
如何合理地估算線程池大小? 這個問題雖然看起來很小,卻並不那麼容易回答。大家如果有更好的方法歡迎賜教,先來一個天真的估算方法:假設要求一個系統的TPS(Transaction Per Second或者Task Per Second)至少為20,然後假設每個Transaction由一個線程完成,繼續假 ...
如何合理地估算線程池大小?
這個問題雖然看起來很小,卻並不那麼容易回答。大家如果有更好的方法歡迎賜教,先來一個天真的估算方法:假設要求一個系統的TPS(Transaction Per Second或者Task Per Second)至少為20,然後假設每個Transaction由一個線程完成,繼續假設平均每個線程處理一個Transaction的時間為4s。那麼問題轉化為:如何設計線程池大小,使得可以在1s內處理完20個Transaction?
計算過程很簡單,每個線程的處理能力為0.25TPS,那麼要達到20TPS,顯然需要20/0.25=80個線程。
很顯然這個估算方法很天真,因為它沒有考慮到CPU數目。一般伺服器的CPU核數為16或者32,如果有80個線程,那麼肯定會帶來太多不必要的線程上下文切換開銷。
再來第二種簡單的但不知是否可行的方法(N為CPU總核數):
- 如果是CPU密集型應用,則線程池大小設置為N+1
- 如果是IO密集型應用,則線程池大小設置為2N+1
如果一臺伺服器上只部署這一個應用並且只有這一個線程池,那麼這種估算或許合理,具體還需自行測試驗證。
接下來在這個文檔:伺服器性能IO優化 中發現一個估算公式:
最佳線程數目 = ((線程等待時間+線程CPU時間)/線程CPU時間 )* CPU數目
比如平均每個線程CPU運行時間為0.5s,而線程等待時間(非CPU運行時間,比如IO)為1.5s,CPU核心數為8,那麼根據上面這個公式估算得到:((0.5+1.5)/0.5)*8=32。這個公式進一步轉化為:
最佳線程數目 = (線程等待時間與線程CPU時間之比 + 1)* CPU數目
可以得出一個結論:線程等待時間所占比例越高,需要越多線程。線程CPU時間所占比例越高,需要越少線程。
上一種估算方法也和這個結論相合。
一個系統最快的部分是CPU,所以決定一個系統吞吐量上限的是CPU。增強CPU處理能力,可以提高系統吞吐量上限。但根據短板效應,真實的系統吞吐量並不能單純根據CPU來計算。那要提高系統吞吐量,就需要從“系統短板”(比如網路延遲、IO)著手:
- 儘量提高短板操作的並行化比率,比如多線程下載技術
- 增強短板能力,比如用NIO替代IO
第一條可以聯繫到Amdahl定律,這條定律定義了串列系統並行化後的加速比計算公式:
加速比=優化前系統耗時 / 優化後系統耗時
加速比越大,表明系統並行化的優化效果越好。Addahl定律還給出了系統並行度、CPU數目和加速比的關係,加速比為Speedup,系統串列化比率(指串列執行代碼所占比率)為F,CPU數目為N:
Speedup <= 1 / (F + (1-F)/N)
當N足夠大時,串列化比率F越小,加速比Speedup越大。
寫到這裡,我突然冒出一個問題。
是否使用線程池就一定比使用單線程高效呢?
答案是否定的,比如Redis就是單線程的,但它卻非常高效,基本操作都能達到十萬量級/s。從線程這個角度來看,部分原因在於:
- 多線程帶來線程上下文切換開銷,單線程就沒有這種開銷
- 鎖
當然“Redis很快”更本質的原因在於:Redis基本都是記憶體操作,這種情況下單線程可以很高效地利用CPU。而多線程適用場景一般是:存在相當比例的IO和網路操作。
所以即使有上面的簡單估算方法,也許看似合理,但實際上也未必合理,都需要結合系統真實情況(比如是IO密集型或者是CPU密集型或者是純記憶體操作)和硬體環境(CPU、記憶體、硬碟讀寫速度、網路狀況等)來不斷嘗試達到一個符合實際的合理估算值。
最後來一個“Dark Magic”估算方法(因為我暫時還沒有搞懂它的原理),使用下麵的類:
1 package threadpool; 2 3 import java.math.BigDecimal; 4 import java.math.RoundingMode; 5 import java.util.Timer; 6 import java.util.TimerTask; 7 import java.util.concurrent.BlockingQueue; 8 9 /** 10 * A class that calculates the optimal thread pool boundaries. It takes the 11 * desired target utilization and the desired work queue memory consumption as 12 * input and retuns thread count and work queue capacity. 13 * 14 * @author Niklas Schlimm 15 */ 16 public abstract class PoolSizeCalculator { 17 18 /** 19 * The sample queue size to calculate the size of a single {@link Runnable} 20 * element. 21 */ 22 private final int SAMPLE_QUEUE_SIZE = 1000; 23 24 /** 25 * Accuracy of test run. It must finish within 20ms of the testTime 26 * otherwise we retry the test. This could be configurable. 27 */ 28 private final int EPSYLON = 20; 29 30 /** 31 * Control variable for the CPU time investigation. 32 */ 33 private volatile boolean expired; 34 35 /** 36 * Time (millis) of the test run in the CPU time calculation. 37 */ 38 private final long testtime = 3000; 39 40 /** 41 * Calculates the boundaries of a thread pool for a given {@link Runnable}. 42 * 43 * @param targetUtilization the desired utilization of the CPUs (0 <= targetUtilization <= * 1) * @param targetQueueSizeBytes * the desired maximum work queue size of the thread pool (bytes) 44 */ 45 protected void calculateBoundaries(BigDecimal targetUtilization, BigDecimal targetQueueSizeBytes) { 46 calculateOptimalCapacity(targetQueueSizeBytes); 47 Runnable task = creatTask(); 48 start(task); 49 start(task); // warm up phase 50 long cputime = getCurrentThreadCPUTime(); 51 start(task); // test intervall 52 cputime = getCurrentThreadCPUTime() - cputime; 53 long waittime = (testtime * 1000000) - cputime; 54 calculateOptimalThreadCount(cputime, waittime, targetUtilization); 55 } 56 57 private void calculateOptimalCapacity(BigDecimal targetQueueSizeBytes) { 58 long mem = calculateMemoryUsage(); 59 BigDecimal queueCapacity = targetQueueSizeBytes.divide(new BigDecimal(mem), 60 RoundingMode.HALF_UP); 61 System.out.println("Target queue memory usage (bytes): " 62 + targetQueueSizeBytes); 63 System.out.println("createTask() produced " + creatTask().getClass().getName() + " which took " + mem + " bytes in a queue"); 64 System.out.println("Formula: " + targetQueueSizeBytes + " / " + mem); 65 System.out.println("* Recommended queue capacity (bytes): " + queueCapacity); 66 } 67 68 /** 69 * Brian Goetz' optimal thread count formula, see 'Java Concurrency in 70 * * Practice' (chapter 8.2) * 71 * * @param cpu 72 * * cpu time consumed by considered task 73 * * @param wait 74 * * wait time of considered task 75 * * @param targetUtilization 76 * * target utilization of the system 77 */ 78 private void calculateOptimalThreadCount(long cpu, long wait, 79 BigDecimal targetUtilization) { 80 BigDecimal waitTime = new BigDecimal(wait); 81 BigDecimal computeTime = new BigDecimal(cpu); 82 BigDecimal numberOfCPU = new BigDecimal(Runtime.getRuntime() 83 .availableProcessors()); 84 BigDecimal optimalthreadcount = numberOfCPU.multiply(targetUtilization) 85 .multiply(new BigDecimal(1).add(waitTime.divide(computeTime, 86 RoundingMode.HALF_UP))); 87 System.out.println("Number of CPU: " + numberOfCPU); 88 System.out.println("Target utilization: " + targetUtilization); 89 System.out.println("Elapsed time (nanos): " + (testtime * 1000000)); 90 System.out.println("Compute time (nanos): " + cpu); 91 System.out.println("Wait time (nanos): " + wait); 92 System.out.println("Formula: " + numberOfCPU + " * " 93 + targetUtilization + " * (1 + " + waitTime + " / " 94 + computeTime + ")"); 95 System.out.println("* Optimal thread count: " + optimalthreadcount); 96 } 97 98 /** 99 * * Runs the {@link Runnable} over a period defined in {@link #testtime}. 100 * * Based on Heinz Kabbutz' ideas 101 * * (http://www.javaspecialists.eu/archive/Issue124.html). 102 * * 103 * * @param task 104 * * the runnable under investigation 105 */ 106 public void start(Runnable task) { 107 long start = 0; 108 int runs = 0; 109 do { 110 if (++runs > 5) { 111 throw new IllegalStateException("Test not accurate"); 112 } 113 expired = false; 114 start = System.currentTimeMillis(); 115 Timer timer = new Timer(); 116 timer.schedule(new TimerTask() { 117 public void run() { 118 expired = true; 119 } 120 }, testtime); 121 while (!expired) { 122 task.run(); 123 } 124 start = System.currentTimeMillis() - start; 125 timer.cancel(); 126 } while (Math.abs(start - testtime) > EPSYLON); 127 collectGarbage(3); 128 } 129 130 private void collectGarbage(int times) { 131 for (int i = 0; i < times; i++) { 132 System.gc(); 133 try { 134 Thread.sleep(10); 135 } catch (InterruptedException e) { 136 Thread.currentThread().interrupt(); 137 break; 138 } 139 } 140 } 141 142 /** 143 * Calculates the memory usage of a single element in a work queue. Based on 144 * Heinz Kabbutz' ideas 145 * (http://www.javaspecialists.eu/archive/Issue029.html). 146 * 147 * @return memory usage of a single {@link Runnable} element in the thread 148 * pools work queue 149 */ 150 public long calculateMemoryUsage() { 151 BlockingQueue queue = createWorkQueue(); 152 for (int i = 0; i < SAMPLE_QUEUE_SIZE; i++) { 153 queue.add(creatTask()); 154 } 155 156 long mem0 = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory(); 157 long mem1 = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory(); 158 159 queue = null; 160 161 collectGarbage(15); 162 163 mem0 = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory(); 164 queue = createWorkQueue(); 165 166 for (int i = 0; i < SAMPLE_QUEUE_SIZE; i++) { 167 queue.add(creatTask()); 168 } 169 170 collectGarbage(15); 171 172 mem1 = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory(); 173 174 return (mem1 - mem0) / SAMPLE_QUEUE_SIZE; 175 } 176 177 /** 178 * Create your runnable task here. 179 * 180 * @return an instance of your runnable task under investigation 181 */ 182 protected abstract Runnable creatTask(); 183 184 /** 185 * Return an instance of the queue used in the thread pool. 186 * 187 * @return queue instance 188 */ 189 protected abstract BlockingQueue createWorkQueue(); 190 191 /** 192 * Calculate current cpu time. Various frameworks may be used here, 193 * depending on the operating system in use. (e.g. 194 * http://www.hyperic.com/products/sigar). The more accurate the CPU time 195 * measurement, the more accurate the results for thread count boundaries. 196 * 197 * @return current cpu time of current thread 198 */ 199 protected abstract long getCurrentThreadCPUTime(); 200 201 }
然後自己繼承這個抽象類並實現它的三個抽象方法,比如下麵是我寫的一個示例(任務是請求網路數據),其中我指定期望CPU利用率為1.0(即100%),任務隊列總大小不超過100,000位元組:
1 package threadpool; 2 3 import java.io.BufferedReader; 4 import java.io.IOException; 5 import java.io.InputStreamReader; 6 import java.lang.management.ManagementFactory; 7 import java.math.BigDecimal; 8 import java.net.HttpURLConnection; 9 import java.net.URL; 10 import java.util.concurrent.BlockingQueue; 11 import java.util.concurrent.LinkedBlockingQueue; 12 13 public class SimplePoolSizeCaculatorImpl extends PoolSizeCalculator { 14 15 @Override 16 protected Runnable creatTask() { 17 return new AsyncIOTask(); 18 } 19 20 @Override 21 protected BlockingQueue createWorkQueue() { 22 return new LinkedBlockingQueue(1000); 23 } 24 25 @Override 26 protected long getCurrentThreadCPUTime() { 27 return ManagementFactory.getThreadMXBean().getCurrentThreadCpuTime(); 28 } 29 30 public static void main(String[] args) { 31 PoolSizeCalculator poolSizeCalculator = new SimplePoolSizeCaculatorImpl(); 32 poolSizeCalculator.calculateBoundaries(new BigDecimal(1.0), new BigDecimal(100000)); 33 } 34 35 } 36 37 /** 38 * 自定義的非同步IO任務 39 * @author Will 40 * 41 */ 42 class AsyncIOTask implements Runnable { 43 44 public void run() { 45 HttpURLConnection connection = null; 46 BufferedReader reader = null; 47 try { 48 String getURL = "http://baidu.com"; 49 URL getUrl = new URL(getURL); 50 51 connection = (HttpURLConnection) getUrl.openConnection(); 52 connection.connect(); 53 reader = new BufferedReader(new InputStreamReader( 54 connection.getInputStream())); 55 56 String line; 57 while ((line = reader.readLine()) != null) { 58 // empty loop 59 } 60 } 61 62 catch (IOException e) { 63 64 } finally { 65 if(reader != null) { 66 try { 67 reader.close(); 68 } 69 catch(Exception e) { 70 71 } 72 } 73 connection.disconnect(); 74 } 75 76 } 77 78 }
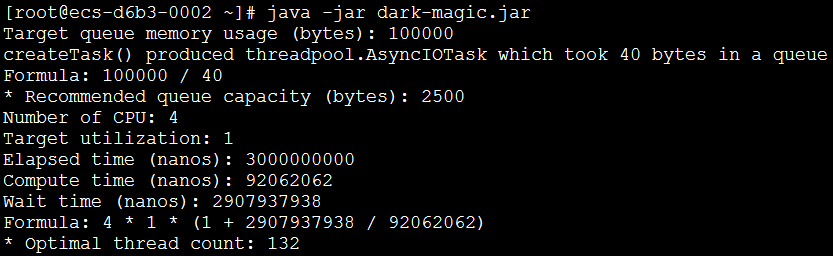
得到如下輸出:
Target queue memory usage (bytes): 100000 createTask() produced threadpool.AsyncIOTask which took 40 bytes in a queue Formula: 100000 / 40 * Recommended queue capacity (bytes): 2500 Number of CPU: 8 Target utilization: 1 Elapsed time (nanos): 3000000000 Compute time (nanos): 280801800 Wait time (nanos): 2719198200 Formula: 8 * 1 * (1 + 2719198200 / 280801800) * Optimal thread count: 88
推薦的任務隊列大小為2500,線程數為88。依次為依據,我們就可以構造這樣一個線程池:
ThreadPoolExecutor pool = new ThreadPoolExecutor(88, 88, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(2500));
可以將這個文件打包成可執行的jar文件,這樣就可以拷貝到測試/正式環境上執行。
1 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 2 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 3 <modelVersion>4.0.0</modelVersion> 4 5 <groupId>threadpool</groupId> 6 <artifactId>dark-magic</artifactId> 7 <version>1.0-SNAPSHOT</version> 8 <packaging>jar</packaging> 9 10 <name>dark_magic</name> 11 <url>http://maven.apache.org</url> 12 13 <properties> 14 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> 15 </properties> 16 17 <dependencies> 18 19 </dependencies> 20 21 <build> 22 <finalName>dark-magic</finalName> 23 24 <plugins> 25 <plugin> 26 <artifactId>maven-assembly-plugin</artifactId> 27 <configuration> 28 <appendAssemblyId>false</appendAssemblyId> 29 <descriptorRefs> 30 <descriptorRef>jar-with-dependencies</descriptorRef> 31 </descriptorRefs> 32 <archive> 33 <manifest> 34 <!-- 此處指定main方法入口的class --> 35 <mainClass>threadpool.SimplePoolSizeCaculatorImpl</mainClass> 36 </manifest> 37 </archive> 38 </configuration> 39 <executions> 40 <execution> 41 <id>make-assembly</id> 42 <phase>package</phase> 43 <goals> 44 <goal>assembly</goal> 45 </goals> 46 </execution> 47 </executions> 48 </plugin> 49 </plugins> 50 </build> 51 </project>
轉載:
http://ifeve.com/how-to-calculate-threadpool-size/
http://www.importnew.com/17384.html
https://www.cnblogs.com/cherish010/p/8334952.html


