap_group=off;
select * from performance_schema.replication_group_members;
create database test;
use test;
create table t1(id int);
create table t2(id int)engine=myisam;
create table t3(id int primary key)engine=myisam; --->不支持
create table t4(id int primary key);
3:其它節點加入組複製
change master to
master_user='repl',
master_password='repl123'
for channel 'group_replication_recovery';
install plugin group_replication soname 'group_replication.so';
set global group_replication_allow_local_disjoint_gtids_join=1;
start group_replication;
註意:
一個節點加入組複製會有本地的事物產生,比如更改密碼,加入測試數據等。上述紅字可以可以規避上述事務,強制加入,也可以在本地事務開始之前進行
sql_log_bin=0; start transaction.......... sql_log_bin=1;
4:維護
任意一節點啟動,停止組複製。
start group_replication;
stop group_replication;
查看所有線上的組複製節點
select * from performance_schema.replication_group_members;
查看誰是主節點,單主模式下,能查出值,多主模式下無法查出。
select b.member_host the_master,a.variable_value master_uuid from performance_schema.global_status a join performance_schema.replication_group_members b on a.variable_value = b.member_id where variable_name='group_replication_primary_member';
+------------+--------------------------------------+
| the_master | master_uuid |
+------------+--------------------------------------+
| calldb3 | cc4958ae-a1cc-11e8-9334-00155d322c00 |
+------------+--------------------------------------+
三:vip的實施
mgr 並不提供vip 的概念。在單主模式下,必須啟用vip實現才能做到 HA 的作用,這裡的策略網路上也很多,我們基於keepalived 進行思考
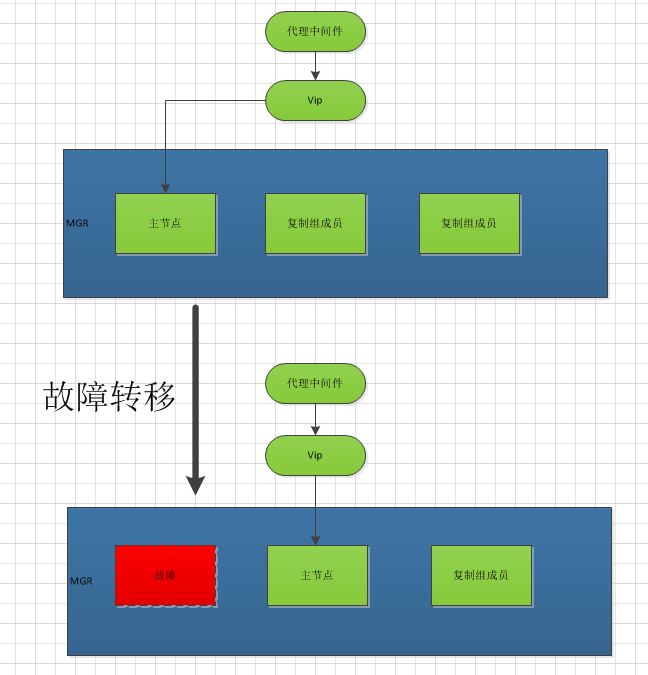
要實現上述策略,考慮故障節點的情況
1:故障節點 mysql 實例崩潰,守護進程也不能拉起改實例,需要VIP 漂移。
2:故障節點系統崩潰,段時間無法進行恢復。需要VIP 漂移。
3:判定誰是主節點,vip就漂移到主節點
基於以上3點。keepalived 除了系統故障vip漂移的功能,還需要mysql 實例崩潰的判定主節點漂移功能
具體實現:
[root@calldb1 ~]# cat /etc/keepalived/keepalived.conf vrrp_script chk_mysql_port { script "/etc/keepalived/chk_mysql.sh" ---判斷實例存活 interval 2 weight -5 fall 2 rise 1 } vrrp_script chk_mysql_master { script "/etc/keepalived/chk_mysql2.sh" ---判斷主節點 interval 2 weight 10 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 88 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.0.100 } track_script { chk_mysql_port chk_mysql_master } }
判定腳本如下:
[root@calldb1 ~]# cat /etc/keepalived/chk_mysql.sh #!/bin/bash netstat -tunlp |grep mysql a=`echo $?` if [ $a -eq 1 ] ;then service keepalived stop fi
[root@calldb1 ~]# cat /etc/keepalived/chk_mysql2.sh #!/bin/bash host=`/data/mysql/bin/mysql -h127.0.0.1 -uroot -pxxx -e "SELECT * FROM performance_schema.replication_group_members WHERE MEMBER_ID = (SELECT VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME= 'group_replication_primary_member')" |awk 'NR==2{print}'|awk -F" " '{print $3}'` host2=`hostname` if [ $host == $host2 ] ;then exit 0 else exit 1 fi

