
python2.x版本的字元編碼有時讓人很頭疼,遇到問題,網上方法可以解決錯誤,但對原理還是一知半解,本文主要介紹 python 中字元串處理的原理,附帶解決 json 文件輸出時,顯示中文而非 unicode 問題。首先簡要介紹字元串編碼的歷史,其次,講解 python 對於字元串的處理,及編碼的 ...
python2.x版本的字元編碼有時讓人很頭疼,遇到問題,網上方法可以解決錯誤,但對原理還是一知半解,本文主要介紹 python 中字元串處理的原理,附帶解決 json 文件輸出時,顯示中文而非 unicode 問題。首先簡要介紹字元串編碼的歷史,其次,講解 python 對於字元串的處理,及編碼的檢測與轉換,最後,介紹 python 爬蟲採取的 json 數據存入文件時中文輸出的問題。
參考書籍:Python網路爬蟲從入門到實踐 by唐松
在python 2或者3 ,字元串編碼只有兩類 :
(1)通用的Unicode編碼;
(2)將Unicode轉化為某種類型的編碼,如UTF-8,GBK;
1、電腦歷史:
電腦只處理數字,因此處理文本時,必須轉換成數字才行。
8位(bit)=1位元組(byte)=256種不同狀態=從000000到111111;
1GB=1024M=1024(1024kb)=1024(1024(1024b));
ASCII編碼 是對應英文字元與二進位數字之間的關係;ASCII一共規定了128種,如大寫字母A是65,即01000001;可見一字母一位元組;
GB2312編碼 簡體中文常見的編碼,兩個位元組代表一個中文漢字 ,理論上256*256個編碼,即可表示65536種中文字;
各國編碼不同,為了各國能擴平臺進行文本的轉換與處理,Unicode就被作為統一碼或者單一碼。Unicode編碼通常是兩個位元組,unicode與ASCII編碼的區別,在於unicode在ASCII編碼前加了一個0,即字母A的ASCII編碼為01000001,unicode編碼即為0000000001000001;但英文字母其實只用一個位元組就夠了,unicode編碼寫英文時多了一個位元組,浪費存儲空間。因而unicode開發了通用轉換格式(Unicode Transformation Format(UTF)),常見的有utf-8或者utf-16;
2、python字元編碼
參考地址:https://www.jb51.net/article/139878.htm
(1)encode的作用是,將unicode對象編碼成其他編碼的字元串,str.encode('utf-8'),編碼成UTF-8;(2)decode的作用是將其他編碼的字元串轉換成Unicode編碼,str.decode('UTF-8');
- import chardet 查閱具體的編碼類型,
chardet.detect(str),但是str不能是unicode編碼類型,但是該方法 不接受 本來已經是unicode的編碼的 參數,會有TypeError: Expected object of type bytes or bytearray, got: <type 'unicode'>錯誤; - 作為統一標準,unicode不能再被解碼,如果UTF-8想轉至其他非unicode,則必須(2)先decode 到unicode,在encode到其他非unicode的編碼。
爬取網頁時,可在F12 elements meta中查看網頁編碼方式,如圖:
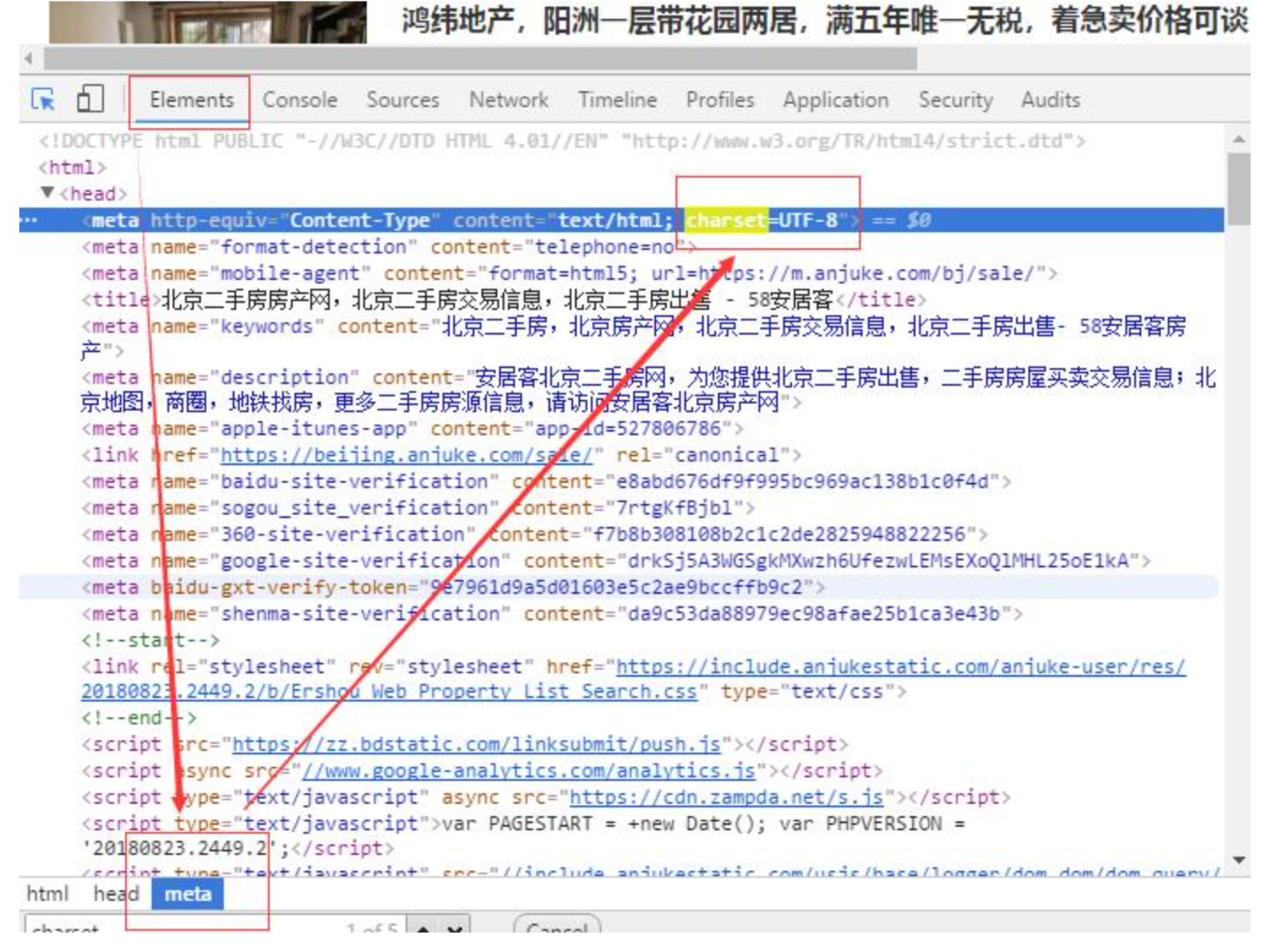
(2)中文,Python中的字典能夠被序列化到json文件中存入json
with open("anjuke_salehouse.json","w",encoding='utf-8') as f:
json.dump(all_house,f,ensure_ascii=False,sort_keys=True, indent=4);
print(u'載入入文件完成...');存儲數據如圖:
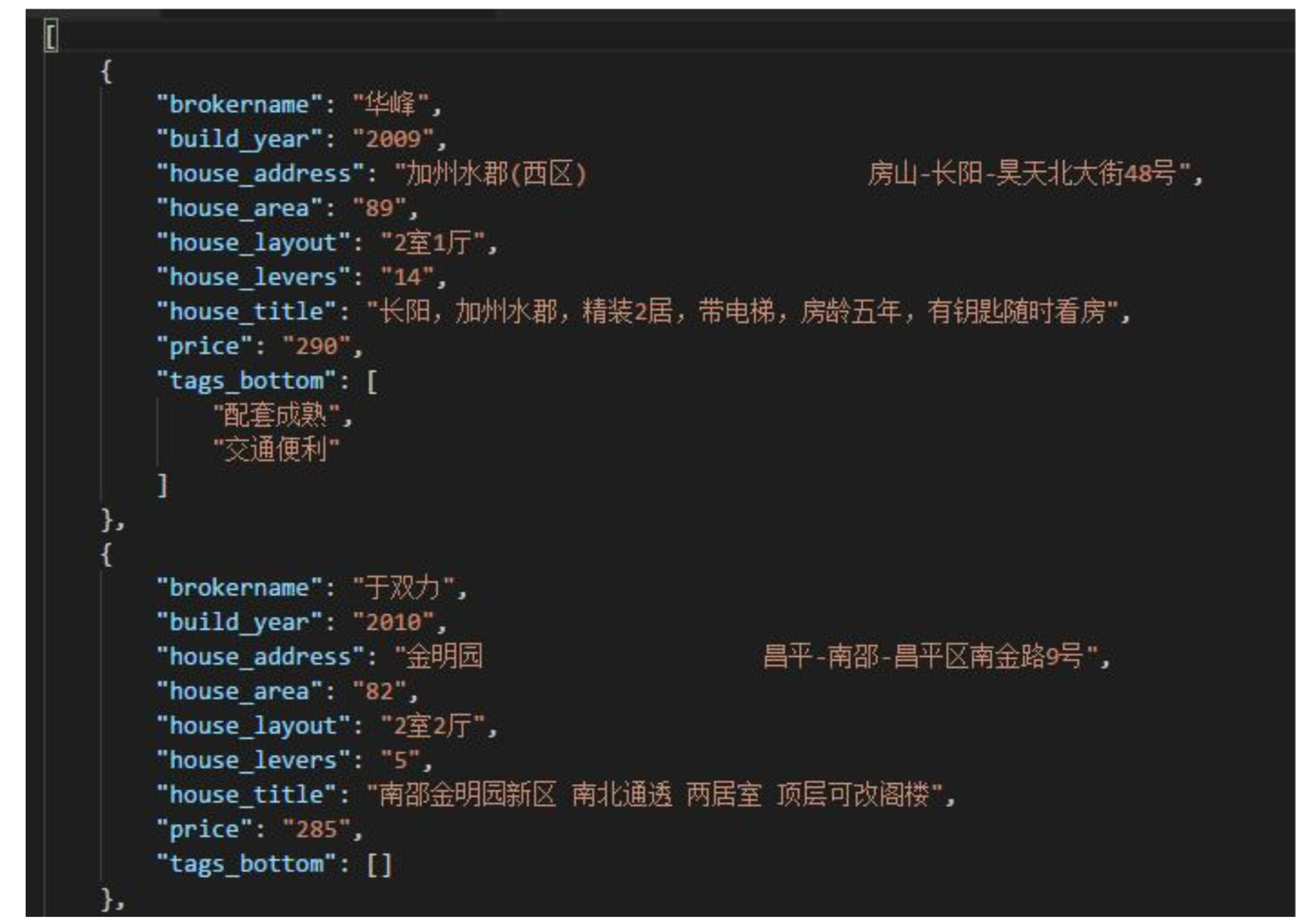
- dump()的第一個參數是要序列化的對象,第二個參數是打開的文件句柄,註意文件打開
open()時加上以UTF-8編碼打開,在dump()的時候也加上ensure_ascii=False,不然會變成ascii碼寫到json文件中json.dump(all_house,f,ensure_ascii=False,sort_keys=True, indent=4)
json.dumps()/json.loads()等用法
json_str = json.dumps(all_house,ensure_ascii=False); #all——books 為列表、字典等python自帶的數據結構,將其寫成json
#print json_str; #[{"brokername": "王東宇"},{},{}]
new_dict = json.loads(json_str);#主要是讀json文件時,需要用到
#print new_dict; #{u'house_area': u'95', u'build_year': u'2005'}- json.dumps() 是將一個Python數據結構轉換為一個JSON編碼的字元串,
{"name": "xiaoming"}
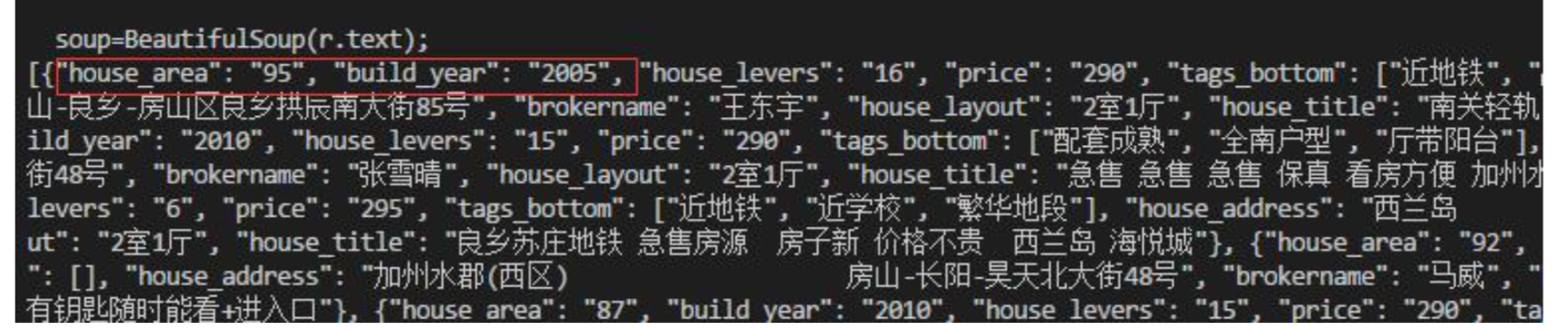
json.loads() 是將一個JSON編碼的字元串(字典形式)轉換為一個Python數據結構,{u'name': u'xiaoming'}

dumps轉化後鍵與值都變成了雙引號,而在loads後變成python變數時,元素都變成了單引號,並且字元串前加多了個u。
一般要求當要字元串通過loads轉為python數據類型時,得外層用單引號,裡面元素key和value用雙引號。
- sort_keys:根據key排序
dump與dumps的區別
dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding='utf-8', default=None, sort_keys=False, **kw);dump將一個對象序列化存入文件,dump需要一個類似於文件指針的參數(並不是真的指針,可稱之為類文件對象),可以與文件操作結合,也就是說可以將dict轉成str存入文件中,如json.dump(all_house,f,ensure_ascii=False,sort_keys=True, indent=4)中的f表示一個數據待寫入的json文件句柄;dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding='utf-8', default=None, sort_keys=False, **kw);而dumps(str)直接給的是str,也就是直接將字典轉成str,無需寫入文件,類似一個數據格式的轉換方法,將python字元串轉成json字典。- 所以dumps是將dict轉化成str格式,loads是將str轉化成dict格式。
dump和load也是類似的功能,只是與文件操作結合起來了。
(3)中文存入txt
f=open('net_saving_data.txt','w',encoding='utf-8');
for item in all_house:
# house_area=item['house_area'];
# price=item['price'];
output='\t'.join([str(item['house_area']),str(item['price']),str(item['build_year']),str(item['house_title'])]);
f.write(output);
f.write('\n');
f.close();
- 在2.7.15版本的python中,提示錯誤
TypeError: 'encoding' is an invalid keyword argument for this function,無法傳入encoding的參數,但是在3.7版本可傳入encoding='utf-8'參數,即可對 txt進行中文寫入。
!!NOTE
- 中文寫入txt、json文件是無非就是open()文件時,需要添加utf-8,dump()時,需要添加ensure_ascii=False,防止ascii編碼,但是剛開始因為python版本是2.7.15,不是3.7,導致存儲不成功的時候,一直以為是代碼的問題。所以最後發現就是版本的問題,也挺傷的。網上關於中文這個編碼問題有很多,但是他們都沒有強調python版本的問題!!!其他3.xx的版本沒有試過。
- 讀取網頁數據的時候,查看網頁的charset,及chardet庫對編碼類型的查詢,及時進行decode和encode的編碼轉化,應該就能避免很多編碼問題了。其他的坑以後踩了再補吧。

