[TOC] 1.架構 架構是一種獨立於用戶的邏輯分組,組中可以存儲表,視圖,存儲過程等。假如表1在架構1中,表2在架構2中,用架構1的用戶名登錄時表2不可見。且未添加該架構的資料庫不能被該架構的用戶訪問。 1.1.創建架構併在架構中創建表 執行如下語句 用hy登錄,打開未添加dbo_Schema架構 ...
目錄
1.架構
架構是一種獨立於用戶的邏輯分組,組中可以存儲表,視圖,存儲過程等。假如表1在架構1中,表2在架構2中,用架構1的用戶名登錄時表2不可見。且未添加該架構的資料庫不能被該架構的用戶訪問。
1.1.創建架構併在架構中創建表
執行如下語句
CREATE LOGIN hy WITH PASSWORD = '123456'
GO
--新建登錄名
CREATE DATABASE schematest
GO
--新建資料庫
USE schematest
GO
CREATE USER u_for_test FOR LOGIN hy
GO
CREATE SCHEMA dbo_Schema
go
--在schematest資料庫下添加dbo_Schema
CREATE TABLE T1(id INT,NAME VARCHAR(20))
go
CREATE TABLE dbo_Schema.T2(Nid int,DD datetime)
go
GRANT SELECT ON SCHEMA :: dbo_Schema TO u_for_test;
--給u_for_test賦予SELECT許可權
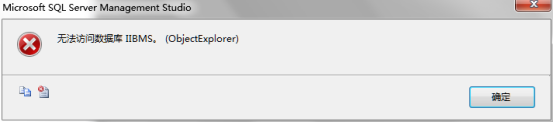
--重新使用hy登錄即可。用hy登錄,打開未添加dbo_Schema架構的資料庫,出現如下提示
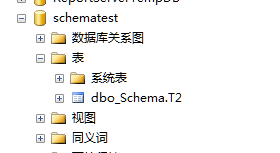
打開schematest資料庫,展開表,dbo_Schema下的T2表可見,非dbo_Schema架構下的T1表不可見。
1.2.刪除架構
刪除架構前必須刪除或者移動該架構的所有對象,不然刪除操作將會失敗。如執行下列語句
DROP SCHEMA dbo_Schema
GO結果如圖所示

此時要將T2表刪除或者移動到其他架構才能成功刪除dbo_Schema
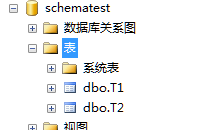
1.3.修改表的架構
如圖所示,右鍵表名——設計——右側屬性欄中修改表的架構

如圖所示,當把T2表所引用的架構修改為dbo後,可繼續刪除架構dbo_Schema操作。就能成功刪除dbo.Schema
2.視圖
視圖是資料庫中原始數據的一種變換,是查看表數據的一種方式,視圖是一種邏輯對象,是虛擬的表,是一串SELECT語句,並不是真實的表。
2.1.新建視圖
示例1:利用student表和class_student表的數據新建視圖class_01,記錄01班學生詳細信息
Student表的數據如圖所示

Class_student表的數據如圖所示
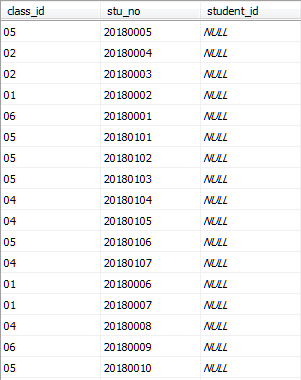
執行下列語句新建視圖class_01
CREATE VIEW class_01
AS
SELECT class_student.stu_no,class_id,stu_name,stu_sex,stu_age,stu_addr,stu_native_place,stu_birthday,stu_enter_score,stu_phone,stu_father_name,stu_mather_name
FROM class_student INNER JOIN student
ON class_student.stu_no=student.stu_no
WHERE class_id='01'視圖class_01的數據如圖所示

註:視圖只是一個SELECT語句,數據根據基表的數據改變而自動改變。
2.2.使用視圖修改數據
示例2:有course表數據,基於course表新建視圖coursetest,列名為course_id,course_name,credits。
Course表數據如圖所示
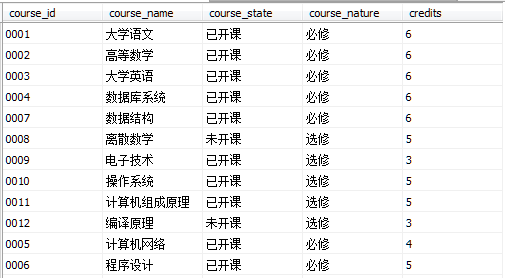
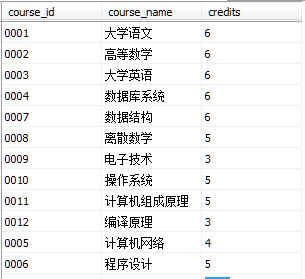
執行下列語句新建coursetest視圖
CREATE VIEW coursetest
AS
SELECT course.course_id,course_name,credits FROM courseCoursetest視圖數據如圖所示
在coursetest視圖中插入一行course_id為“0013”的數據
INSERT INTO coursetest(course_id,course_name,credits)
VALUES('0013','嵌入式系統開發','5')Course表數據如圖所示
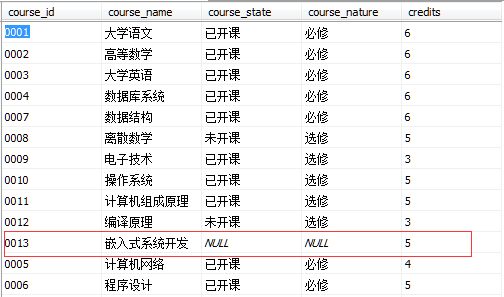
這行數據也被插入到course表中,在基於單張表的視圖中可以通過增刪改視圖數據來更新基表數據,對基於多張表的視圖不可更新。
2.3.刪除視圖
DROP VIEW coursetest3.索引
3.1.聚集索引
聚集索引數據按照索引的順序排序,查詢速度比非聚集索引快。當插入數據時,按索引順序對數據重新排序。打個比方,新華字典中按拼音查字就是聚集索引,找到了矮字就能按順序查下去找到愛字。一個表只能有1個聚集索引
如果一個表在創建主鍵時沒有聚集索引也沒指定唯一非聚集索引,會對PRIMARY KEY欄位自動創建聚集索引
3.2.非聚集索引
非聚集索引不按照索引順序排序,制定了表中數據的邏輯順序,採用指針指向數據頁的形式。一個表可以擁有多個非聚集索引。打個比方,新華字典中按筆畫查字就是非聚集索引,筆畫索引順序和字的順序不一致,依靠指針來指向數據頁。
3.3.創建索引
示例3:設置IndexDemo1表的id欄位為PRIMARY KEY,看系統是否自動為該欄位創建了聚集索引。執行下列語句
CREATE DATABASE IndexDemo
USE IndexDemo
CREATE TABLE IndexDemo1(
id INT NOT NULL,
A CHAR(10),
B VARCHAR(10),
CONSTRAINT PK_id PRIMARY KEY(id)
)結果如圖所示
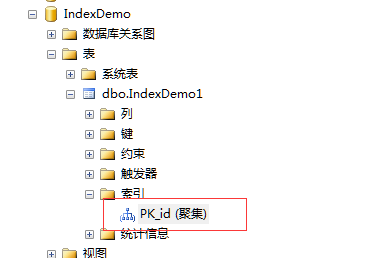
聚集索引以PRIMARY KEY的鍵名為索引名。
執行下列語句刪除PRIMARY KEY
ALTER TABLE IndexDemo1
DROP CONSTRAINT PK_id聚集索引PK_id也同時被刪除了。
示例4:在示例3的IndexDemo1表中,插入幾行數據,添加聚集索引,觀察數據順序,添加非聚集索引,觀察數據順序
IndexDemo1的數據如圖所示(未添加索引)
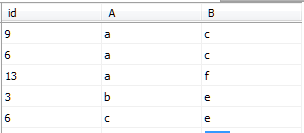
執行下列語句,為id列添加聚集索引
CREATE CLUSTERED INDEX clustered_index ON IndexDemo1(id)添加聚集索引clustered_index後IndexDemo1表的數據如圖所示
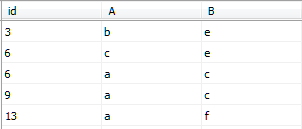
可以發現,表中數據按照id列從小到大進行排序。
此時在表中插入一條數據
INSERT INTO IndexDemo1(id,A,B)VALUES('7','g','f')表中數據排序如圖所示
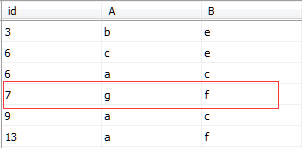
執行下列代碼刪除聚集索引clustered_index並對id列創建非聚集索引nonclustered_index
DROP INDEX IndexDemo1.clustered_index
GO--刪除聚集索引clustered_index
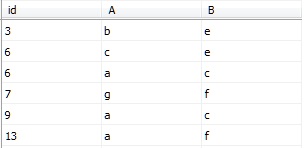
CREATE NONCLUSTERED INDEX nonclustered_index ON IndexDemo1(id)
GO--創建非聚集索引nonclustered_index表中的數據如圖所示
此時添加一條記錄
INSERT INTO IndexDemo1(id,A,B)VALUES('8','g','f')表中的數據如圖所示
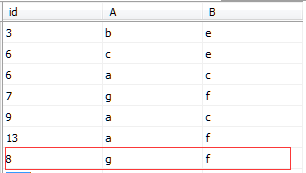
在未創建聚集索引,創建了非聚集索引的表中新插入的數據是添加在末行的。
3.4.修改索引
當數據更改時,有必要重新生成索引,重新組織索引或者禁止索引。
- 重新生成索引表示刪除索引,並且重新創建索引。這樣可以根據指定的填充度壓縮頁來刪除碎片,回收磁碟空間,重新排序索引。
- 重新組織索引對索引碎片的整理程度低於重新生成索引。
- 禁止索引表示禁止用戶訪問索引。
示例5:對IndexDemo1表中的id列重新生成索引,重新組織索引和禁止索引。
執行下列語句
ALTER INDEX nonclustered_index ON IndexDemo1 REBUILD
--重新生成索引
ALTER INDEX nonclustered_index ON IndexDemo1 REORGANIZE
--重新組織索引
ALTER INDEX nonclustered_index ON IndexDemo1 DISABLE
--禁用索引註:禁用索引後重新啟用索引,只需重新生成索引就可以了。
3.5.查看索引
可以利用目錄視圖和系統函數查看索引。這樣的函數有很多,不一一列舉了。

3.6.查看索引碎片
右鍵索引名,在屬性——碎片中查看碎片
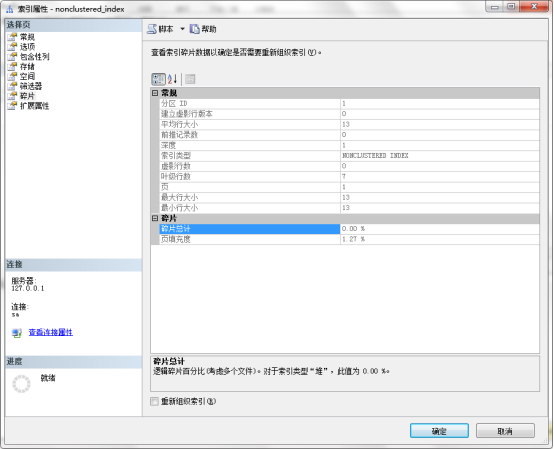
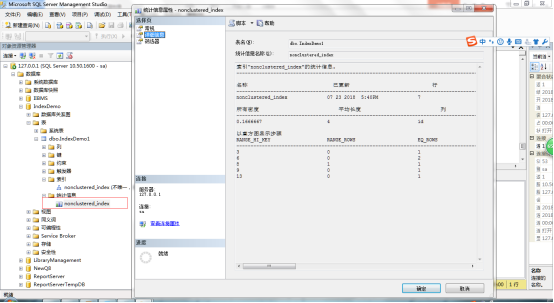
3.7.查看統計信息
在表下的統計信息中,右鍵點擊要查看統計信息的索引名,點擊詳細信息