
1. Elasticsearch 常用API 1.1.數據輸入與輸出 1.1.1.Elasticsearch 文檔 #在 Elasticsearch 中,術語 文檔 有著特定的含義。它是指最頂層或者根對象, 這個根對象被序列化成 JSON 並存儲到 Elasticsearch 中,指定了唯一 ID。 ...
1. Elasticsearch 常用API
1.1.數據輸入與輸出
1.1.1.Elasticsearch 文檔
#在Elasticsearch中,術語文檔有著特定的含義。它是指最頂層或者根對象,這個根對象被序列化成JSON並存儲到Elasticsearch中,指定了唯一ID。
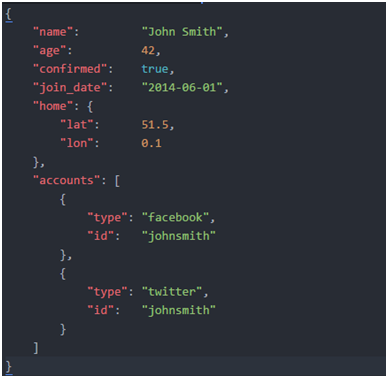
1.1.2.文檔元數據
#一個文檔不僅僅包含它的數據,也包含元數據——有關文檔的信息。三個必須的元數據元素如下:
_index:文檔在哪存放
_type:文檔表示的對象類別
_id:文檔唯一標識
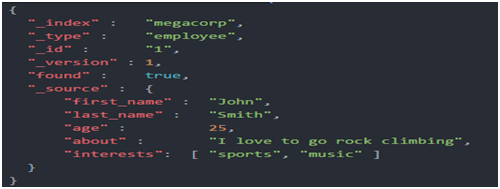
1.1.3.索引文檔
#自定義ID索引,使用Kibana中的Devtools工具,進行創建
#模板:
1 PUT /{index}/{type}/{id} 2 { 3 "field": "value", 4 ... 5 }
#例如:
1 PUT /website/blog/123 2 { 3 "title": "My first blog entry", 4 "text": "Just trying this out...", 5 "date": "2014/01/01" 6 }
#結果如下:
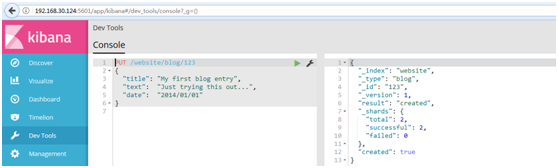
1.1.4.取迴文檔
#使用Kibana中的Devtools工具,進行取回
#為了從Elasticsearch中檢索出文檔,我們仍然使用相同的_index , _type ,和_id,但是HTTP謂詞更改為GET :
GET /website/blog/123?pretty
#響應體包括目前已經熟悉了的元數據元素,再加上_source欄位,這個欄位包含我們索引數據時發送給Elasticsearch的原始JSON文檔:
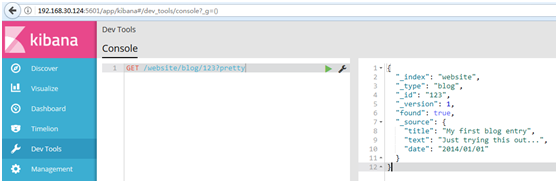
3.1.5.檢查文檔是否存在
#如果只想檢查一個文檔是否存在--根本不想關心內容--那麼用HEAD方法來代替GET方法。HEAD請求沒有返回體,只返回一個HTTP請求報頭:
curl -i -XHEAD http://localhost:9200/website/blog/123
#如果文檔存在,Elasticsearch將返回一個200 ok的狀態碼:

#若文檔不存在,Elasticsearch將返回一個404 Not Found的狀態碼:
curl -i -XHEAD http://localhost:9200/website/blog/124

1.1.6.更新整個文檔
#在Elasticsearch中文檔是不可改變的,不能修改它們。相反,如果想要更新現有的文檔,需要重建索引或者進行替換,我們可以使用相同的index API進行實現,在索引文檔中已經進行了討論。
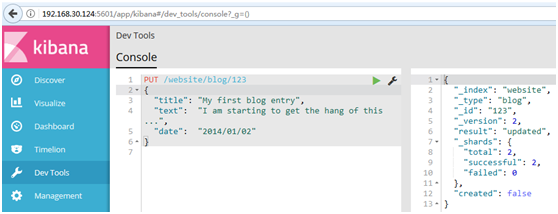
#更新語句
PUT /website/blog/123 { "title": "My first blog entry", "text": "I am starting to get the hang of this...", "date": "2014/01/02" }
#在響應體中,我們能看到Elasticsearch已經增加了_version欄位值:
# created標誌設置成false,是因為相同的索引、類型和ID的文檔已經存在。
1.1.7.創建新文檔
#1.當我們索引一個文檔,怎麼確認我們正在創建一個完全新的文檔,而不是覆蓋現有的呢?
#請記住,_index、_type和_id的組合可以唯一標識一個文檔。所以,確保創建一個新文檔的最簡單辦法是,使用索引請求的POST形式讓Elasticsearch自動生成唯一_id :

2.然而,如果已經有自己的_id,那麼我們必須告訴Elasticsearch,只有在相同的_index、_type和_id不存在時才接受我們的索引請求。這裡有兩種方式,他們做的實際是相同的事情。使用哪種,取決於哪種使用起來更方便。
第一種方法使用op_type查詢-字元串參數:

第二種方法是在URL末端使用/_create :

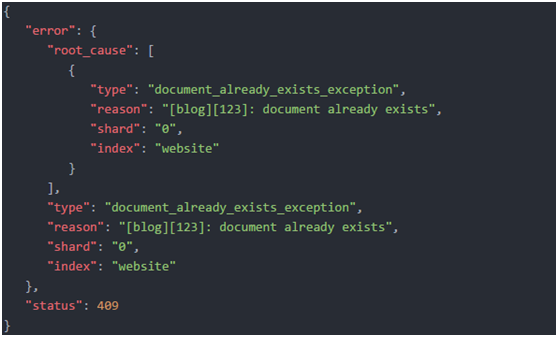
3.如果創建新文檔的請求成功執行,Elasticsearch會返回元數據和一個201 Created的HTTP響應碼。
另一方面,如果具有相同的_index、_type和_id的文檔已經存在,Elasticsearch將會返回409 Conflict響應碼,以及如下的錯誤信息:
1.1.8.刪除文檔
#刪除文檔的語法和我們所知道的規則相同,只是使用DELETE方法:
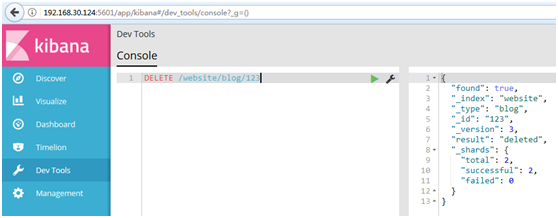
DELETE /website/blog/123
#如果找到該文檔,Elasticsearch將要返回一個200 ok的HTTP響應碼,和一個類似以下結構的響應體。註意,欄位_version值已經增加:
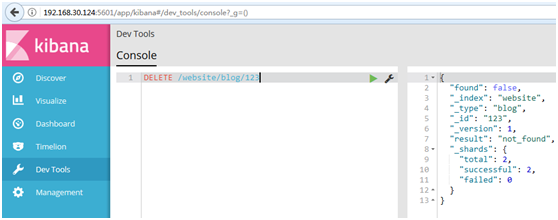
#如果文檔沒有找到,我們將得到404 Not Found的響應碼和類似這樣的響應體:
1.1.9.處理衝突(樂觀併發控制)
#Elasticsearch利用_version號來確保應用中相互衝突的變更不會導致數據丟失。我們通過指定想要修改文檔的version號來達到這個目的。如果該版本不是當前版本號,我們的請求將會失敗。
#例如創建一個博客文章
1 PUT /website/blog/1/_create 2 { 3 "title": "My first blog entry", 4 "text": "Just trying this out..." 5 }
#響應體告訴我們,這個新創建的文檔_version版本號是1。現在假設我們想編輯這個文檔:我們載入其數據到web表單中,做一些修改,然後保存新的版本。
GET /website/blog/1
#現在,當我們嘗試通過重建文檔的索引來保存修改,我們指定version為我們的修改會被應用的版本:
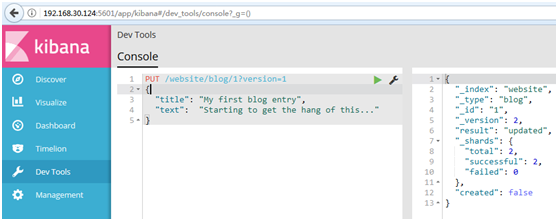
1 PUT /website/blog/1?version=1 2 { 3 "title": "My first blog entry", 4 "text": "Starting to get the hang of this..." 5 }
#我們想這個在我們索引中的文檔只有現在的_version為1時,本次更新才能成功
#此請求成功,並且響應體告訴我們_version已經遞增到2:
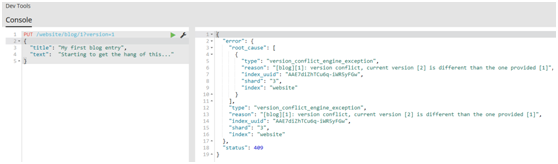
#然而,如果我們重新運行相同的索引請求,仍然指定version=1,Elasticsearch返回409 Conflict HTTP響應碼,和一個如下所示的響應體:
1.1.10.文檔部分更新
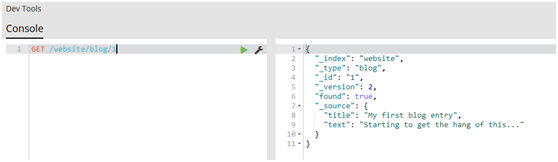
#get文檔
GET /website/blog/1
#update請求最簡單的一種形式是接收文檔的一部分作為doc的參數,它只是與現有的文檔進行合併。對象被合併到一起,覆蓋現有的欄位,增加新的欄位。例如,我們增加欄位tags和views到我們的博客文章,如下所示
1 POST /website/blog/1/_update 2 { 3 "doc" : { 4 "tags" : [ "testing" ], 5 "views": 0 6 } 7 }
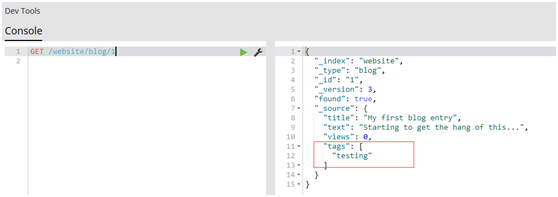
#再次get文檔
GET /website/blog/1
1.1.11.取回多個文檔
#Elasticsearch的速度已經很快了,但甚至能更快。將多個請求合併成一個,避免單獨處理每個請求花費的網路時延和開銷。如果你需要從Elasticsearch檢索很多文檔,那麼使用multi-get或者mget API來將這些檢索請求放在一個請求中,將比逐個文檔請求更快地檢索到全部文檔。
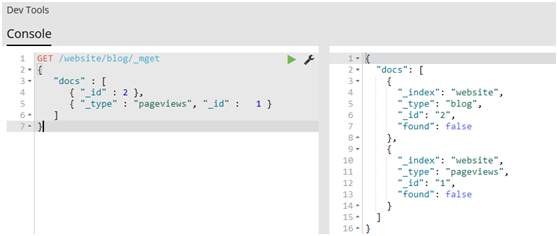
#mget API要求有一個docs數組作為參數,每個元素包含需要檢索文檔的元數據,包括_index、_type和_id。如果你想檢索一個或者多個特定的欄位,那麼你可以通過_source參數來指定這些欄位的名字
1 GET /_mget 2 { 3 "docs" : [ 4 { 5 "_index" : "website", 6 "_type" : "blog", 7 "_id" : 2 8 }, 9 { 10 "_index" : "website", 11 "_type" : "pageviews", 12 "_id" : 1, 13 "_source": "views" 14 } 15 ] 16 }

#如果想檢索的數據都在相同的_index中(甚至相同的_type中),則可以在URL中指定預設的/_index或者預設的/_index/_type。
#你仍然可以通過單獨請求覆蓋這些值:
1.1.12.批量操作(代價較小)
#與mget可以使我們一次取回多個文檔同樣的方式,bulk API允許在單個步驟中進行多次create、index、update或delete請求。如果你需要索引一個數據流比如日誌事件,它可以排隊和索引數百或數千批次。
#bulk與其他的請求體格式稍有不同,如下所示:
1 { action: { metadata }}\n 2 { request body }\n 3 { action: { metadata }}\n 4 { request body }\n 5 ...
#例如,一個delete請求看起來是這樣的:
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
#request body行由文檔的_source本身組成--文檔包含的欄位和值。它是index和create操作所必需的,這是有道理的:你必須提供文檔以索引。
它也是update操作所必需的,並且應該包含你傳遞給update API的相同請求體:doc、upsert、script等等。刪除操作不需要request body行。
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
#如果不指定_id,將會自動生成一個ID:
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
#為了把所有的操作組合在一起,一個完整的bulk請求有以下形式:
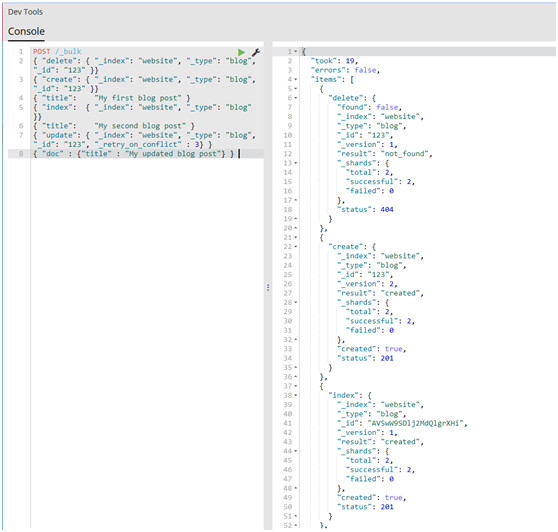
1 POST /_bulk 2 { "delete": { "_index": "website", "_type": "blog", "_id": "123" }} 3 { "create": { "_index": "website", "_type": "blog", "_id": "123" }} 4 { "title": "My first blog post" } 5 { "index": { "_index": "website", "_type": "blog" }} 6 { "title": "My second blog post" } 7 { "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} } 8 { "doc" : {"title" : "My updated blog post"} } 9
(1)請註意delete動作不能有請求體,它後面跟著的是另外一個操作。
(2)謹記最後一個換行符不要落下。
#註:整個批量請求都需要由接收到請求的節點載入到記憶體中,因此該請求越大,其他請求所能獲得的記憶體就越少。批量請求的大小有一個最佳值,大於這個值,性能將不再提升,甚至會下降。但是最佳值不是一個固定的值。它完全取決於硬體、文檔的大小和複雜度、索引和搜索的負載的整體情況。
通過批量索引典型文檔,並不斷增加批量大小進行嘗試。當性能開始下降,那麼你的批量大小就太大了。一個好的辦法是開始時將1,000到5,000個文檔作為一個批次,如果你的文檔非常大,那麼就減少批量的文檔個數。
密切關註你的批量請求的物理大小往往非常有用,一千個1KB的文檔是完全不同於一千個1MB文檔所占的物理大小。一個好的批量大小在開始處理後所占用的物理大小約為5-15 MB。
1.2.請求體查詢
1.2.1.空查詢
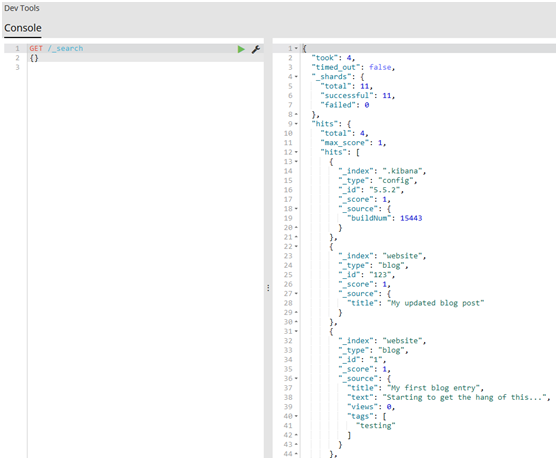
#1.讓我們以最簡單的search API的形式開啟我們的旅程,空查詢將返回所有索引庫(indices)中的所有文檔:
1 GET /_search 2 {}
#2.只用一個查詢字元串,你就可以在一個、多個或者_all索引庫(indices)和一個、多個或者所有types中查詢:
1 GET /index_2014*/type1,type2/_search 2 {}
#3.分頁搜索
1 GET /_search 2 { 3 "from": 1, 4 "size": 10 5 }

1.2.2.表達式查詢
#1.要使用這種查詢表達式,只需將查詢語句傳遞給query參數:
1 GET /_search 2 { 3 "query": YOUR_QUERY_HERE 4 }
#2.空查詢(empty search)—{}—在功能上等價於使用match_all查詢,正如其名字一樣,匹配所有文檔:
1 GET /_search 2 { 3 "query": { 4 "match_all": {} 5 } 6 }
#3.查詢語句結構
#一個查詢語句的典型結構:
1 { 2 QUERY_NAME: { 3 ARGUMENT: VALUE, 4 ARGUMENT: VALUE,... 5 } 6 }
#4.如果是針對某個欄位,那麼它的結構如下:
1 { 2 QUERY_NAME: { 3 FIELD_NAME: { 4 ARGUMENT: VALUE, 5 ARGUMENT: VALUE,... 6 } 7 } 8 }
#舉個例子,你可以使用match查詢語句來查詢tweet欄位中包含elasticsearch的tweet:
1 { 2 "match": { 3 "tweet": "elasticsearch" 4 } 5 }
#完整的查詢請求如下:
1 GET /_search 2 { 3 "query": { 4 "match": { 5 "tweet": "elasticsearch" 6 } 7 } 8 }
#5.合併查詢語句
#查詢語句(Query clauses)就像一些簡單的組合塊,這些組合塊可以彼此之間合併組成更複雜的查詢。這些語句可以是如下形式:
(1)葉子語句(Leaf clauses)(就像match語句)被用於將查詢字元串和一個欄位(或者多個欄位)對比。
(2)複合(Compound)語句主要用於合併其它查詢語句。比如,一個bool語句允許在你需要的時候組合其它語句,無論是must匹配、must_not匹配還是should匹配,同時它可以包含不評分的過濾器(filters):
1 { 2 "bool": { 3 "must": { "match": { "tweet": "elasticsearch" }}, 4 "must_not": { "match": { "name": "mary" }}, 5 "should": { "match": { "tweet": "full text" }}, 6 "filter": { "range": { "age" : { "gt" : 30, "lt":50}} } 7 } 8 }
#例如,以下查詢是為了找出信件正文包含business opportunity的星標郵件,或者在收件箱正文包含business opportunity的非垃圾郵件:
1 { 2 "bool": { 3 "must": { "match": { "email": "business opportunity" }}, 4 "should": [ 5 { "match": { "starred": true }}, 6 { "bool": { 7 "must": { "match": { "folder": "inbox" }}, 8 "must_not": { "match": { "spam": true }} 9 }} 10 ], 11 "minimum_should_match": 1 12 } 13 }
1.2.3.最重要的查詢
#1.match_all查詢,簡單的匹配所有文檔。在沒有指定查詢方式時,它是預設的查詢
1 { "match_all": {}}
#它經常與filter結合使用--例如,檢索收件箱里的所有郵件。所有郵件被認為具有相同的相關性,所以都將獲得分值為1的中性`_score`。
#2.match查詢,
#無論你在任何欄位上進行的是全文搜索還是精確查詢,match查詢是你可用的標準查詢。
#如果你在一個全文欄位上使用match查詢,在執行查詢前,它將用正確的分析器去分析查詢字元串:
{ "match": { "tweet": "About Search" }}
#如果在一個精確值的欄位上使用它,例如數字、日期、布爾或者一個not_analyzed字元串欄位,那麼它將會精確匹配給定的值:
1 { "match": { "age": 26 }} 2 { "match": { "date": "2014-09-01" }} 3 { "match": { "public": true }} 4 { "match": { "tag": "full_text" }}
#3.multi_match查詢
#multi_match查詢可以在多個欄位上執行相同的match查詢:
1 { 2 "multi_match": { 3 "query": "full text search", 4 "fields": [ "title", "body" ] 5 } 6 }
#4.range查詢
#range查詢找出那些落在指定區間內的數字或者時間:
1 { 2 "range": { 3 "age": { 4 "gte": 20, 5 "lt": 30 6 } 7 } 8 }
#5.terms查詢
#terms查詢和term查詢一樣,但它允許你指定多值進行匹配。如果這個欄位包含了指定值中的任何一個值,那麼這個文檔滿足條件:
{ "terms": { "tag": [ "search", "full_text", "nosql" ] }}
#和term查詢一樣,terms查詢對於輸入的文本不分析。它查詢那些精確匹配的值(包括在大小寫、重音、空格等方面的差異)。
#6.exists查詢和missing查詢
exists查詢和missing查詢被用於查找那些指定欄位中有值(exists)或無值(missing)的文檔。這與SQL中的IS_NULL (missing)和NOT IS_NULL (exists)在本質上具有共性:
1 { 2 "exists": { 3 "field": "title" 4 } 5 }
#這些查詢經常用於某個欄位有值的情況和某個欄位缺值的情況。
1.2.4.組合多查詢
#1.現實的查詢需求從來都沒有那麼簡單;它們需要在多個欄位上查詢多種多樣的文本,並且根據一系列的標準來過濾。為了構建類似的高級查詢,你需要一種能夠將多查詢組合成單一查詢的查詢方法。
你可以用bool查詢來實現你的需求。這種查詢將多查詢組合在一起,成為用戶自己想要的布爾查詢。它接收以下參數:
must 文檔必須匹配這些條件才能被包含進來。
must_not 文檔必須不匹配這些條件才能被包含進來。
should 如果滿足這些語句中的任意語句,將增加_score,否則,無任何影響。它們主要用於修正每個文檔的相關性得分。
filter 必須匹配,但它以不評分、過濾模式來進行。這些語句對評分沒有貢獻,只是根據過濾標準來排除或包含文檔。
由於這是我們看到的第一個包含多個查詢的查詢,所以有必要討論一下相關性得分是如何組合的。每一個子查詢都獨自地計算文檔的相關性得分。一旦他們的得分被計算出來,bool查詢就將這些得分進行合併並且返回一個代表整個布爾操作的得分。
下麵的查詢用於查找title欄位匹配how to make millions並且不被標識為spam的文檔。那些被標識為starred或在2014之後的文檔,將比另外那些文檔擁有更高的排名。如果_兩者_都滿足,那麼它排名將更高:
1 { 2 "bool": { 3 "must": { "match": { "title": "how to make millions" }}, 4 "must_not": { "match": { "tag": "spam" }}, 5 "should": [ 6 { "match": { "tag": "starred" }}, 7 { "range": { "date": { "gte": "2014-01-01" }}} 8 ] 9 } 10 }
註:如果沒有must語句,那麼至少需要能夠匹配其中的一條should語句。但,如果存在至少一條must語句,則對should語句的匹配沒有要求。
# 2.增加帶過濾器(filtering)的查詢
#如果我們不想因為文檔的時間而影響得分,可以用filter語句來重寫前面的例子:
1 { 2 "bool": { 3 "must": { "match": { "


