
當實際項目上線到生產環境中,難以避免一些意外情況,如數據丟失、伺服器停機等。對於系統的搜索服務來說,當遇到停機的情況意味著在停機這段時間內,用戶都不能通過搜索的相關功能進行訪問數據,停機意味著將這一段時間內的數據服務完全停止。如果項目是互聯網項目依賴於用戶數量,這將嚴重影響用戶訪問和用戶的產品體驗。 ...
當實際項目上線到生產環境中,難以避免一些意外情況,如數據丟失、伺服器停機等。對於系統的搜索服務來說,當遇到停機的情況意味著在停機這段時間內,用戶都不能通過搜索的相關功能進行訪問數據,停機意味著將這一段時間內的數據服務完全停止。如果項目是互聯網項目依賴於用戶數量,這將嚴重影響用戶訪問和用戶的產品體驗。
針對於這種實際情況,在實際的項目開發維護過程中,如果系統使用的大數據平臺是Cloudera公司是CDH,可以考慮使用Cloudera Search來進行數據的增量備份和數據恢復工作。Cloudera Search是Cloudera公司基於Apache的開源項目Solr發佈的一個搜索服務,安裝非常簡單,通過Cloudera Manager的管理頁面就可以進行一鍵式安裝,本文將對使用Cloudera Search進行各個應用場景做災備的方案一一介紹。
1.HDFS - HDFS
一般情況下,一個大數據項目中所有用到的原始數據都會存儲HDFS中(Hive和HBase存儲也是基於HDFS存儲數據)。對HDFS做災備和數據恢復最直接的方式是在源HDFS集群和備份HDFS集群之間設置數據定期增量更新,例如時間Cloudera BDR工具,基礎數據備份之後可以選擇使用MapReduce Indexer或者Spark Indexer對備份HDFS集群中的同步過來的原始數據建立索引並追加到和備份HDFS集群同一集群中的正常運行的Solr服務中。這樣在原始集群故障後,可以從原始集群的Solr服務切換到備份集群的Solr服務,從而達到不影響用戶使用搜索服務的需求。
這種情況存在一個問題就是我的原始集群中數據有新產生的數據,還沒來得及同步到備份HDFS集群中,這時發生原始集群發生故障會切換到備用集群會導致數據缺失,導致這種情況有兩個方面的原因,一是設置的在兩個集群間增量同步數據的傳輸頻率,這也是主要因素。二是使用MapReduce或者Spark建立索引並加到Solr中需要多久的時間。
下圖是一個具體的例子,文件A存儲在HDFS中,通過Cloudera BDR工具進行數據文件的定期備份,將它備份到數據備份用的HDFS集群中。在兩個集群中使用Spark或者MapReduce對新文件建立索引,並將新建立的索引添加到各自集群中的Solr服務里提供搜索功能。
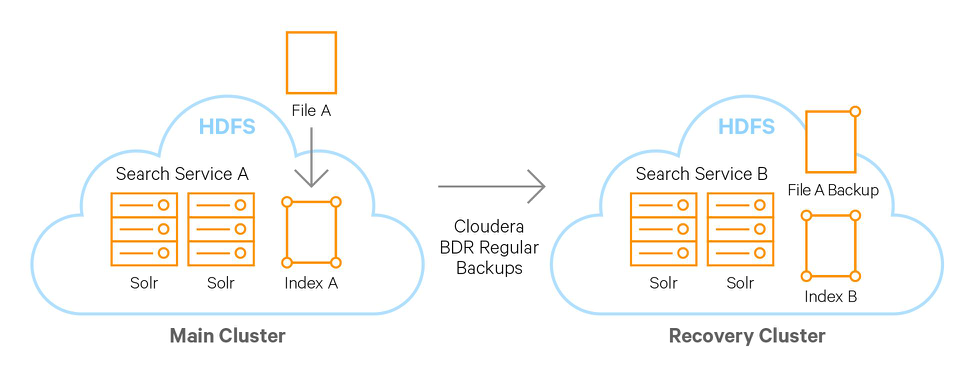
圖1
2.HBase - HBase
如果數據存儲在HBase表中,並且希望可以對這些數據進行搜索,這種場景使用Solr集成HBase,可以實現大數據量快速檢索,替代HBase中的列值過濾器,並且HBase在Rowkey設計中也會更加容易,只需要保證每一行的唯一性就可以。
從災備的角度來看,HBase本身就具備將數據備份到恢復集群的能力,所以對搜索HBase的搜索服務需要做的就是及時同步數據到恢復集群,併在恢復集群的Solr服務上建立索引。HBase集群間的數據同步取決於兩個HBase集群之間的網路。
用戶每次寫入到HBase的數據同步到HBase恢復集群(可以使用HBase自帶的hbase.replication配置項實現),集成使用Cloudera Search和同集群Solr服務實時監聽建立索引的機制相同。同理在HBase恢復集群也需要實時監聽數據變換,為新數據建立索引,可以採用HBase協處理器或者Cloudera的Key-Value Store Indexer組件實現。
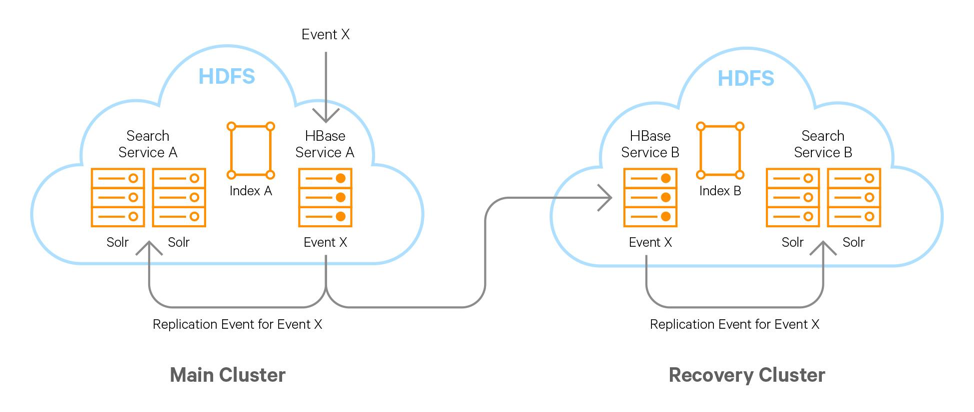
圖 2
3.Solr - Solr
搜索服務災備一方面是對基礎數據進行同步和備份,一方面則是對索引進行備份,Cloudera Search 實現了索引備份的方案,使用索引備份工具可以高效的將索引文件複製到其他位置,例如S3或ADLS,但是在做災備的場景下,你的恢復集群很可能是一個HDFS集群,在需要切換備用集群時,需要將索引載入到備用集群的Cloudera Search 服務中。只要索引文件載入到了Solr中,就可以為用戶提供搜索服務。
備份的操作是基於Solr的快照功能,Cloudera Search允許為當前Solr中的所有數據做快照。之後使用hadoop distcp命令將索引和相關的元數據文件複製到別處(其他的HDFS集群)。
由於創建快照是對數據和元數據的保留,可能不是完整的副本,因此在這種情況下兩個集群數據同步的延遲取決於備用集群上的可以Solr服務需要多長時間將索引副本載入到集群的Cloudera Search服務中。
總結來說備份Solr數據的步驟如下:
a) 原始集群創建快照
b) 準備要導出的快照
c) 將快照導出到本地集群或者遠程集群(hadoop distcp命令)
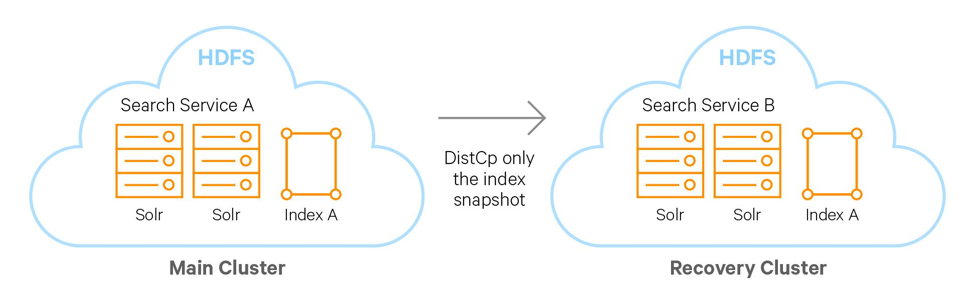
圖 3
個人建議:
項目上線後建議定期進行系統的基礎數據備份和索引數據備份。原始數據計算使用過後建議全量保留,這是為了避免後續想要更改數據計算方式卻沒有原始數據的情況。

