
直方圖是表上某個欄位在按照一定百分比和規律採樣後的數據分佈的一種描述,最重要的作用之一就是根據查詢條件,預估符合條件的數據量,為sql執行計劃的生成提供重要的依據在MySQL 8.0之前的版本中,MySQL僅有一個簡單的統計信息卻沒有直方圖,沒有直方圖的統計信息可以說是沒有任何意義的。MySQL 8 ...
直方圖是表上某個欄位在按照一定百分比和規律採樣後的數據分佈的一種描述,最重要的作用之一就是根據查詢條件,預估符合條件的數據量,為sql執行計劃的生成提供重要的依據
在MySQL 8.0之前的版本中,MySQL僅有一個簡單的統計信息卻沒有直方圖,沒有直方圖的統計信息可以說是沒有任何意義的。
MySQL 8.0新特性之一就是開始支持統計信息的直方圖,這個概念很早就提出來了,抽空具體嘗試了一下使用方法。
之前寫過MSSQL相關統計信息的一點東西,在原理上都是一致的,https://www.cnblogs.com/wy123/p/5875237.html
照舊,直接上例子,造數據,創建一個測試環境
create table test ( id int auto_increment primary key, name varchar(100), create_date datetime , index (create_date desc) ); USE `db01`$$ DROP PROCEDURE IF EXISTS `insert_test_data`$$ CREATE DEFINER=`root`@`%` PROCEDURE `insert_test_data`() BEGIN DECLARE v_loop INT; SET v_loop = 100000; WHILE v_loop>0 DO INSERT INTO test(NAME,create_date)VALUES (UUID(),DATE_ADD(NOW(),INTERVAL -RAND()*100000 MINUTE) ); SET v_loop = v_loop - 1; END WHILE; END$$ DELIMITER ;
MySQL中統計信息的創建,不同於MSSQL,MySQL統計信息不依賴於索引,需要單獨創建,語法如下
--創建欄位上的統計直方圖信息
ANALYZE TABLE test UPDATE HISTOGRAM ON create_date,name WITH 16 BUCKETS;
--刪除欄位上的統計直方圖信息
ANALYZE TABLE test DROP HISTOGRAM ON create_date
1,可以一次性創建多個欄位的統計信息,系統會逐個創建列出的欄位上的統計信息,統計信息不依賴於索引,這一點與MSSQL不同(當然MSSQL也可以拋開索引獨立創建統計信息)
2,BUCKETS值是一個必須提供的參數,預設值為1000,範圍是1-1024,這一點也不同與MSSQL也不一樣,MSSQL是有一個類似的最大值為200的步長(step)欄位
3,一般來說,數據量較大的情況下,對於不重覆或者重覆性不高的數據,BUCKETS值越大,描述出來的統計信息越詳細
4,統計信息的具體內容在 information_schema.column_statistics中,但是可讀性並不好,可以根據需求自行解析(出來一種自己喜歡的格式)
與sqlserver中的統計信息一樣,理論上,在準確性與取樣百分比(BUCKETS)是成正比的,當然生成統計信息的代價也就越大,
至於BUCKETS與統計信息的取樣百分比,以及綜合代價,筆者暫時沒有找到相關的資料。
如下是通過ANALYZE TABLE test UPDATE HISTOGRAM ON create_date WITH 4 BUCKETS;創建的統計信息直方圖
可以發現直方圖的HISTOGRAM欄位是一個JSON格式的字元串,可讀性並不好。
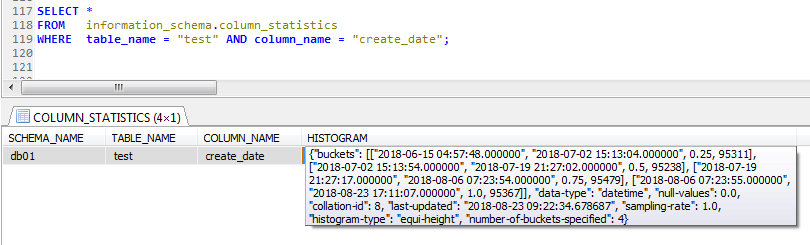
想到了sqlserver中DBCC SHOW_STATISTICS的直方圖信息,如下的格式,直方圖中的數據分佈情況看起來非常清晰直觀
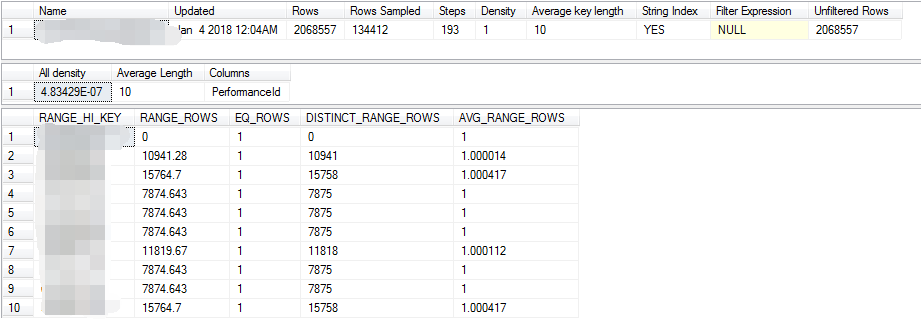
於是就做了一個MySQL直方圖的格式轉換,說白了就是解析information_schema.column_statistics表中的HISTOGRAM 欄位中的JSON內容
如下,一個簡單的解析直方圖統計信息json數據的存儲過程,參數分別是庫名,表名,欄位名
DELIMITER $$ USE `db01`$$ DROP PROCEDURE IF EXISTS `parse_column_statistics`$$ CREATE DEFINER=`root`@`%` PROCEDURE `parse_column_statistics`( IN `p_schema_name` VARCHAR(200), IN `p_table_name` VARCHAR(200), IN `p_column_name` VARCHAR(200) ) BEGIN DECLARE v_histogram TEXT; -- get the special HISTOGRAM SELECT HISTOGRAM->>'$."buckets"' INTO v_HISTOGRAM FROM information_schema.column_statistics WHERE schema_name = p_schema_name AND table_name = p_table_name AND column_name = p_column_name; -- remove the first and last [ and ] char SET v_histogram = SUBSTRING(v_HISTOGRAM,2,LENGTH(v_HISTOGRAM)-2);
DROP TABLE IF EXISTS t_buckets ; CREATE TEMPORARY TABLE t_buckets ( id INT AUTO_INCREMENT PRIMARY KEY, buckets_content VARCHAR(500) ); -- split by "]," and get single bucket content WHILE (INSTR(v_histogram,'],')>0) DO INSERT INTO t_buckets(buckets_content) SELECT SUBSTRING(v_histogram,1,INSTR(v_histogram,'],')); SET v_HISTOGRAM = SUBSTRING(v_histogram,INSTR(v_histogram,'],')+2,LENGTH(v_histogram)); END WHILE;
INSERT INTO t_buckets(buckets_content) SELECT v_histogram; -- get the basic statistics data WITH cte AS ( SELECT HISTOGRAM->>'$."last-updated"' AS last_updated, HISTOGRAM->>'$."number-of-buckets-specified"' AS number_of_buckets_specified FROM INFORMATION_SCHEMA.COLUMN_STATISTICS WHERE schema_name = p_schema_name AND table_name = p_table_name AND column_name = p_column_name ) SELECT CASE WHEN id = 1 THEN p_schema_name ELSE '' END AS schema_name, CASE WHEN id = 1 THEN p_table_name ELSE '' END AS table_name, CASE WHEN id = 1 THEN p_column_name ELSE '' END AS column_name, CASE WHEN id = 1 THEN last_updated ELSE '' END AS last_updated, CASE WHEN id = 1 THEN number_of_buckets_specified ELSE '' END AS 'number_of_buckets_specified' , id AS buckets_specified_index, buckets_content FROM ( SELECT * FROM cte,t_buckets )t; END$$ DELIMITER ;
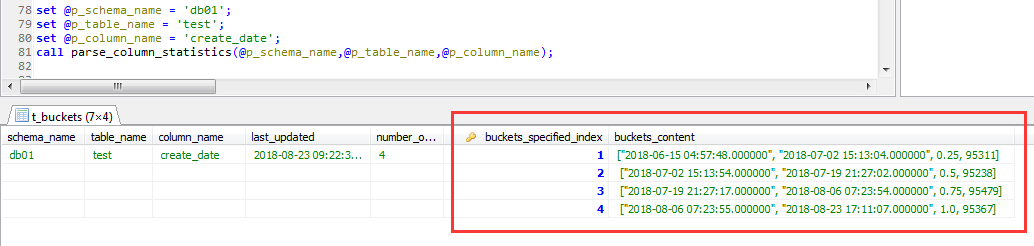
於是,第一個截圖中的結果就轉換為瞭如下的格式
這裡刻意按照4個buckets生成的直方圖,應該來說足夠簡單了,熟悉MSSQL直方圖同學,應該一眼就可以看明白這個直方圖的含義(測試數據量是400,000)
以第一個bucket為例:["2018-06-15 04:57:48.000000", "2018-07-02 15:13:04.000000", 0.25, 95311]
很明顯,
1,"2018-06-15 04:57:48.000000"和"2018-07-02 15:13:04.000000"是類似於sqlserver中直方圖中的下限值與上限值
2,0.25小於bucket的值的比例(也就小於這個區間上限制值的比例)
3,95311是這個區間的欄位值不重覆的行數。
到最後一個bucket,採樣率必然是1,也就是100%
需要註意的是,直方圖的更新時間是標準時間(UTC value),而不是伺服器當前時間。
MySQL 8.0中的直方圖基本上與sqlserver的直方圖一致,都是基於單列的抽樣預估,但是MySQL直方圖中沒有類似於sqlserver中的欄位選擇性,
不過這個欄位選擇性本身意義也不大 ,sqlserver中對於複合索引,兩個欄位合計在一塊統計,除非兩個欄位的同時分佈的都很均勻,否則多欄位索引的欄位選擇性參考意義不大。
這也是複合索引無法做到較為精確預估的原因。
存在的疑問?
之前寫過一點MySQL統計信息的,不過是在MySQL5.7下麵,還沒有直方圖的概念https://www.cnblogs.com/wy123/p/6561517.html
觸發統計信息更新的變數還是set global innodb_stats_on_metadata = 1;但是經測試,統計信息的直方圖並沒有因此而更新。
innodb_stats_on_metadata在MySQL5.7中影響到的是MySQL的索引上的統計信息,而這裡純粹是統計信息的直方圖(MySQL 8.0中直方圖跟索引沒有必然的關係)。
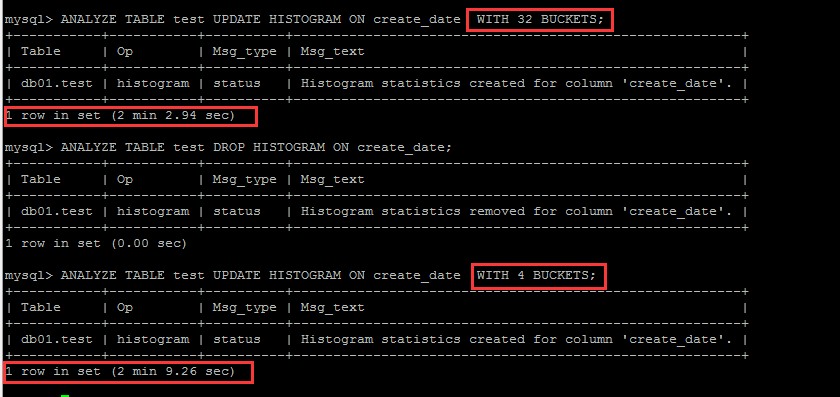
另外,這裡經過反覆測試發現,buckets的數據量,與生成直方圖的效率並沒有非常明顯的關係,如下截圖,也並不清楚,buckets數量跟取樣百分比有什麼關係。
又仔細看了一下參考鏈接的內容,發現這麼一段話:
- Maintaining an index has a cost. If you have an index, every INSERT/UPDATE/DELETE causes the index to be updated. This is not free, and will have an impact on your performance. A histogram on the other hand is created once and never updated unless you explicitly ask for it. It will thus not hurt your INSERT/UPDATE/DELETE-performance.
它本身是說明索引與直方圖之間的關係的,提到直方圖創建之後並不會自動更新,除非主動更新。
不得不吐槽的就是,如果我在某個欄位上創建了一個索引,還需要順便在創建一個統計信息直方圖?並且這個直方圖並不會隨著數據的變化自動更新,還需要手動更新。
MySQL 8.0中會不會把統計信息和索引關聯起來,或者根據需要自動創建統計信息,如果統計信息做不到自動更新,基本上可以認為是殘廢的統計信息了。
關於生成直方圖中時的資源的消耗
直方圖的生成是一個比較消耗資源的過程的,如下是在反覆測試創建直方圖的過程中,zabbix監控到的伺服器的CPU使用情況,當然,這裡僅僅觀察了一下CPU使用率的問題。
因此,直方圖再好,真要大規模應用的使用,還是要綜合考量的,在什麼時候執行更新,以及怎麼去觸發它的更新。

這裡僅僅是粗淺嘗試,難免有很多認識不足的地方。
一些有意思的東西
本文最後給出的參考鏈接中發現一些有意思的東西
MySQL 8.0中一些有意思的預估演算法,看來看去,跟sqlserver中的差別不大,都是類似大概這幾種演算法,算是沒有辦法的辦法了。
對於兩個謂詞結合在一起時候的預估,或者是沒有統計信息覆蓋的預估,基本上可以認為是瞎蒙的,因此上文中也提到,多個謂詞結合起來的選擇性,沒有什麼意義。
------------------------------------ AND : P(A and B) = P(A) * P(B) OR : P(A or B) = P(A) + P(B) - P(A and B) = : 1/10 <,> : 1/3 BETWEEN : 1/4 IN (list) : MIN(#items_in_list * SEL(=), 1/2) IN subq : [1] NOT OP : 1-SEL(OP)
與此類似的,sqlserver中的預估演算法:
https://www.cnblogs.com/wy123/p/5790855.html
https://www.cnblogs.com/wy123/p/6770258.html
https://www.cnblogs.com/wy123/p/6008477.html
參考:
https://mysqlserverteam.com/histogram-statistics-in-mysql/
https://dev.mysql.com/doc/refman/8.0/en/optimizer-statistics.html
https://dev.mysql.com/doc/refman/8.0/en/analyze-table.html#analyze-table-histogram-statistics-analysis


