
MapReduce簡介 MapReduce的原理圖 2.MR原理圖 根據代碼簡單瞭解MR。 代碼簡單解析: 根據執行流程圖我們不難發現,首先我們從Mapper下手,然後著手Reducer,而Reducer的key(in),value(in),肯定是Mapper的key(out),value(out) ...
MapReduce簡介
- MapReduce是一種分散式計算模型,主要解決海量數據的計算問題。
- MR有兩個階段組成:Map和Reduce,用戶只需實現map()和reduce()兩個函數,即可實現分散式計算。
MapReduce的原理圖
- MR執行的流程
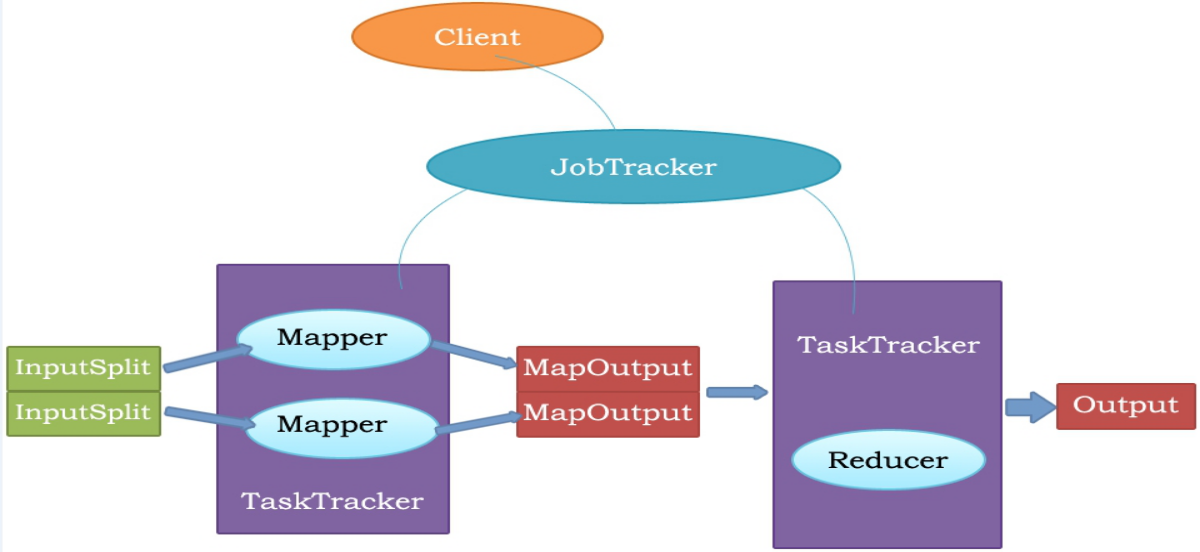
2.MR原理圖
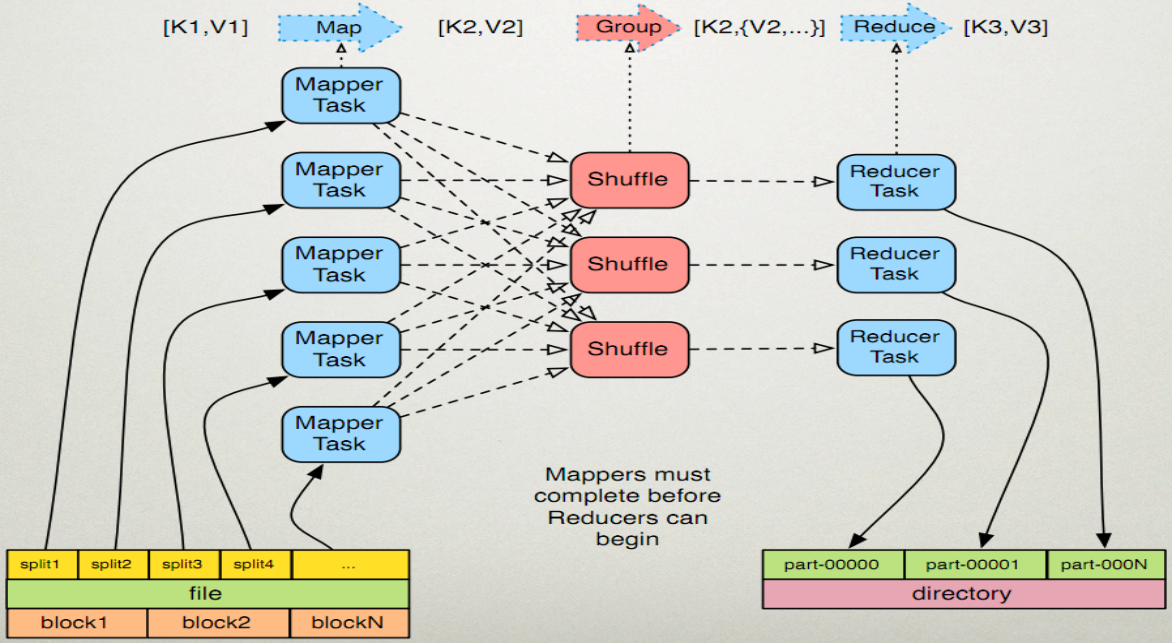
- 根據代碼簡單瞭解MR。
package com.lj.MR;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//super.map(key, value, context);
String[] arr = value.toString().split(" ");
Text keyOut = new Text();
IntWritable valueOut = new IntWritable();
for(String s :arr){
keyOut.set(s);
valueOut.set(1);
try {
context.write(keyOut,valueOut);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
package com.lj.MR; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.io.Text; import java.io.IOException; public class WCReducce extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //super.reduce(key, values, context); int count = 0; for(IntWritable iw:values){ count = count + iw.get(); } context.write(key,new IntWritable(count)); } }
package com.lj.MR; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.log4j.BasicConfigurator; public class WCApp { public static void main(String[] args) { BasicConfigurator.configure(); Configuration conf = new Configuration();
//此處為本地測試 // conf.set("fs.defaultFS","file:///D://ItTools"); try { //單例模式 Job job = Job.getInstance(conf); //任務作業名字 job.setJobName("WCApp"); //搜索類 job.setJarByClass(WCApp.class); //設置輸入格式 job.setInputFormatClass(TextInputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setMapperClass(WCMapper.class); job.setReducerClass(WCReducce.class); job.setNumReduceTasks(1); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.waitForCompletion(false); } catch (Exception e) { e.printStackTrace(); } } }
- 代碼簡單解析:
根據執行流程圖我們不難發現,首先我們從Mapper下手,然後著手Reducer,而Reducer的key(in),value(in),肯定是Mapper的key(out),value(out),否則我們不難發現,一定會類型不匹配,直接報錯。
MAP:就是將原本文字轉換成(k,v),其中k就是word,v就是單詞的出現的次數
Shuffle:將相同的k排列一起
Reduce:將相同的k的v相加


