
本節介紹Oracle子查詢的相關內容: 實例用到的數據為oracle中scott用戶下的emp員工表,dept部門表,數據如下: 一、子查詢 1、概念:嵌入在一個查詢中的另一個查詢語句,也就是說一個查詢作為另一個查詢的條件,這個查詢稱為子查詢。 那麼可以使用子查詢的位置有select後面、from後 ...
本節介紹Oracle子查詢的相關內容:
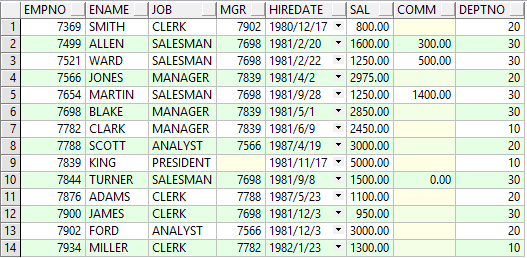
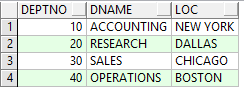
實例用到的數據為oracle中scott用戶下的emp員工表,dept部門表,數據如下:
一、子查詢
1、概念:嵌入在一個查詢中的另一個查詢語句,也就是說一個查詢作為另一個查詢的條件,這個查詢稱為子查詢。
那麼可以使用子查詢的位置有select後面、from後面、where後面以及having後面。
2、分類:(1)單行子查詢:查詢結果只返回一行數據
(2)多行子查詢:查詢結果返回多行數據,多行子查詢的操作符有IN,ALL,ANY,具體用法實例中說明。
3、示例說明:
Example1:查找每個部門的員工數量:
select deptno,dname,(select count(*) from emp e where e.deptno=d.deptno) amount from dept d;
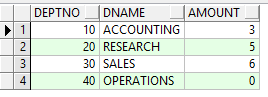
此處子查詢位於select後面,是每個部門的員工總人數。
Example2:查找工資大於部門平均工資的員工
select ename,sal,e.deptno from emp e,(select deptno,avg(sal) avgsal from emp group by deptno) m where e.deptno=m.deptno and e.sal>m.avgsal;
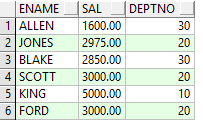
此處子查詢位於from後面,是每個部門的平均工資,將這個結果看做一張新表m,再加上查詢條件即可。
Example3:查找和scott相同職位的員工信息
select * from emp where job=(select job from emp where ename='SCOTT');

此處子查詢位於where條件中,是和scott員工一樣的職位。
Example4:查詢部門平均工資大於30號部門最高工資的部門信息。
select deptno,avg(sal) from emp group by deptno having avg(sal)>(select max(sal) from emp where deptno=30);

此處子查詢位於having子句中,是30號部門的最高工資。
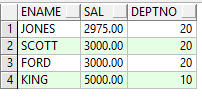
Example5:查詢部門是開發部或銷售部的員工信息
select * from emp where deptno in(select deptno from dept where dname='RESEARCH' or dname='SALES');
此處用到了多行子查詢的IN操作符用來獲取RESEARCH和SALES部門的部門號,用來限制一個範圍。
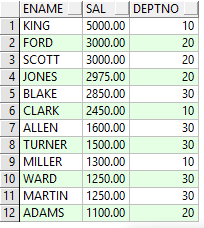
Example6:獲取工資大於30號部門所有員工工資的信息。
select ename,sal,deptno from emp where sal>all(select sal from emp where deptno=30);
此處用到了多行子查詢中的ALL操作符,用於獲取30號部門的所有工資信息,這裡all起的主要作用是為了獲得30號部門的最大工資,大於所有的意思就是大於最大的即可。
Example7:獲取工資大於30號部門任意員工工資的信息。
select ename,sal,deptno from emp where sal>any(select sal from emp where deptno=30);
此處用到了多行子查詢中的any操作符,用於獲取30號部門的工資信息,這裡any的作用和all不同,主要取最小工資,任意就是說大於這些工資裡面任意一個也就是大於最小的工資即可。
二、oracle中TOP-N查詢:
概念:用於獲取一個查詢中的前N條記錄,需要藉助rownum偽列來實現,rownum偽列,oracle為每個查詢自動生成的偽列,物理上並不存在,查詢中經常涉及多個表,但每個查詢只有一列偽列。
Example:查找部門號為20和30的工資最高的5個員工信息
select * from (select * from emp where deptno in(20,30) order by sal desc) where rownum<=5;
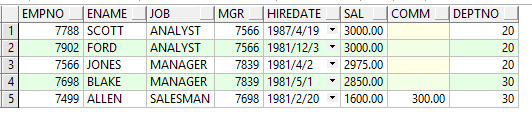
這裡在from後加了一個子查詢,那麼有個問題出現了,為什麼這裡不直接寫而是要引入一個子查詢呢,先來看看不加的結果:
select * from emp e where e.deptno in(20,30) and rownum<=5 order by e.sal desc;
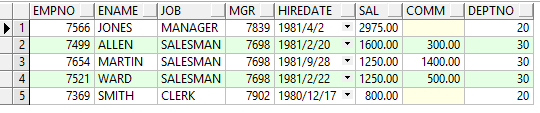
很明顯3000才是最高的工資,那是什麼原因導致了這樣的結果呢?是因為oracle中對select查詢語句的執行順序是先where條件後order by排序,也就是說先取了5行在對這5行進行排序,而正確的順序應該是所有20,30部門的員工工資先進行排序在取5行
三、Oracle分頁查詢的應用:
概念:分頁查詢,顧名思義,控制查詢結果的範圍,得到我們想要的部分數據。
Example:獲取員工表中20,30部門按工資降序以後的第4頁也就是第7,8兩條數據
select * from (select rownum rowline,emp1.* from (select * from emp where deptno in (20,30) order by sal) emp1 where rownum<=10) emp2 where emp2.rowline>=7 and emp2.rowline<=8;

這裡或許稍微有點複雜,首先為什麼不這樣寫
select * from (select * from emp where deptno in(20,30) order by sal desc) where rownum>=7 and rownum<=8;
這個查詢永遠也不會有數據生成,為什麼呢,因為當內層查詢產生第一條記錄時,oracle為其偽列賦值rownum=1,
外層查詢判rownum>=7 and rownum<=8不符合條件去除記錄,當第二條記錄產生時,oracle仍然會為其偽列賦值rownum=1,
外層判斷仍然不會通過,這樣無論內層查詢產生多少數據都會因為外層查詢的條件不符合記錄而流失數據。
而想要避免這樣的情況發生,就需要將偽列當成一個查詢中的欄位,將它不在看做“偽列”,而是真正的一個欄位,
這樣就需要在外面在嵌套一層查詢將偽列做成一個物理上存在的欄位,而最後我們只需要將外層查詢的條件改為內層查詢中“真實”存在的偽列即可。
子查詢的相關內容總結完畢,有不明處請多多指教。 2018-08-13 15:51:41


