
上兩篇文章我向大家介紹了一些線程間的基本通信方式,那麼這篇文章就和大家聊聊volatile關鍵字的相關知識。這個關鍵字在我們的日常開發中很少會使用到,而在JDK的Lock包和Concurrent包下的類則大量的使用了這個關鍵字,因為它有如下兩個特性: 1.確保記憶體可見性 2.禁止指令重排序 接下來就 ...
上兩篇文章我向大家介紹了一些線程間的基本通信方式,那麼這篇文章就和大家聊聊volatile關鍵字的相關知識。這個關鍵字在我們的日常開發中很少會使用到,而在JDK的Lock包和Concurrent包下的類則大量的使用了這個關鍵字,因為它有如下兩個特性:
1.確保記憶體可見性 2.禁止指令重排序
接下來就針對這兩點特性來進行分析,我會儘量用最能夠被理解的語言去闡述相關知識點。
什麼是可見性
在多線程環境中一定會出現這種情況:多個線程需要訪問主記憶體地址中的同一個數據。假如沒有volatile關鍵字,那麼線程A在對該數據做出修改後,緊接著線程B馬上就讀取該數據,此時線程A和線程B中的數據已經是不同的了(線程B讀取到的還是原先未被線程A修改的數據),導致後續的操作得到的結果可能和想象中的結果不同。這種情況當然是需要去避免發生的,而volatile關鍵字在這裡就能解決這個問題:如果被訪問的數據使用了volatile關鍵字修飾,那麼當某個線程修改完該數據後,必定需要先將這個最新修改的值寫回主記憶體中,從而保證下一個讀取該變數的線程取得的就是主記憶體中該數據最新的值。
我們從CPU層面看一下是如何支持volatile確保記憶體可見性這個特性的:
現在大家電腦的處理器一般都是i3、i5、i7的處理器,而這些處理器內部是有多個核心的(也就是大家平常所說的雙核、四核、六核等等),每個核心都擁有自己的緩存,可以參考下麵這張圖片:
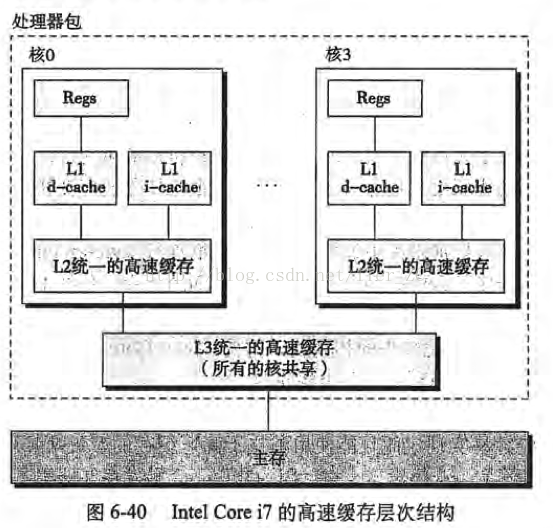
CPU執行一次指令的步驟如下:
1.程式相關數據載入到主記憶體
2.指令相關數據被載入到緩存
3.執行指令,並將計算結果存儲在緩存中
4.將緩存中的數據寫回主記憶體
這種執行步驟在單線程下是沒有任何問題的,但是在多線程併發操作的情況下就會出現不可預期的結果。試想下麵這種情況:
1.核心0中的某個線程讀取一個位元組,該位元組會存儲在核心0的緩存中以供下次直接使用
2.此時核心3的某個線程同樣讀取這個位元組,那麼該位元組同樣會被緩存在核心3的緩存中,此時核心0與核心3緩存的是一樣的數據
3.然後核心0的線程修改了這個位元組,並將修改後的結果存儲在核心0的緩存中,此時核心3的線程獲得了執行權。
4.核心3的線程開始執行指令,發現自己的緩存中存在該位元組的數據,然後就會直接拿這個位元組進行計算。但是,此時核心3的緩存中這個位元組依舊還是核心0的線程修改之前的數據!!!
此時,問題就出現了,核心3的線程並沒有取到該位元組最新的數據,而是拿舊的數據去進行計算,那麼計算後的結果就會出現偏差。
OK,問題已經拋出,那麼CPU是如何解決這個問題的呢?其實就是通過一個lock指令來解決。什麼是lock指令?這個概念就比較底層了,感興趣的童鞋可以去搜索一下IA-32手冊,這本手冊里有詳細的講解了什麼是lock指令以及lock指令具體做了什麼。
我在這裡就簡單歸納一下lock指令的幾個作用:
1.鎖匯流排/鎖緩存行。
2.lock指令會強制讓線程在對緩存中某個數據做出修改後,必須先將修改後的結果同步寫回主記憶體,然後其他的線程必須先從主記憶體中讀取最新的數據,然後再執行指令。
3.類似於記憶體屏障的效果。
上面的lock指令的幾個作用中,想必第1點和第3點童鞋們不是很清楚其中的概念。第3點涉及到了java記憶體模型的相關知識,這部分內容我會在JVM虛擬機專題中細講,此處就先針對第1點解釋一下。
匯流排的定義:CPU緩存和記憶體交換數據的介質。只要是CPU緩存想要和記憶體交換數據,必然要通過匯流排。
而早期的lock指令是這樣做的:當一個CPU緩存想要往記憶體中寫數據時,lock指令會鎖住整條匯流排,即整條匯流排只能為該CPU緩存服務。那麼此時如果其他的CPU緩存也想要把自己的數據寫到記憶體中怎麼辦呢?對不起只能等當前這個CPU緩存和記憶體交換完數據後釋放了匯流排的執行權,下一個CPU緩存才能繼續獲得匯流排的執行權,從而能夠從主記憶體中讀取最新的數據,執行指令後將最新的結果往記憶體中寫。可以看到早期的lock指令的這種做法效率是非常低的,同一時刻只能有一個CPU緩存與記憶體進行數據交換。那麼怎麼解決效率低的問題呢?現代的處理器使用了一種最主流的協議——緩存一致性協議。
緩存一致性協議的定義:當CPU中的某個核心想要將執行完指令後的結果寫回主記憶體時,必須先向匯流排申請獲取許可權。一旦獲取了許可權,那麼這個線程就能和主記憶體進行數據交換,並且此時其他CPU核心正在不斷“嗅探”匯流排,而一旦嗅探到更新數據的這塊記憶體地址發生了改變,其他的CPU就會立即將自己緩存中這塊記憶體地址緩存的數據設置為無效。而當下次執行指令需要用到這塊記憶體地址的緩存數據時,就會因為緩存已經無效從而必須去主記憶體中載入最新的數據,然後才執行具體的指令。這種方法同一時刻只會鎖定主記憶體中發生了變化的記憶體地址對應的緩存行,不會把整個匯流排鎖住,其他緩存行還是可以進行數據交換的。
這裡貼一張緩存行對應的幾種狀態,大家可以和上面的緩存一致性協議的各種情形進行對比:

現在我們再回看之前在圖6-40下提出的問題,因為有緩存一致性協議存在,核心0的線程獲取匯流排執行權將最新結果寫回主記憶體時,核心3就會嗅探到這部分記憶體地址數據發生了改變,那麼核心3就會將自己這部分的緩存置為無效。
等下次核心3的線程需要執行指令時,就會先從主記憶體中獲取最新的數據,然後再執行。緩存一致性就是通過這種方式保證了線程間數據可見性。
什麼是重排序
簡單說,重排序就是編譯器和處理器為了提高執行效率,會對程式中的指令自動重新排序。所以實際上JVM執行指令時的順序並不是和我們在程式中定義的一致的。而重排序在單線程下沒有任何問題,因為無論怎麼重新排序只要保證最後的執行結果是正確的就行。但是在多線程環境下,就有可能因為重排序導致某個線程取到的結果其實並不是最新結果從而使後續的計算結果和預期不一致。volatile為瞭解決這個問題,就提供了一種“禁止指令重排序”的功能。
那麼volatile是怎麼做的呢?我們知道多線程環境下之所以出現問題,就是因為某個線程的讀操作先於另一個線程的寫操作發生,而這種情況出現就是因為指令重排序的問題。那麼只要讓這種讀、寫操作不會被指令重排序,不就ok了嗎?
所以volatile做出了一種硬性規定,即所有涉及到有volatile變數修飾變數參與的讀、寫操作,都不允許和其他的指令進行重排序。volatile讀指令和volatile寫指令都會在該條指令前後插入一層“屏障”,來防止它們被JVM重排序。這樣就能夠保證volatile修飾的變數發生了改變後,後續所有的線程讀取到的一定是最新的數據,即所謂的“禁止重排序”。
什麼時候使用volatile變數?
上文講了volatile的兩個特性,那麼什麼時候使用volatile變數呢?我個人是推薦只有在下麵這種情況才需要使用volatile變數:程式需要通過某個布爾類型的變數來判斷執行邏輯,在多線程環境下這個變數應該使用volatile變數修飾。如下麵代碼所示:
1 volatile boolean flag; 2 ..... 3 while(!flag){ 4 doSomeThing(); 5 }
註意:為什麼僅在這種情況下推薦使用volatile變數?因為這和volatile的一個特性有關,大家必須要牢牢記住:volatile只能保證可見性,但卻不能保證原子性!!!如上面這種對布爾類型變數的讀寫本身就是原子性的操作,所以使用volatile變數保證可見性後,就能保證flag變數永遠是最新的狀態。但是,如a++這種操作,使用volatile修飾變數a並不能保證其在多線程環境執行下結果一定是正確的!因為a++並不是一個原子性的操作,它其實包含了3步指令:1.獲取當前a變數的值;2.使該值自增1;3.將自增後的結果寫回a變數。在這種情況下volatile只能保證第一步“獲取當前a變數的值”時獲取到的值是最新的,但不能保證某個線程在執行這3步指令時不會被另一個線程打斷。設想下麵這種情況:
1.假設a變數為1,一開始A線程執行了第1步和第2步,此時CPU分配給A的時間切片完畢,A緩存的值為2,然後B線程獲取了執行權。
2.B線程同樣執行了第1步和第2步,但在執行第3步之前又被A搶回了執行權,此時A將緩存中的2回寫給a變數,a此時的值為2。
3.A執行完成後,B又搶到了執行權,此時問題出現了:B緩存的值也是2,但它並沒有重新讀取a的值,而是直接執行了第3步,將自己緩存中的2回寫給了a變數,那麼a最終的值就是2。
可以看到,儘管兩個線程都執行了a++的操作,但是最終的結果確不是3而是2(相當於有一次線程執行無效),這在業務上可就是一個大問題了!因為我們日常應用中的代碼都是組合式的代碼,即一個業務必定是由一組代碼合作完成的,很少很少出現一個業務可以僅僅由簡單的原子性操作就能完成的情況。那麼這種情況怎麼辦呢?這裡就需要另外一個工具來處理了,也是我們下篇文章講解的知識點——synchronized關鍵字。
OK,volatile的相關知識到這裡就全部介紹完畢了,希望大家從本文中學到了東西。本文大量內容都參考了博客園(五月的倉頡)大神的“就是要你懂之volatile關鍵字解析”這篇文章,看看大神寫的知識,然後自己在思考,我覺得是一種不錯的學習方式。下篇文章將會講解我們最常用的鎖——synchronized關鍵字的用法和特性。


