
有些場景下,需要隔離不同的DB,彼此DB之間不能互相訪問,但實際的業務場景又需要從A DB訪問B DB的情形,這時怎麼辦?我認為有如下常規的三種方案: 1.雙方提供RESET API,需要訪問不同DB數據時,可以通過API來獲取指定數據; 這種方案優點是隔離性、定製性強,統一齣入口,只能通過指定的A ...
有些場景下,需要隔離不同的DB,彼此DB之間不能互相訪問,但實際的業務場景又需要從A DB訪問B DB的情形,這時怎麼辦?我認為有如下常規的三種方案:
1.雙方提供RESET API,需要訪問不同DB數據時,可以通過API來獲取指定數據;
這種方案優點是隔離性、定製性強,統一齣入口,只能通過指定的API訪問指定的數據;缺點與優點是對立的,也就是定製性太強,導致每次業務發生變更,需要訪問不同數據的時候,需要雙方更改API的入參或返參,降低了開發效率;而且無法使用表JOIN,這樣在某些情況下也會導致查詢數據效率變低。目前主流的方案都是建議使用API方案
2.利用DB的同步技術(如:SQL SERVER的訂閱複製、MYSQL的主從複製腳本等)來實現不同DB的數據同步共用
這種方案優點是可以在同一個DB訪問到另一個DB中所需表的數據,可以直接JOIN,把原來的跨DB訪問變成了同一個DB的事情;缺點是依賴DB的同步技術,而且兩台DB伺服器的網路必需互通,沒有完全的隔離,且往往同步過來的表不允許直接修改,或需修改仍然需要跨DB修改或使用方案1的API來進行修改。
3.通過程式代碼實現兩個DB的數據同步(增、刪、改、查),如:可以定時輪詢源DB的A表,然後獲取變更的記錄(一般是:增、刪、改的記錄),再通過程式代碼把源DB的A表的變更記錄批量更新(若是新增、則是插入,若是修改,則是更新,若是刪除,則是刪除)到目的DB的A表中。
這種方案的優點是:可以根據實際情況靈活定製同步的表數據,不局限於某一張表或某一個DB,可以保證不同DB間同步表的數據一致性,讓本來跨DB操作表變成了同一個DB的事情,而且可以增、刪、改、查,功能不受限;缺點是靈活性太強,程式代碼實現可靠的跨DB的實時同步邏輯的實現複雜度較高,對於開發人員的要求較高,如果寫的同步邏輯無法保證實時、可靠、高可用,那對於業務來講是災難性的。
上述三種方案,第1、2方案基本都是定製化的常規方案,我(夢在旅途,http://www.zuowenjun.cn)今天要分享的是第3種方案:跨DB增量(增、改)同步兩張表的數據,註意是增量同步,其中刪除這個我沒有說明,原因是如果DB表中記錄是物理刪除(即:真實的DELETE),那就無法簡單的通過程式代碼獲取到刪除的記錄,除非在DB中加入DELETE觸發器記錄刪除記錄的主鍵到臨時表或開啟更改追蹤(CHANGE_TRACKING)或DB日誌分析,故本文講的是不給表、DB增加額外負擔的情況實時增量同步,至於刪的同步這個我認為最好是邏輯標記刪除(過期最後清理【真實刪除】),而不要物理刪除。
關於程式代碼實現跨DB同步表數據方案,之前已有總結過,詳見:https://www.cnblogs.com/zuowj/p/6264711.html ---》4.利用BCP(sqlbulkcopy)來實現兩個不同資料庫之間進行數據差異傳輸(即:數據同步)
之前的文章同步主要是基於TranFlag標記欄位 或觸發器來實現同步,這種方式必需對錶數據的增、刪、改邏輯都有要求與規範,也就是增、改必需更改TranFlag=0,刪必需記錄表刪除臨進表中,這樣才能實現同步邏輯,而今天是在這個同步基礎上(BCP),不給表、DB增加額外負擔的情況實時增量同步,對數據源的插入、改動沒有要求。
代碼如下:(以下同步適用於SQL SERVER 不同DB的表增量同步)
try
{
SqlConnection obConnSrc = new SqlConnection(connLMSStr);
SqlConnection obConnDest = new SqlConnection(mconnCCSStr);
string lastTamp = ClsDatabase.gGetFieldValue(obConnSrc, "update TS_SyncUptime set UPTime=GETDATE() OUTPUT (deleted.LastUPstamp) as oldtamp FROM TS_CCSUptime WHERE TableName=N'tableNameA'", "oldtamp");
string selectSql = @"SELECT id,aaa,bbb,ccc,ddd,eee,fff
FROM tableNameA WHERE 其它同步過濾查詢條件 AND CONVERT(bigint,sys_tamp)>{0}";
selectSql = string.Format(selectSql, lastTamp);
master.TransferBulkCopy(selectSql, obConnSrc,
"tableNameA", obConnDest,
(stable) =>
{
var colMaps = new Dictionary<string, string>();
foreach (DataColumn col in stable.Columns)
{
colMaps.Add(col.ColumnName, col.ColumnName);
}
return colMaps;
},
(tempTableName, stable, destConn, srcConn) =>
{
StringBuilder saveSqlBuilder = new StringBuilder("begin tran" + Environment.NewLine);
string IUSql = master.BuildInsertOrUpdateToDestTableSql("tableNameA", tempTableName, new[] { "id" }, stable.ExtendedProperties[master.MapDestColNames_String], 2);
saveSqlBuilder.Append(IUSql);
saveSqlBuilder.AppendLine("commit");
ClsDatabase.gExecCommand(destConn, saveSqlBuilder.ToString());
ClsDatabase.gExecCommand(srcConn, "update TS_SyncUptime set UPTime=GETDATE(),LastUPstamp=CONVERT(bigint,sys_tamp) FROM TS_SyncUptime WHERE TableName=N'tableNameA'");
return false;
});
}
catch (Exception ex)
{
writeLog(ex);//記錯誤日誌
}
上述同步代碼邏輯很簡單,可以參照之前的文章,這裡主要是說明幾個重要點:
1.TS_SyncUptime表用於記錄與管理同步任務的信息,主要包含如下幾個欄位:
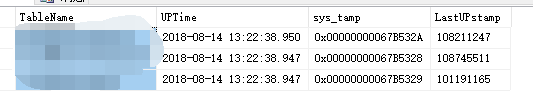
TableName:要同步的表名,UPTime每一次同步的觸發時間點(可更改),sys_tamp行變更時間戳(不可更改),LastUPstamp行最後有效變數時間戳(可以更新)
2.具體關鍵同步邏輯如下:
2.1先更新TS_SyncUptime表,以便觸發sys_tamp行變更時間戳發生改變(相當於記錄同步觸發時間點),在更改的同時取出LastUPstamp行最後有效變更時間戳(相當於上次同步的觸發時間點)
2.2使用LastUPstamp作為過濾條件,查詢>源DB的源表中時間戳欄位,這樣就可以查詢出自上一次同步觸發點到當前時間待同步的記錄(增、改)
2.3利作BCP執行同步(詳見之前文章說明)
2.4確保同步成功後,再次更新TS_SyncUptime表,並把sys_tamp行變更時間戳(當前觸發時間點)更新到LastUPstamp行最後有效變數時間戳(記住本次觸發時間點)
如上步驟即可實現可靠的同步,有人可能有疑問,這樣就能實現可靠同步嗎?我這裡解釋一下:
3.1同步觸發時記錄當前觸發時間點,並取得上一次的觸發時間點(這裡的上一次觸發時間點是指上一次開始準備同步的記錄時間點,確保從上一次查詢到同步完成之間的時間點都包括其中,防止漏數據)
3.2如果同步的任一環節失敗(只要最終沒有同步成功),那麼再次同步觸發時均取到的是同 一個時間點(LastUPstamp),而且即使重覆執行同步邏輯,也不會出現重覆(因為存在則更新不存在則插入原則),保證冪等,這樣就確保了同步的可靠性
3.3當然如果某個時間點的數據或某個DB有問題,導致一直同不不成功,可能會出現一直同步不過去的情況,這種情況可以加上預警+人工干預,這個是概率的事情。
好了,如果大家有什麼好的意見或建議歡迎下方留言評論,謝謝!


