這兩天翻了一下機器學習實戰這本書,演算法是不錯,只是代碼不夠友好,作者是個搞演算法的,這點從代碼上就能看出來。可是有些地方使用numpy搞數組,搞矩陣,總是感覺怪怪的,一個是需要使用三方包numpy,雖然這個包基本可以說必備了,可是對於一些新手,連pip都用不好,裝的numpy也是各種問題,所以說能不用 ...
這兩天翻了一下機器學習實戰這本書,演算法是不錯,只是代碼不夠友好,作者是個搞演算法的,這點從代碼上就能看出來。可是有些地方使用numpy搞數組,搞矩陣,總是感覺怪怪的,一個是需要使用三方包numpy,雖然這個包基本可以說必備了,可是對於一些新手,連pip都用不好,裝的numpy也是各種問題,所以說能不用還是儘量不用,第二個就是畢竟是數據,代碼樣例裡面寫的只有幾個case,可是實際應用起來,一定是要上資料庫的,如果是array是不適合從資料庫中讀寫數據的。因此綜合以上兩點,我就把這段代碼改成list形式了,當然,也可能有人會說我對numpy很熟悉啊,而且作為專業的數學包,矩陣的運算方面也很方便,我不否定,那我這段代碼恐怕對你不適合,你可以參考書上的代碼,直接照打並理解就好了。
knn,不多說了,網上書上講這個的一大堆,簡單說就是利用新樣本new_case的各維度的數值與已有old_case各維度數值的歐式距離計算
歐式距離這裡也不說了,有興趣可以去翻我那篇python_距離測量,裡面寫的很詳細,並用符號展示說明,你也可以改成棋盤距離或街區距離試試,速度可能會比歐式距離快,但還是安利歐式距離。
有一點沒搞明白的就是,對坐標進行精度化計算這塊,實測後確定使用直接計算無論是錯誤率還是精度,處理前都要比處理後更準確,可能原代碼使用小數點的概率更高些吧,也許這個計算對於小數計算精度更有幫助
閑話一些,不多也不少,下麵上代碼,代碼中配有偽代碼,方便閱讀,如果還看不太明白可以留言,我把詳細註釋加上
以下是代碼中使用顏色,選用html的16進位RGB顏色,在應用時將其轉換為10進位數字計算,old_case選取紅色圈,new_case選取橙色圈
紫色(茄子顏色)

綠色(黃瓜顏色)
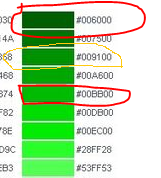
黃色(香蕉顏色)

淡綠(西葫蘆顏色)

代碼見下
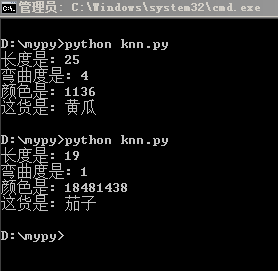
#!/usr/bin//python # coding: utf-8 ''' 1、獲取key和coord_values,樣例使用的是list,但是如果真正用在訓練上的話list就不適合了,建議改為使用資料庫進行讀取 2、對坐標進行精度化計算,這個其實我沒理解是為什麼,可能為了防止錯誤匹配吧,書上是這樣寫的 3、指定兩個參數,參數一是新加入case的坐標,參數二是需要匹配距離最近的周邊點的個數n,這裡贏指定單數 4、距離計算,使用歐式距離 新加入case的坐標與每一個已有坐標計算,這裡還有優化空間,以後更新 計算好的距離與key做成新的key-value 依據距離排序 取前n個case 5、取得key 對前n個case的key進行統計 取統計量結果最多的key即是新加入case所對應的分組 6、將新加入的values與分組寫成key-value加入已有的key-value列隊 輸入新的case坐標,返回第一步......遞歸 ''' import operator def create_case_list(): # 1代表黃瓜,2代表香蕉,3代表茄子,4代表西葫蘆 case_list = [[25,3,73732],[27.5,8,127492],[13,6,127492],[16,13,50331049],[17,4,18874516],[22,8,13762774],[14,1,30473482],[18,3,38338108]] case_type = [1,1,2,2,3,3,4,4] return case_list,case_type def knn_fun(user_coord,case_coord_list,case_type,take_num): case_len = len(case_coord_list) coord_len = len(user_coord) eu_distance = [] for coord in case_coord_list: coord_range = [(user_coord[i] - coord[i]) ** 2 for i in range(coord_len)] coord_range = sum(coord_range) ** 0.5 eu_distance.append(coord_range) merage_distance_and_type = zip(eu_distance,case_type) merage_distance_and_type.sort() type_list = [merage_distance_and_type[i][1] for i in range(take_num)] class_count = {} for type_case in type_list: type_temp = {type_case:1} if class_count.get(type_case) == None: class_count.update(type_temp) else: class_count[type_case] += 1 sorted_class_count = sorted(class_count.iteritems(), key = operator.itemgetter(1), reverse = True) return sorted_class_count[0][0] def auto_norm(case_list): case_len = len(case_list[0]) min_vals = [0] * case_len max_vals = [0] * case_len ranges = [0] * case_len for i in range(case_len): min_list = [case[i] for case in case_list] min_vals[i] = min(min_list) max_vals[i] = max([case[i] for case in case_list]) ranges[i] = max_vals[i] - min_vals[i] norm_data_list = [] for case in case_list: norm_data_list.append([(case[i] - min_vals[i])/ranges[i] for i in range(case_len)]) return norm_data_list,ranges,min_vals def main(): result_list = ['黃瓜','香蕉','茄子','西葫蘆'] dimension1 = float(input('長度是: ')) dimension2 = float(input('彎曲度是: ')) dimension3 = float(input('顏色是: ')) case_list,type_list = create_case_list() #norm_data_list,ranges,min_vals = auto_norm(case_list) in_coord = [dimension1,dimension2,dimension3] #in_coord_len = len(in_coord) #in_coord = [in_coord[i]/ranges[i] for i in range(in_coord_len)] #class_sel_result = knn_fun(in_coord,norm_data_list,type_list,3) class_sel_result = knn_fun(in_coord,case_list,type_list,3) class_sel_result = class_sel_result - 1 return result_list[class_sel_result] if __name__ == '__main__': a = main() print '這貨是: %s' %a
測試結果,效果還不賴