
一.大數據發展背景 現今是數據飛速膨脹的大數據時代,大數據強調3V特征,即Volume(量級)、Varity(種類)和Velocity(速度)。 ·Volume(量級):TB到ZB。 ·Varity(種類):結構化到結構化和非結構化。 ·Velocity(速度):批量數據到流數據處理。 據統計全球8 ...
一.大數據發展背景
現今是數據飛速膨脹的大數據時代,大數據強調3V特征,即Volume(量級)、Varity(種類)和Velocity(速度)。
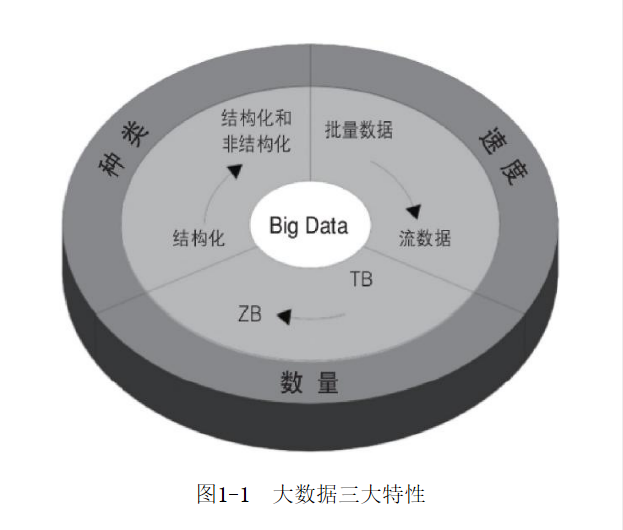
·Volume(量級):TB到ZB。
·Varity(種類):結構化到結構化和非結構化。
·Velocity(速度):批量數據到流數據處理。
據統計全球80%的數據是非結構化的或者半結構化的,剩下的才是傳統的結構化數據。傳統關係型資料庫處理能力有限。HBase的出現彌補了Hadoop只能離線批處理的不足,同時能夠存儲小文件,提供海量數據的隨機檢索。
二.NoSQL
NoSQL,是Not only SQL的縮寫,泛指非關係型的資料庫。與關係型資料庫相比,NoSQL存在許多顯著的不同點,其中最重要的是NoSQL不使用SQL作為查詢語言。
其數據存儲可以不需要固定的表模式,也通常會避免使用SQL的JOIN操作,一般又都具備水平可擴展的特性。NoSQL的實現具有兩個特征:使用硬碟和把隨機存儲器作存儲載體。
1.傳統關係型資料庫的缺陷
(1)高併發讀寫的瓶頸關係型資料庫應付上萬次SQL查詢還勉強頂得住,但是應付上萬次SQL寫數據請求,硬碟I/O卻無法承受。
例如,人人網的實時統計線上用戶狀態,記錄熱門帖子的點擊次數,投票計數等,都是相對高併發寫請求的需求。
(2)可擴展性的限制
對於很多需要提供24小時不間斷服務的網站來說,對資料庫系統進行升級和擴展是非常痛苦的事情,往往需要停機維護和數據遷移,而不能通過橫向添加節點的方式實現無縫擴展。
(3)事務一致性的負面影響
事務執行的結果必須是使資料庫從一個一致性狀態變到另一個一致性狀態。保證資料庫一致性是指當事務完成時,必須使所有數據都具有一致的狀態。在關係型資料庫中,所有的規則必須應用到事務的修改上,以便維護所有數據的完整性,這隨之而來的是性能的大幅度下降。因此資料庫事務管理成了高負載下的一個沉重負擔。
(4)複雜SQL查詢的弱化
任何大數據量的Web系統都非常忌諱幾個大表間的關聯查詢,以及複雜的數據分析類型的SQL查詢,更多的情況往往只是單表的主鍵查詢,以及單表的簡單條件分頁查詢,SQL的功能被極大地弱化了,所以這部分功能不能得到充分發揮。
2.NoSQL資料庫的優勢
(1)擴展性強
NoSQL資料庫種類繁多,但是一個共同的特點就是去掉關係型資料庫的關係特性,若數據之間是弱關係,則非常容易擴展。例如,HBase、Cassandra等系統的水平擴展性能非常優越,非常容易實現支撐數據從TB到PB級別的過渡。
(2)併發性能好
NoSQL資料庫具有非常良好的讀寫性能,這得益於它的弱關係性,資料庫的結構簡單。一般MySQL使用QueryCache,這是一種大粒度的Cache,而NoSQL的Cache是記錄級的,是一種細粒度的Cache,
(3)數據模型靈活
NoSQL無須事先為要存儲的數據建立欄位,隨時可以存儲自定義的數據格式。NoSQL允許使用者隨時隨地添加欄位,並且欄位類型可以是任意格式。Hadoop最適合的應用場景是離線批量處理數據,其離線分析的效率非常高,HBase的列式存儲的特性支撐它實時隨機讀取、基於KEY的特殊訪問需求。
三.HBase是什麼
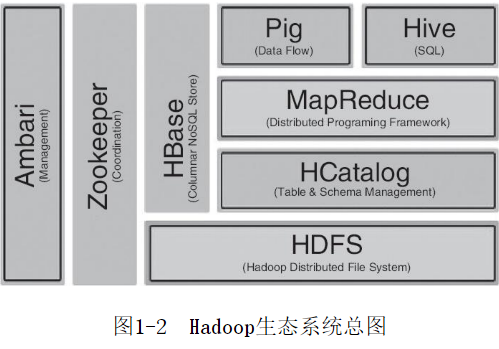
HBase(Hadoop Database)是一個高可靠、高性能、面向列、可伸縮的分散式資料庫,利用HBase技術可在廉價PC上搭建起大規模結構化存儲集群。HBase參考Google的BigTable建模,使用類似GFS的HDFS作為底層文件存儲系統,在其上可以運行MapReduce批量處理數據,使用ZooKeeper作為協同服務組件。HBase的整個項目使用Java語言實現,HBase還是一種非關係型資料庫,即NoSQL資料庫。發行版本中偶數版本是穩定發佈版,而奇數版本都是開發版,基本不對外發佈,存在0.94、0.96、0.98三個大版本。其中stable文件夾包含了最新的穩定發佈版本。與Hadoop的關係,HBase嚴重依賴Hadoop的HDFS組件,HBase使用HDFS作為底層存儲系統。Hadoop的組件之一MapReduce可以直接訪問HBase,但是,這不是必需的,因為HBase中最重要的訪問方式是原生JavaAPI,而不是MapReduce這樣的批量操作方式。
HBase的特性
HBase作為一個典型的NoSQL資料庫,可以通過行鍵(Rowkey)檢索數據,僅支持單行事務,主要用於存儲非結構化和半結構化的鬆散數據。與Hadoop相同,HBase設計目標主要依靠橫向擴展,通過不斷增加廉價的商用伺服器來增加計算和存儲能力。HBase具備的一些非常顯著的特點:
1.容量巨大
HBase的單表可以有百億行、百萬列,數據矩陣橫向和縱向兩個維度所支持的數據量級都非常具有彈性。
傳統的關係型資料庫,如Oracle和MySQL等,如果數據記錄在億級別,查詢和寫入的性能都會呈指數級下降,所以更大的數據量級對傳統資料庫來講是一種災難。
而HBase對於存儲百億、千億甚至更多的數據都不存在任何問題。更加多的列:千萬和億級別,這種非常特殊的應用場景,並不是說HBase不支持,而是這種情況下訪問單個Rowkey可能造成訪問超時,如果限定某個列則不會出現這種問題。
2.面向列
HBase是面向列的存儲和許可權控制,並支持列獨立檢索,列式存儲資料庫。
列式存儲不同於傳統的關係型資料庫,其數據在表中是按某列存儲的,這樣在查詢只需要少數幾個欄位的時候,能大大減少讀取的數據量,比如一個欄位的數據聚集存儲,那就更容易為這種聚集存儲設計更好的壓縮和解壓演算法。
傳統行式資料庫的特性如下:
·數據是按行存儲的。
·沒有索引的查詢使用I/O。
·建立索引和物化視圖需要花費的時間和資源。
·面對查詢需求,資料庫必須被膨脹才能滿足需求。
列式資料庫的特性如下:
·數據按列存儲,即每一列單獨存放。
·數據即索引。
·只訪問查詢涉及的列,可以降低系統I/O。
·每一列由一個線索來處理,即查詢的併發處理性能高。
·數據類型一致,數據特征相似,可以高效壓縮。
列式存儲不但解決了數據稀疏性問題,最大程度上節省存儲開銷,而且在查詢發生時,僅檢索查詢涉及的列,能夠降低磁碟I/O。
3.稀疏性
在大多數情況下,採用傳統行式存儲的數據往往是稀疏的,即存在為空(NULL)的列,而這些列都是占用存儲空間的,這就造成存儲空間的浪費。對於HBase來講,為空的列並不占用存儲空間,因此,表可以設計得非常稀疏。
4.擴展性
HBase底層文件存儲依賴HDFS,從“基因”上決定了其具備可擴展性。
同時,HBase的Region和RegionServer的概念對應的數據可以分區,分區後數據可以位於不同的機器上,所以在HBase核心架構層面也具備可擴展性。HBase的擴展性是熱擴展,在不停止現有服務的前提下,可以隨時添加或者減少節點。
5.高可靠性
HBase提供WAL和Replication機制。前者保證了數據寫入時不會因集群異常而導致寫入數據的丟失;後者保證了在集群出現嚴重問題時,數據不會發生丟失或者損壞。而且HBase底層使用HDFS,HDFS本身的副本機制很大程度上保證了HBase的高可靠性。同時,協調服務的ZooKeeper組件是經過工業驗證的,具備高可用性和高可靠性。
6.高性能
底層的LSM數據結構和Rowkey有序排列等架構上的獨特設計,使得HBase具備非常高的寫入性能。Region切分、主鍵索引和緩存機制使得HBase在海量數據下具備一定的隨機讀取性能,該性能針對Rowkey的查詢能夠達到毫秒級別。
四.HBase的核心功能模塊
Hadoop框架包含兩個核心組件:HDFS和MapReduce,其中HDFS是文件存儲系統,負責數據存儲;MapReduce是計算框架,負責數據計算。
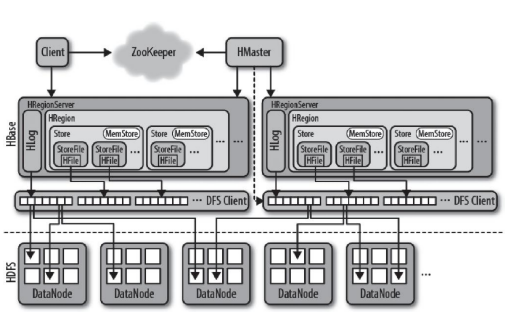
HBase資料庫的核心組件共有4個,它們分別是:客戶端Client、協調服務模塊ZooKeeper、主節點HMaster和Region節點RegionServer。
(1)客戶端Client
客戶端Client是整個HBase系統的入口。使用者直接通過客戶端操作HBase。客戶端使用HBase的RPC機制與HMaster和RegionServer進行通信。對於管理類操作,Client與HMaster進行RPC通信;對於數據讀寫類操作,Client與RegionServer進行RPC交互。
這裡客戶端可以是多個,並不限定是原生Java介面,還有Thrift、Avro、Rest等客戶端模式,甚至MapReduce也可以算作一種客戶端。
(2)協調服務組件ZooKeeper
ZooKeeperQuorum(隊列)負責管理HBase中多HMaster的選舉、伺服器之間狀態同步等。
HBase中ZooKeeper實例負責的協調工作有:存儲HBase元數據信息、實時監控RegionServer、存儲所有Region的定址入口,當然還有最常見的功能就是保證HBase集群中只有一個HMaster節點。
(3)主節點HMaster
HMaster沒有單點問題,在HBase中可以啟動多個HMaster,通過ZooKeeper的Master選舉機制保證總有一個Master正常運行並提供服務,其他HMaster作為備選時刻準備(當目前HMaster出現問題時)提供服務。
HMaster主要負責Table和Region的管理工作:
·管理用戶對Table的增、刪、改、查操作。
·管理RegionServer的負載均衡,調整Region分佈。
·在Region分裂後,負責新Region的分配。
·在RegionServer死機後,負責失效RegionServer上的Region遷移。
(4)Region節點HRegionServer
HRegionServer主要負責響應用戶I/O請求,向HDFS文件系統中讀寫數據,是HBase中最核心的模塊。HRegionServer內部管理了一系列HRegion對象,每個HRegion對應了Table中的一個Region。HRegion由多個HStore組成,每個HStore對應了Table中的一個ColumnFamily的存儲。可以看出每個ColumnFamily其實就是一個集中的存儲單元,因此最好將具備共同I/O特性的列放在一個ColumnFamily中,這樣能保證讀寫的高效性。
HStore存儲是HBase存儲的核心,由兩部分組成:MemStore和StoreFile。
MemStore是Sorted Memory Buffer,用戶寫入的數據首先會放入MemStore中,當MemStore滿了以後會緩衝(flush)成一個StoreFile(底層實現是HFile),當StoreFile文件數量增長到一定閾值,會觸發Compact操作,將多個StoreFiles合併成一個StoreFile,在合併過程中會進行版本合併和數據刪除,因此可以看出HBase其實只有增加數據,所有的更新和刪除操作都是在後續的Compact過程中進行的,這使得用戶的寫操作只要進入記憶體中就可以立即返回,保證了HBaseI/O的高性能。StoreFiles在觸發Compact操作後,會逐步形成越來越大的StoreFile,當單個StoreFile大小超過一定閾值後,會觸發Split操作,同時把當前Region分裂成2個Region,父Region會下線,新分裂的2個子個子Region會被HMaster分配到相應的HRegionServer上,使得原先1個Region的壓力得以分流到2個Region上。
每個HRegionServer中都有一個HLog對象,HLog是一個實現WriteAheadLog的類,在每次用戶操作寫入MemStore的同時,也會寫一份數據到HLog文件中,HLog文件定期會滾動出新,並刪除舊的文件(已持久化到StoreFile中的數據)。在HRegionServer意外終止後,HMaster會通過ZooKeeper感知到,首先處理遺留的HLog文件,將其中不同Region的Log數據進行拆分,分別放到相應Region的目錄下,然後再將失效的Region重新分配,領取到這些Region的HRegionServer在載入Region的過程中,會發現有歷史HLog需要處理,因此會將HLog中的數據回放到MemStore中,然後緩衝(flush)到StoreFiles,完成數據恢復。
本博客所有內容來源於網路、書籍、和各類手冊。
內容均為非盈利,旨為方便查詢、總結備份、開源分享。
部分轉載內容均有註明出處,如有侵權請告知,馬上刪除。


