
解析一:檢測是否有這個文件目錄,不存在的話,會自動創建 解析二:os.mkdir 與 os.makedirs 區別及用法: (1)mkdir( path [,mode] ) 作用:創建一個目錄,可以是相對或者絕對路徑,mode的預設模式是0777。 如果目錄有多級,則創建最後一級。如果最後一級目錄的 ...
#網路爬蟲之最基本的爬蟲:爬取[網易新聞排行榜](http://news.163.com/rank/)
**一些說明:**
* 使用urllib2或requests包來爬取頁面。
* 使用正則表達式分析一級頁面,使用Xpath來分析二級頁面。
* 將得到的標題和鏈接,保存為本地文件。
import os import sys import requests import re from lxml import etree def StringListSave(save_path, filename, slist): # 檢測是否有這個文件目錄,不存在的話,會自動創建 if not os.path.exists(save_path): os.makedirs(save_path) path = save_path+"/"+filename+".txt" with open(path, "w+") as fp: for s in slist: # 做了utf8轉碼,轉為終端可識別的碼制 fp.write("%s\t\t%s\n" % (s[0].encode("utf8").decode('utf-8'), s[1].encode("utf8").decode('utf-8'))) def Page_Info(myPage): '''Regex''' # 這裡的re.findall 返回的是一個元組列表,內容是 (.*?) 中匹配到的內容 # 析取每個鏈接的標題和鏈接 mypage_Info = re.findall(r'<div class="titleBar" id=".*?"><h2>(.*?)' r'</h2><div class="more"><a href="(.*?)">.*?</a></div></div>', myPage, re.S) return mypage_Info def New_Page_Info(new_page): '''Regex(slowly) or Xpath(fast)''' # 將new_page的內容轉為html格式的樹 dom = etree.HTML(new_page) # 析取 <tr <td <a中的文本 new_items = dom.xpath('//tr/td/a/text()') # 析取 <tr <td <a中的鏈接, @href 是一個屬性 new_urls = dom.xpath('//tr/td/a/@href') assert(len(new_items) == len(new_urls)) return zip(new_items, new_urls) def Spider(url): i = 0 print("downloading ", url) myPage = requests.get(url).content.decode("gbk") myPageResults = Page_Info(myPage) save_path = "網易新聞抓取" filename = str(i)+"_"+"新聞排行榜" StringListSave(save_path, filename, myPageResults) i += 1 for item, url in myPageResults: print("downloading ", url) new_page = requests.get(url).content.decode("gbk") newPageResults = New_Page_Info(new_page) filename = str(i)+"_"+item StringListSave(save_path, filename, newPageResults) i += 1 if __name__ == '__main__': print("start") start_url = "http://news.163.com/rank/" Spider(start_url) print("end")
解析一:檢測是否有這個文件目錄,不存在的話,會自動創建
import os save_path = "網易新聞抓取" if not os.path.exists(save_path): os.makedirs(save_path)
解析二:os.mkdir 與 os.makedirs 區別及用法:
(1)mkdir( path [,mode] )
作用:創建一個目錄,可以是相對或者絕對路徑,mode的預設模式是0777。
如果目錄有多級,則創建最後一級。如果最後一級目錄的上級目錄有不存在的,則會拋出一個OSError。
(2)makedirs( path [,mode] )
作用: 創建遞歸的目錄樹,可以是相對或者絕對路徑。
如果子目錄創建失敗或者已經存在,會拋出一個OSError的異常,Windows上Error 183即為目錄已經存在的異常錯誤。如果path只有一級,與mkdir一樣。
總結:os.mkdir()創建路徑中的最後一級目錄;os.makedirs()創建多層目錄。
解析三:文件操作,with open as追加文本內容實例:
(1) 最常見的讀寫操作
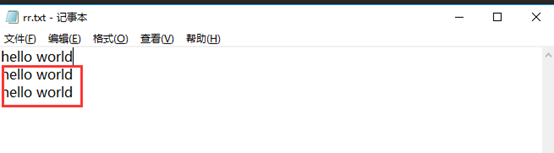
import re with open('/rr.txt', 'w') as f: f.write('hello world')
如圖所示:

追加寫入文件內容:
import re with open('/rr.txt', 'a') as f: f.write('hello world\n') # print(f.readline(1))
如圖所示:
(2) 一些正則表達式的關鍵詞
w:以寫方式打開,
a:以追加模式打開 (從 EOF 開始, 必要時創建新文件)
r+:以讀寫模式打開
w+:以讀寫模式打開 (參見 w )
a+:以讀寫模式打開 (參見 a )
rb:以二進位讀模式打開
wb:以二進位寫模式打開 (參見 w )
ab:以二進位追加模式打開 (參見 a )
rb+:以二進位讀寫模式打開 (參見 r+ )
wb+:以二進位讀寫模式打開 (參見 w+ )
ab+:以二進位讀寫模式打開 (參見 a+ )fp.read([size])
解析四:python格式化輸出
%s\t\t%s\n
解: %s:字元串; \n:換行; \t: 橫向製表符
1、 列印字元串
2、列印整數
3、列印浮點數
4、列印浮點數(指定保留小數點位數)
5、指定占位符寬度
6、指定占位符寬度,指定對其方式


