
Hadoop簡介 Hadoop是Apache軟體基金會旗下的一個開源分散式計算平臺,為用戶提供了系統底層細節透明的分散式基礎架構。 Hadoop是基於Java語言開發的,具有很好的跨平臺特性,並且可以部署在廉價的電腦集群中。 Hadoop的核心是分散式文件系統(Hadoop Distributed ...
Hadoop簡介
Hadoop是Apache軟體基金會旗下的一個開源分散式計算平臺,為用戶提供了系統底層細節透明的分散式基礎架構。
Hadoop是基於Java語言開發的,具有很好的跨平臺特性,並且可以部署在廉價的電腦集群中。
Hadoop的核心是分散式文件系統(Hadoop Distributed File System,HDFS)和MapReduce。
Hadoop被公認為行業大數據標準開源軟體,在分散式環境下提供了海量數據的處理能力。
Hadoop的特性
Hadoop是一個能夠對大量數據進行分散式處理的軟體框架,並且是一種可靠、高效、可伸縮的方式進行處理的,它具有以下幾個方面的特性:
高可靠性:採用冗餘數據存儲方式,即使一個副本發生故障,其他副本也可以保證正常對外提供服務。
高效性:作為並行分散式計算平臺,Hadoop採用分散式存儲和分散式處理兩大核心技術,能夠高效地處理PB級數據。
高可擴展性:Hadoop的設計目標是可以高效穩定地運行在廉價的電腦集群上,可以擴展到數以千萬計的電腦節點上。
高容錯性:採用冗餘數據存儲方式,自動保存數據的多個副本,並且能夠自動將失敗的任務進行重新分配。
成本低:Hadoop採用廉價的電腦集群,成本比較低,普通用戶也很容易用自己的PC搭建Hadoop運行環境。
運行在Linux平臺上:Hadoop是基於Java語言開發的,可以較好地運行在Linux平臺上。
支持多種編程語言:Hadoop上的應用程式也可以使用其他編程語言編寫。
Hadoop生態系統
經過多年的發展。Hadoop生態系統不斷完善和成熟,目前已經包括了多個子項目。除了核心的HDFS和MapReduce以外,Hadoop生態系統還包括Zookeeper,HBase,Hive,Pig,Mahout、Sqoop、Flume、Ambari等功能組件。需要說明的是,Hadoop2.0中新增了一些重要的組件,即HDFS HA和分散式資源調度管理框架YRAN等。
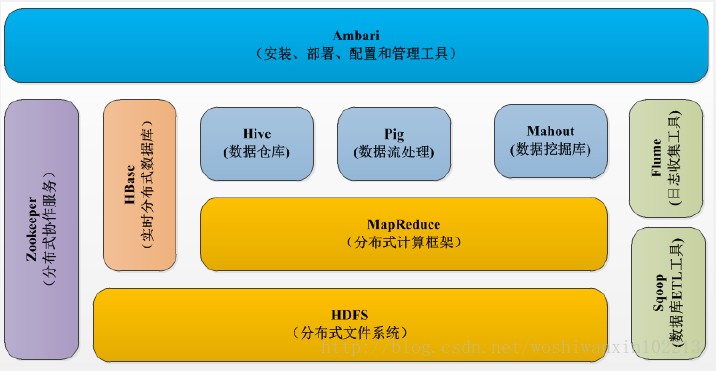
HDFS:Hadoop分散式文件系統是Hadoop項目的兩大核心之一,是針對谷歌文件系統的開源實現。HDFS具有處理超大數據、流式處理、可以運行在廉價商用伺服器上等優點。HDFS在設計之初就是要運行在廉價的大型伺服器集群上,因此在設計上就把硬體故障作為一種常態來考慮,可以保證在部分硬體發生故障的情況下仍然能夠保證文件系統的整體可用性和可靠性。
HBase:HBase是一個提供高可靠性、高性能、可伸縮、實時讀寫、分散式的列式資料庫,一般採用HDFS作為其底層數據存儲。HBase是針對谷歌BigTable的開源實現,二者都採用了相同的數據模型,具有強大的非結構化數據存儲能力。HBase與傳統關係資料庫的一個重要區別是,前者採用基於列的存儲,而後者採用基於行的存儲。HBase具有良好的橫向擴展能力,可以通過不斷增加廉價的商用伺服器來增加存儲能力。
MapReduce:Hadoop MapReduce是針對谷歌MapReduce的開源實現。MapRedece是一種編程模型,用於大規模數據集(大於1TB)的並行運算,它將複雜的、運行於大規模集群上的並行計算過程高度地抽象到了兩個函數——Map和Reduce上,並且允許用戶在不瞭解分散式系統底層細節的情況下開發並行應用程式,並將其運行於廉價電腦集群上,完成海量數據的處理。通俗地說,MapReduce的核心思想就是“分而治之”,它把輸入的數據集切分為若幹獨立的數據塊,分發給一個主節點管理下的各個分節點來共同並行完成;最後,通過整合各個節點的中間結果得到最終結果。
Hive:Hive是一個基於Hadoop的數據倉庫工具,可以用於對Hadoop文件中數據集進行數據整理、特殊查詢和分析存儲。Hive學習門檻比較低,因為它提供了類似於關係資料庫SQL語言的查詢語句——Hive QL,可以通過Hive QL語句快速實現簡單的MapReduce統計,Hive自身可以將Hive QL語句轉換為MapReduce任務進行運行,而不必開發專門的MapReduce應用,因而十分適合數據倉庫的統計分析。
Pig:是一種數據流語言和運行環境,適合於使用Hadoop和MapRedeuce平臺來查詢大型半結構化數據集。雖然MapReduce應用程式的編寫不是十分複雜,但畢竟也是需要一定的開發經驗的。Pig的出現大大簡化了Hadoop常見的工作任務,它在MapReduce的基礎上創建了更簡單的過程語言抽象,為Hadoop應用程式提供了一種更加接近結構化查詢語言(SQL)的介面。Pig是一個相對簡單的語言,它可以執行語句,因此當我們需要從大型數據集中搜索滿足某個給定搜索條件的記錄時,採用Pig要比MapReduce具有明顯的優勢,前者只需要編寫一個簡單的腳本在集群中自動並行處理與分發,而後者則需要編寫一個單獨的MapReduce應用程式。
Mahout:Mahout是Apache軟體基金會旗下的一個開源項目,提供一些可擴展的機器學習領域經典演算法的實現,旨在幫助開發人員更加方便快捷地創建智能應用程式。
Zookeeper:是針對谷歌Chubby的一個開源實現,是高效和可靠的協同工作系統,提供分散式鎖之類的基本服務(如統一命名服務、狀態同步服務、集群管理、分散式應用配置項的管理等),用於構建分散式應用,減輕分散式應用程式所承擔的協調任務,Zookeeper使用Java編寫,很容易編程接入,它使用了一個和文件樹結構相似的數據模型,可以使用Java或者C來進行編程接入。
Flume:是Cloudera提供的一個高可用、高可靠、分散式的海量日誌採集、聚合和傳輸的系統。Flume支持在日誌系統中定製各類數據發送方,用於收集數據;同時,Flume提供對數據進行簡單處理並寫到各種數據接收方的能力。
Sqoop:是SQL-to-Hadoop的縮寫,主要用來在Hadoop和關係資料庫之間交換數據,可以改進數據的互操特性。通過Sqoop可以方便地將數據從MySQL、Oracle、PostgreSQL等關係資料庫中導入Hadoop(可以導入HDFS、HBase或Hive),或者將數據從Hadoop導出到關係資料庫,使得傳統關係資料庫和Hadoop之間的數據遷移變得非常方便。Sqoop主要通過JDBC和關係資料庫進行交互,理論上,支持JDBC的關係資料庫都可以使用Sqoop和Hadoop進行數據交互。Sqoop是專門為大數據集設計的,支持增量更新,可以將新紀錄添加到最近一次導出的數據源上,或者指定上次修改的時間戳。(寫到這裡突然想起來面試的時候不知天高地厚非要和HR交流技術,HR問我將大規模數據從資料庫導出應該使用什麼技術,傻傻地回答JDBC。)
Ambari:Apache Ambari是一種基於Web的工具,支持Apache Hadoop集群的安裝、部署、配置和管理。Ambari目前已支持大多數Hadoop組件,包括HDFS、MapReduce、Hive、Pig、HBase、Zookeeper、Sqoop等。

